登顶 ICCV 2025!清华大学提出统一具身智能导航框架:主动感知、三维视觉-语言理解

现有 3D 视觉 - 语言模型(3D-VL)虽能处理静态场景的物体定位,但依赖完整 3D 重建,难以应对动态、部分可见的真实环境;而强化学习方法虽能探索,却样本效率低、泛化性差。
核心难题在于:
如何从原始视觉数据中实时学习空间语义表征?
如何让 "找物体" 和 "探未知" 协同优化?
如何用大规模数据训练出稳健的探索策略?
为解决这一问题,清华大学、北京通用人工智能研究院BIGAI、北理工、北航提出了将:
「主动感知与三维视觉-语言学习」相结合的具身导航框架——MTU3D。
在本文中,小编首先将简单对系统进行介绍,然后对系统进行核心功能代码的分析,以帮助大家理解整个项目的代码思路。
我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?

方法介绍
系统介绍
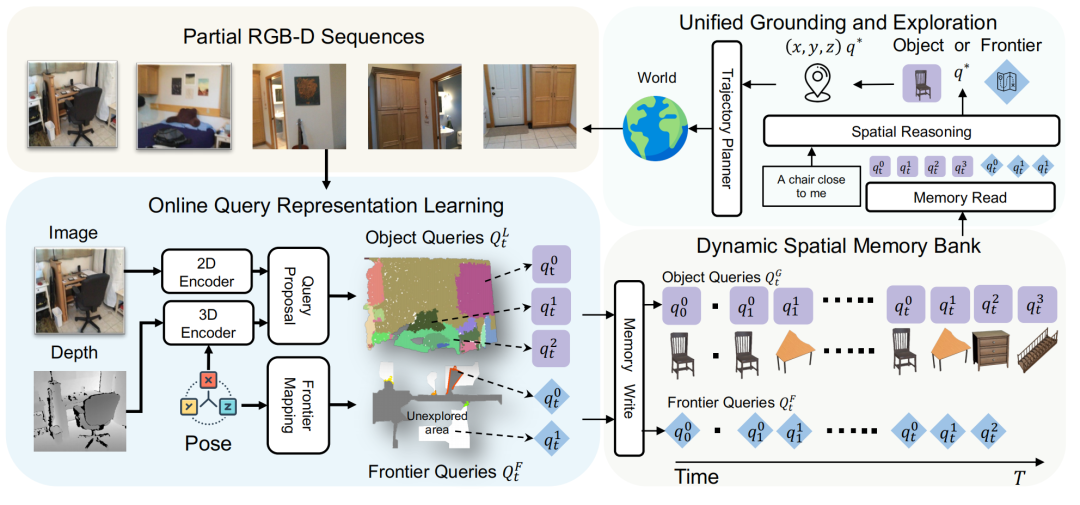
如上图所示是MTU3D的流程展示,小编将对它进行概括说明:
(1)首先,整个MTU3D系统输入是一定时间范围内的RGB-D序列(对应于Partial RGB-D Sequences部分)
(2)将这些RGB-D序列输入到模型中进行局部查询(对应于Online Query Representation Learning部分),可以得到:
(3)将这些集合通过Memory Write聚合到记忆仓库中(对应于Dynamic Spatial Memory Bank部分)。
(4)在使用时,用户通过给定一条自然语言指令(对应于图片中的“A chair close to me”),模型将读取记忆仓库(对应于Memory Read部分),然后进行全局查询得到图中的。
基于再决定是靠近物体还是导航到某个Frontier的位置上(通过Trajectory Planner生成移动的轨迹路线)。
功能分析(代码实现)
(1) 从Online Query Representation Learning的部分可以知道,MTU3D的输入包括RGB和depth,这两部分。
对RGB分别使用DINO提取2D特征、FastSAM提取分割索引;
然后将它们进行池化操作,同时对depth先进行点云投影;
再基于UNet提取3D特征,同样结合2D分割索引进行池化操作。
上述操作设计的实现过程,如下:
def average_pooling_by_group(img_feat, idxs, grid_idxs, valid_cnt): # 获取最大组区域ID group_ids = torch.from_numpy(idxs).cuda() grid = torch.from_numpy(grid_idxs).to(img_feat.dtype).cuda() num_groups = torch.max(group_ids) + 1 img_feat = img_feat.unsqueeze(0) feat = F.grid_sample(img_feat, grid[:valid_cnt].unsqueeze(1).unsqueeze(0), mode='bilinear', align_corners=True) feat = feat.squeeze(0).squeeze(-1).transpose(0, 1).contiguous() feat = torch.cat([feat, torch.zeros(20000-valid_cnt, feat.size(1), device=feat.device, dtype=feat.dtype)], dim=0) # 创建池化张量 pooled_matrix = torch.zeros(num_groups, feat.size(1), device=feat.device, dtype=feat.dtype) # 根据组区域ID将特征矩阵分散到池化矩阵中 pooled_matrix.index_add_(0, group_ids, feat) # 计算每个组中的元素数量 group_counts = torch.bincount(group_ids, minlength=num_groups).float() group_counts = torch.where(group_counts == 0, torch.ones_like(group_counts), group_counts) # 计算平均值 pooled_matrix /= group_counts.unsqueeze(1) return pooled_matrix.cpu().numpy()
