


开放世界导航新范式!港科大成果突破:基于LLM规划的长序列目标导航任务
- 2025-07-26 10:56:00

在应对现实世界中长距离、多目标、动态变化的任务时,如何真正做到开放词汇目标导航,尤其是让四足机器人听懂任务指令、感知目标并灵活导航,完成一系列连贯动作?仍是一道待解的难题。
今天介绍的这篇来自香港科技大学(广州)团队的工作LOVON,就提出了一个面向现实复杂环境的完整方案——
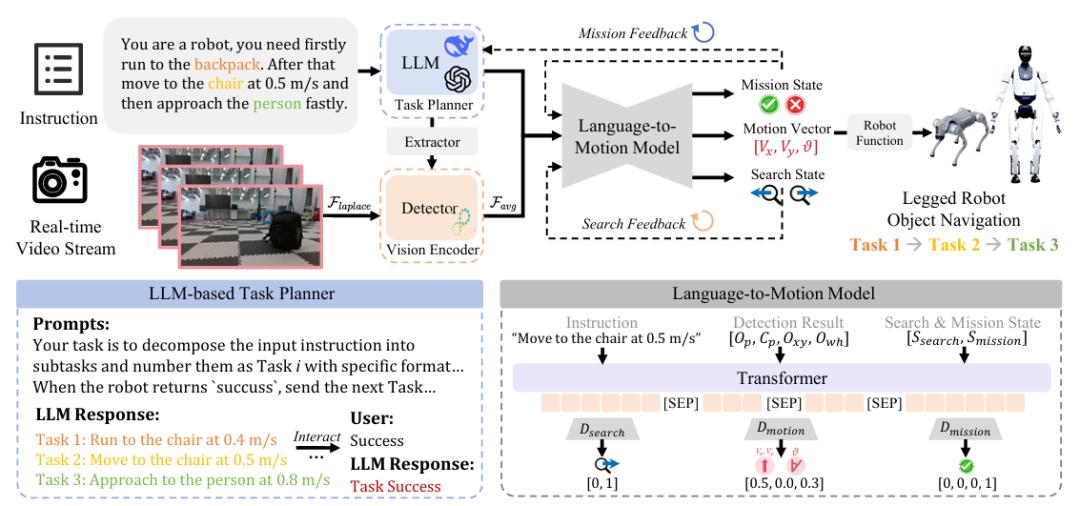
它整合了大语言模型的任务规划能力、开放词汇视觉模型的感知能力,以及Transformer驱动的语言到运动映射模型(L2MM)。在多个真实四足机器人平台上成功实现了“看懂任务、找对目标、走对路线”的全过程闭环执行。
小编认为,LOVON的出现不仅补足了当前LLM机器人研究中“行动执行不足”的短板,也为开放场景下的多模态机器人导航指明了新方向。

▲任务演示:“先靠近背包,然后缓慢走向椅子,最后快速接近人。”©️【深蓝具身智能】编译

技术解析
如何让机器人听得懂任务、找得到目标、走得对路径?
LOVON 的核心目标就是解决以上的三个难题。为此,它融合了三类关键技术能力:语言理解、多模态感知、动态控制决策。
整个系统从自然语言输入出发,依次完成任务拆解、视觉感知、运动决策三个阶段,并在真实机器人上形成了一个高效稳健的执行闭环。
▲LOVON 系统流程总览©️【深蓝具身智能】编译
接下来,小编将从以下三个核心模块入手,拆解 LOVON 系统是如何实现这一整套“从理解到行动”的路径的:
基于大语言模型的高层任务规划器;
支持开放词汇的目标感知系统;
语言-感知-控制融合的动作生成模块(L2MM)
基于大语言模型的高层任务规划器
LOVON 的第一步,是实现高层任务的语言理解与调度(先“听懂人话”)。
与传统导航系统只能接受固定模板指令不同,LOVON 能理解结构复杂、顺序灵活的自然语言命令,比如:
“先靠近背包,然后缓慢走向椅子,最后快速接近人。”
对于这种多目标、多条件的指令,LOVON 采用 LLM 作为任务规划器,它的职责是:
解析语言意图:识别出任务涉及的多个子目标(如背包、椅子、人);
生成结构化任务序列:将每一步目标、速度要求等内容转化为标准指令;
基于执行状态进行动态调度:只有前一个子任务完成,系统才会向下发起新任务。
这个模块看似“只是调度”,但它其实完成了两项能力的结合:语言推理 + 任务记忆与切换。
这让 LOVON 不只是理解“去哪”,还知道“何时该去哪里”,实现类人化的任务执行流程。
支持开放词汇的目标感知系统
听懂任务之后,机器人必须看得见目标,而不是只能识别固定类(比如 COCO-80)。
LOVON 采用了一个基于 YOLO-World 的视觉系统,并加入了自研的 Instruction-Object Extractor(IOE)模块,构建起了完整的开放词汇感知流程:
目标类自动推理:IOE 会从指令中提取目标类别。例如用户说“靠近背包”,IOE 会映射出检测类为“backpack”,并提供嵌入表示作为 YOLO 检测模块的输入;
基于图文匹配的检测机制:检测器可以根据语义 embedding 匹配当前图像中是否存在该类别目标;
图像清晰度评估机制:系统使用拉普拉斯方差(Laplacian Variance)判断当前图像是否模糊,并在视觉输入模糊时拒绝发起检测,防止运动模糊干扰判断。