class PQ3DModel: def __init__(self, stage1_dir, stage2_dir, min_decision_num=None): processor = AutoImageProcessor.from_pretrained('facebook/dinov2-large') model = AutoModel.from_pretrained('facebook/dinov2-large').cuda() model.eval() img_backbone = [processor, model] self.image_backbone = img_backbone mask_generator = FastSAM('./hm3d-online/FastSAM/FastSAM-x.pt') self.mask_generator = mask_generator ... def decision(self, color_list, depth_list, agent_state_list, frontier_waypoints, sentence, decision_num, image_feat=None): ... processer = self.image_backbone[0] image_backbone = self.image_backbone[1] img_feats_list = [] for i in range(0, len(color_list), batch_size): batch_colors = color_list[i:i + batch_size] image_inputs = processer(batch_colors, return_tensors="pt").to(image_backbone.device) with torch.no_grad(): outputs = image_backbone(**image_inputs) img_feats = outputs.last_hidden_state.detach() img_feats = img_feats[:, 1:, :] img_feats = img_feats.reshape(-1, 16, 16, FEAT_DIM) img_feats = img_feats.permute(0, 3, 1, 2) img_feats_list.append(img_feats) img_feats = torch.cat(img_feats_list, dim=0) torch.cuda.empty_cache() everything_result = self.mask_generator(color_list, device='cuda', retina_masks=True, imgsz=640, conf=0.1, iou=0.9,) ... for idx, (color, depth, agent_state) in enumerate(zip(color_list, depth_list, agent_state_list)): ... pooled_feat = average_pooling_by_group(img_feat, group_ids, grid_idx, valid_cnt) ....
def convert_from_uvd(u, v, depth, intr, pose): z = depth / 1000.0 u = np.expand_dims(u, axis=0) v = np.expand_dims(v, axis=0) padding = np.ones_like(u)
uv = np.concatenate([u,v,-padding], axis=0) * np.expand_dims(z,axis=0) xyz = (np.linalg.inv(intr[:3,:3]) @ uv) xyz = np.concatenate([xyz,padding], axis=0) xyz = pose @ xyz xyz[:3,:] /= xyz[3,:] return xyz[:3, :].T
@MODEL_REGISTRY.register()class EmbodiedPQ3DInstSegModel(BaseModel): def __init__(self, cfg): ... for input in self.inputs: encoder = input + '_encoder' setattr(self, encoder, build_module_by_name(cfg.model.get(encoder))) ... def forward(self, data_dict): ...
@VISION_REGISTRY.register()class PCDMask3DSegLevelEncoder(nn.Module): def __init__(self, cfg, backbone_kwargs, hidden_size, hlevels, freeze_backbone=False, dropout=0.1): super().__init__() self.context = torch.no_grad if freeze_backbone else nullcontext self.backbone = getattr(mask3d_models, "Res16UNet34C")(**backbone_kwargs) self.scatter_fn = scatter_mean self.sizes = self.backbone.PLANES[-5:] self.hlevels = hlevels + [4] self.feat_proj_list = nn.ModuleList([ nn.Sequential( nn.Linear(self.sizes[hlevel], hidden_size), nn.LayerNorm(hidden_size), nn.Dropout(dropout) ) for hlevel in self.hlevels]) self.pooltr = ME.MinkowskiPoolingTranspose(kernel_size=2, stride=2, dilation=1, dimension=3) def upsampling(self, feat, hlevel): n_pooltr = 4 - hlevel for _ in range(n_pooltr): feat = self.pooltr(feat) return feat
def forward(self, x, point2segment, max_seg): with self.context(): pcds_features, aux = self.backbone(x) multi_scale_seg_feats = [] for hlevel, feat_proj in zip(self.hlevels, self.feat_proj_list): feat = aux[hlevel] feat = self.upsampling(feat, hlevel) assert feat.shape[0] == pcds_features.shape[0] batch_feat = [self.scatter_fn(f, p2s, dim=0, dim_size=max_seg) for f, p2s in zip(feat.decomposed_features, point2segment)] batch_feat = torch.stack(batch_feat) batch_feat = feat_proj(batch_feat) multi_scale_seg_feats.append(batch_feat)
return multi_scale_seg_feats
(2) 生成局部查询,并更新到记忆仓库
class PQ3DModel: def __init__(self, stage1_dir, stage2_dir, min_decision_num=None): ... self.representation_manager = RepresentationManager() ... def decision(self, color_list, depth_list, agent_state_list, frontier_waypoints, sentence, decision_num, image_feat=None): ... ... self.representation_manager.merge(pred_dict_list) ...
(3)从Unified Grounding and Exploration部分可以知道,该过程是基于视觉-语言进行探索(Vision-Language-Exploration, VLE)的过程。
用户发送一条指令,机器人解析了指令后,结合看到的视觉信息和记忆仓库生成决策,最后基于决策信息生成探索轨迹;
上述操作设计的实现过程,如下:
class PQ3DModel: def __init__(self, stage1_dir, stage2_dir, min_decision_num=None): ... config_path = "../configs/embodied-pq3d-final" config_name = "embodied_vle.yaml" GlobalHydra.instance().clear() hydra.initialize(config_path=config_path) cfg = hydra.compose(config_name=config_name) self.pq3d_stage2 = Query3DVLE(cfg) self.pq3d_stage2.load_state_dict(torch.load(os.path.join(stage2_dir, 'pytorch_model.bin'), map_location='cpu'), strict=False) self.pq3d_stage2.eval() self.pq3d_stage2.cuda() self.tokenizer = AutoTokenizer.from_pretrained("openai/clip-vit-large-patch14") ... def decision(self, color_list, depth_list, agent_state_list, frontier_waypoints, sentence, decision_num, image_feat=None): ... encoded_input = self.tokenizer([sentence], add_special_tokens=True, truncation=True) tokenized_txt = encoded_input.input_ids[0] prompt = torch.FloatTensor(tokenized_txt) prompt_pad_masks = torch.ones((len(tokenized_txt))).bool() prompt_type = PromptType.TXT data_dict = { ... 'prompt': prompt, 'prompt_pad_masks': prompt_pad_masks, 'prompt_type': prompt_type, } if image_feat is not None: data_dict['prompt'] = image_feat data_dict['prompt_pad_masks'] = torch.ones((1)).bool() data_dict['prompt_type'] = PromptType.IMAGE batch.append(data_dict) batch = default_collate(batch) batch = batch_to_cuda(batch) with torch.no_grad(): stage2_output_data_dict = self.pq3d_stage2(batch)
@MODEL_REGISTRY.register()class Query3DVLE(BaseModel): ... def prompt_encoder(self, data_dict): prompt = data_dict['prompt'] prompt_pad_masks = data_dict['prompt_pad_masks'] prompt_type = data_dict['prompt_type'] prompt_feat = torch.zeros(prompt_pad_masks.shape + (self.hidden_size,), device=prompt_pad_masks.device) for type in self.prompt_types: idx = prompt_type == getattr(PromptType, type.upper()) if idx.sum() == 0: continue input = [] for i in range(len(prompt)): if idx[i]: input.append(prompt[i]) mask = prompt_pad_masks[idx] if type == 'txt': input = pad_sequence(input, pad=0) encoder = self.txt_encoder feat = encoder(input.long(), mask) elif type == 'loc': loc_prompts = input[:, :self.dim_loc] if self.dim_loc > 3: feat = self.coord_encoder(loc_prompts[:, :3]).unsqueeze(1) + self.box_encoder(loc_prompts[:, 3:6]).unsqueeze(1) else: feat = self.coord_encoder(loc_prompts[:, :3].unsqueeze(1), input_range=[data_dict['coord_min'][idx], data_dict['coord_max'][idx]]) mask[:, 1:] = False elif type == 'image': img_prompts = torch.stack(input).unsqueeze(1) feat = self.image_encoder(img_prompts) mask[:, 1:] = False else: raise NotImplementedError(f'{type} is not implemented') prompt_feat[idx] = feat prompt_pad_masks[idx] = mask return prompt_feat, prompt_pad_masks.logical_not()
@MODEL_REGISTRY.register()class Query3DVLE(BaseModel): def __init__(self, cfg): ... self.unified_encoder = build_module_by_name(self.cfg.model.unified_encoder) ... def forward(self, data_dict): ... query, predictions_score, predictions_class, predictions_mask, predictions_box = self.unified_encoder(input_dict, pairwise_locs, mask_head_partial) ...
class PQ3DModel: def decision(self, color_list, depth_list, agent_state_list, frontier_waypoints, sentence, decision_num, image_feat=None): ... with torch.no_grad(): stage2_output_data_dict = self.pq3d_stage2(batch) ... return target_position, is_object_decision
以goat-nav.py为例子try: if goal_type == 'image': target_position, is_final_decision = pq3d_model.decision(color_list, depth_list, agent_state_list, frontier_waypoints, sentence, decision_num, goal_image_feat) else: target_position, is_final_decision = pq3d_model.decision(color_list, depth_list, agent_state_list, frontier_waypoints, sentence, decision_num)except Exception as e: print(f"Error in decision making, episode_id: {cur_episode['episode_id']}, scene_id: {scene_id}, {e}") sys.exit(1) breakdecision_num += 1if not is_final_decision: visited_frontier_set.add(tuple(np.round(target_position, 1)))agent_island = path_finder.get_island(agent_state.position)target_on_navmesh = path_finder.snap_point(point=target_position, island_index=agent_island)follower = habitat_sim.GreedyGeodesicFollower(path_finder, agent, forward_key="move_forward", left_key="turn_left", right_key="turn_right") action_list = follower.find_path(target_on_navmesh)...

实验
实验设置
评估的数据集:在4类任务基准数据集上进行评估,包括开放性词汇导航数据集(HM3D-OVON)、多模态终身导航数据集(GOAT-Bench)、任务导向序列导航数据集(SG3D)、主动具身问答数据集(A-EQA)。
评估指标:主要采用成功率(SR)、成功加权路径长度(SPL),并且SG3D额外使用任务一致性成功率(t-SR)、A-EQA使用LLM匹配分数(LLM-SR)和探索效率分数(LLM-SPL)。
用于对比的基线:包括强化学习(RL)、模块化方法(如GOAT、VLFM)、视频基方法(如Uni-Navid)等。
实现细节:分三阶段训练(低级感知、VLE预训练、任务微调),使用4块 NVIDIA A100 GPU训练了约164小时,仿真环境采用Stretch机器人模型,支持前进、转向等动作。
结果说明
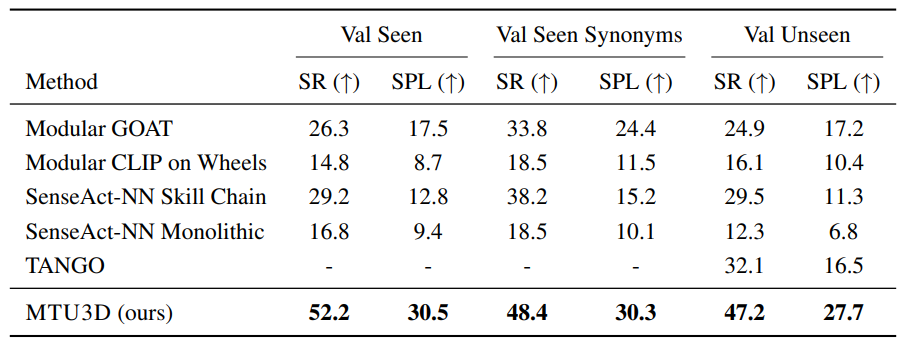
开放词汇导航(HM3D-OVON):MTU3D在Val Unseen场景中SR达40.8%,显著优于RL(18.6%)和Uni-Navid(39.5%)基线方法,展现MTU3D的强泛化能力。
多模态终身导航(GOAT-Bench):MTU3D在Val Seen场景中SR达 52.2%,SPL达 30.5%,远超模块化GOAT(SR 26.3%)和RL方法(SR 29.2%),验证了MTU3D终身空间记忆的有效性。
任务导向序列导航(SG3D):MTU3D的s-SR达23.8%,t-SR达8.0%,优于Embodied Video Agent(s-SR 14.7%),体现了MTU3D对多步骤任务的强理解能力。

▲SG3D-Nav上的顺序任务导航结果
主动具身问答(A-EQA):MTU3D结合GPT-4V时LLM-SR达44.2%,LLM-SPL达 37.0%,远超纯GPT-4V(LLM-SPL 7.5%),说明MTU3D可以高效提升问答效率。
▲在A-EQA上的具身问答结果
实验结论
通过完整的实验证明,VLE预训练可提升各任务SR、空间记忆库显著提升终身导航性能、MTU3D模型实时性良好。
真实世界测试(如家庭、走廊等场景)验证MTU3D在无微调情况下的有效性,克服Sim-to-Real迁移挑战。
综上,实验表明MTU3D在多模态导航与问答任务中性能优于现有方法。
总结
MTU3D通过空间记忆库和语义指导进行空间探索,效率高于目前的探索导航方案。但是在HM3D-OVON部分场景中,MTU3D的SPL低于Uni-Navid,且在SG3D中整体成功率偏低,实时性也存在瓶颈。
因此,在未来,MTU3D可考虑进一步优化路径规划来提升SPL,扩大真实数据多样性以适应动态环境,并且深度优化与LLM的融合探索策略。
编辑|木木伞
审编|具身君
Ref
论文标题:Move to Understand a 3D Scene: Bridging Visual Grounding and Exploration for Efficient and Versatile Embodied Navigation
论文作者:Ziyu Zhu, Xilin Wang, Yixuan Li, Zhuofan Zhang, Xiaojian Ma, Yixin Chen, et al.
论文地址:https://www.arxiv.org/pdf/2507.04047
项目主页:https://mtu3d.github.io/
 【深蓝具身智能读者群】-参观机器人:欢迎各位粉丝朋友,加入深蓝具身君的读者群,具体参观开放日时间将在群内陆续通知。
【深蓝具身智能读者群】-参观机器人:欢迎各位粉丝朋友,加入深蓝具身君的读者群,具体参观开放日时间将在群内陆续通知。我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇
【深蓝具身智能】的原创内容均由作者团队倾注个人心血制作而成,希望各位遵守原创规则珍惜作者们的劳动成果,转载添加下方微信进行授权,发文时务必注明出自【深蓝具身智能】微信公众号,否则侵权必究⚠️⚠️
投稿|寻求合作|研究工作推荐:SL13126828869










 扫码添加微信
扫码添加微信