▲对于图像清晰度的模糊判断可视化,可以看到从1-9图像从模糊变为清晰,如果在模糊的图像中执行视觉任务,势必对系统会产生极大地影响,这一点作者在后续的实验部分也进行了充分的证明©️【深蓝具身智能】编译
这一模块的优势在于:目标不需要预定义、也不需要训练时固定类别集,只要语言中提到了,它就会尝试找出来。
同时 IOE 模块也能规避一词多义问题,比如“go to the left bag”不会错认为“left person”。
语言-感知-控制融合的动作生成模块
这个过程的目的,是让机器人从视觉语言中学会“怎么走”。
这也是LOVON 中最关键的闭环执行部分——L2MM 模块,全称为 Language-to-Motion Mapper,用于将当前语言任务 + 感知状态,转化为运动控制指令。
它的核心是一种多输入的 Transformer 架构,输入包括:
当前子任务的语言指令;
检测目标的位置、置信度;
上一任务执行状态(成功/未完成);
当前搜索状态(如正在原地旋转寻找目标);
然后输出三个关键控制变量:
(1)运动控制向量(linear velocity vx、vy,角速度 θ);
(2)任务完成判别(判断是否完成当前子任务);
(3)视觉搜索方向判别(判断若目标丢失,是应左转搜索还是右转搜索)。
这种结构使得 L2MM 实际上承担了一个“翻译器”的职责:它把「我要去哪 + 我看到什么」翻译成「我下一步该怎么走」。
同时,由于它具备任务状态判断能力,还能在目标消失时启动视觉搜索逻辑,避免卡死。
这一点弥补了很多 LLM+控制结合系统的核心短板:大模型能说人话,但控制指令接不住。
而 LOVON 的 L2MM 直接打通了这一步。
▲凭借出色的模块化设计,LOVON可以适应不同的具身平台,视频演示了LOVON在多个具身智能体上的运行效果©️【深蓝具身智能】编译

实验设计与关键结果分析
LOVON 的实验聚焦于两个核心问题:
在现实环境中,系统是否具备稳定识别与控制能力?尤其是在目标丢失、图像模糊、任务切换等高压场景下;
与已有系统相比,LOVON 是否真正带来了可落地的性能提升?
为此,论文在多个真实部署场景中设计了任务链条,并与代表性方法进行了对比评估。
▲真实环境中多目标任务追踪实验演示©️【深蓝具身智能】编译
多目标任务追踪
实验设计了多种 多目标语言导航任务,例如:
“慢慢走向包,再靠近椅子,最后以最快速度靠近人。”
系统需要做到:
(1)对目标顺序有明确记忆;
(2)每步都能判断是否完成当前任务;
(3)并在完成前一步后自动过渡到下一个目标。
结果表明:
LOVON 成功率明显高于基线方法(如 TrackVLA 和 w/o LLM 版本);
系统不会因为目标检测失败或状态识别不准导致卡住;
多目标执行中,L2MM 能准确判断当前子任务完成与否,平均错误率低于 7%。
▲LOVON 对运动模糊、遮挡和动态状态变化等视觉干扰具有很强的鲁棒性。场景中的雨伞被遮挡,导致视觉效果受到影响。LOVON 能够从这种干扰中恢复,并继续接近目标。©️【深蓝具身智能】编译
这说明其语言-控制闭环确实能应对非结构化多目标任务,并在“边走边思考”中形成稳定执行流。
模糊图像过滤机制
在真实部署中,机器人运动会导致摄像头图像产生模糊。LOVON 引入了基于拉普拉斯方差的图像清晰度评估模块,用以判断当前图像是否可信。
论文构造了对比实验:
在有图像模糊过滤机制的系统中,任务完成率提升了约 18.7%;
无过滤时,机器人经常在模糊帧下误判目标已丢失,错误执行“旋转搜索”等行为。

▲不同速度下,不同目标所使用的阈值和合格帧率比例。如图所示,结合作者提出的移动平均滤波(MAF)的方法将合格帧率提高了 25%©️【深蓝具身智能】编译
这个模块虽然轻量,但在真实场景中是提升系统鲁棒性的关键补丁,有效阻止了由视觉质量波动引发的 cascade error。
与 SOTA 系统对比:LOVON 的全流程优势体现在哪?
论文对比了三类 baseline 系统,并在多个目标、多语言任务中,LOVON 显著优于 baseline,尤其在:
目标搜索时间(平均缩短 26.5%);
目标接近精度(更准确地停在目标附近);
任务中断次数(控制策略更稳定,切换更顺畅);
更关键的是,LOVON 并非靠训练时的数据拟合,而是依靠结构化模块设计 + L2MM 的泛化能力,实现了跨目标、跨语言任务的一致表现。

▲与SOTA方法的对比实验结果©️【深蓝具身智能】编译

总结
从这篇LOVON的系统设计中我们可以看到,当「让机器人听懂你在说什么」成为可能时,接下来的挑战其实是——让它能在复杂环境中「说到做到」。
LOVON 并不是简单地用 LLM 控任务、用 YOLO 识目标、用 RL 控身体,而是构建了一个有明确信息流动、决策闭环的系统结构:
语言任务有规划、目标识别能泛化、运动控制能感知目标变化并实时调整。
而且这些能力不止停留在实验室里的“视频效果”,而是真正落地在真实四足机器人平台上,完成多目标任务。
编辑|阿豹
审编|具身君
参考文献:
论文名称:LOVON: Legged Open-Vocabulary Object
论文作者:Daojie Peng, Jiahang Cao, Qiang Zhang, Jun Ma
论文地址:https://arxiv.org/pdf/2507.06747
项目地址:https://daojiepeng.github.io/LOVON/
 【深蓝具身智能读者群】-参观机器人:
【深蓝具身智能读者群】-参观机器人:
我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇



点击❤收藏并推荐本文
 扫码添加微信
扫码添加微信

- 点赞 (0)
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊







