


克服VLA根本性缺陷!复旦&华为诺亚:首个4D时空预训练框架,精准对齐机器人与场景坐标系
- 2025-07-22 10:56:39

在机器人通过观察人类演示学习复杂操作任务的道路上,一个长期存在的“幽灵”始终挥之不去——当机器人面对不完整的观测数据时(例如机械臂底座被遮挡、视角受限或物体状态模糊),其动作预测会陷入混乱。
尽管DROID、RT-1、RT-2等大规模数据集已经积累了数十万小时的交互数据,但如何有效利用这些多样化的数据进行预训练仍然充满挑战。
复旦大学数据科学学院与华为诺亚方舟实验室的最新研究——4D-VLA,揭示了现有VLA模型的根本性缺陷,并提出了基于完整时空信息的解决方案:首次提出时空四维预训练框架,通过创新性地融合连续RGB-D输入的深度信息与时间维度,实现了机器人与场景坐标系的精准对齐。
我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?

现有VLA问题的本质
单帧输入的根本局限
在通过视觉信息远程指导机器人完成桌面操作任务时,若仅依赖一张静态照片,会面临严重的信息缺失问题。
照片里只能呈现桌面上的物体分布,却完全看不到机器人手臂的当前位置、朝向等关键操作信息;更重要的是,静态画面无法回溯之前的操作过程,也无法判断物体是否处于运动状态(比如是否正在被推动、是否有滑动趋势)。
正因如此,仅凭这张信息残缺的照片,要准确预测机器人该做出哪些动作来完成任务,几乎是不可能的。
以OpenVLA为代表的主流方法恰恰陷入了这个困境——仅使用单张RGB图像和文本指令作为输入来预测机器人动作。
这种简化的输入方式导致了下面提及的这两个严重的问题。
坐标系统混沌(Coordinate System Chaos)
如图1顶部所示,机器人的动作定义在其自身坐标系下,但当输入图像中看不到机器人本体时,模型就无法准确推断机器人的位置和朝向。研究者通过对DROID数据集的分析发现,67%的样本中机器人的基座是不可见的。
这意味着"向前移动10厘米"这样的指令,在不知道"前"是哪个方向的情况下变得毫无意义。
这种坐标系的不确定性直接导致了模型学习效率低下和泛化能力不足。
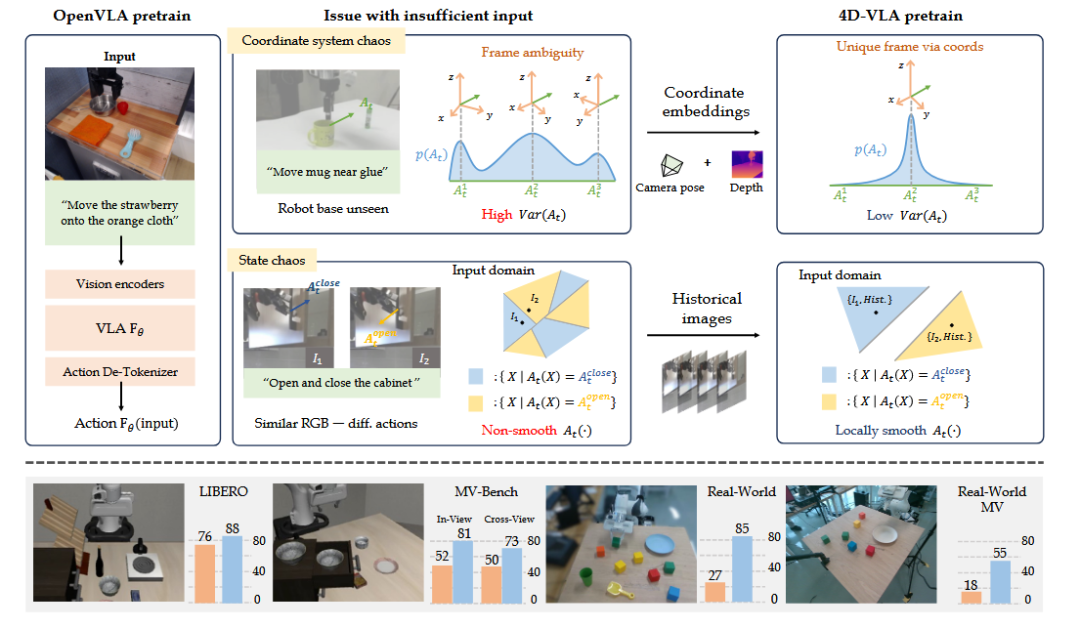
▲图1|顶部:作者团队的预训练设计理念强调,先前的方法在输入中往往缺乏准确动作推断所需的关键线索。这导致目标动作分布At(·)表现出高方差或非平滑性,从而对预训练性能产生负面影响。粗略分析显示,在DROID数据集中,67%的样本中机器人基座被遮挡,造成坐标系统混沌。底部:作者团队在仿真和真实世界机器人环境中验证了作者团队的方法,并报告了OpenVLA基线和作者团队的4D-VLA方法的性能表现。©️【深蓝具身智能】编译
状态混沌(State Chaos)
单帧图像缺乏时间维度信息带来了三类典型问题。
一是对称轨迹的方向歧义——就像看到钟摆在最低点的照片,无法判断它的摆动方向。
二是相似场景的不同动作——"打开柜子"和"关闭柜子"在某些中间状态下可能看起来完全相同。
三是缺失的上下文信息——不了解之前的动作序列,就无法准确判断当前应该执行什么动作。
混沌的数学本质

让机器人拥有"立体记忆"
核心理念:从2D到4D的维度提升
4D-VLA引入了完整的4D时空信息——3D空间信息加上时间维度。
通过RGB-D输入,机器人不仅能看到物体的位置,还能感知精确的距离信息。通过历史帧序列,机器人能够理解动作的连续性和任务的进展状态。

▲图2|作者团队的4D-VLA流程。作者团队的记忆库采样方法从连续的RGB-D输入中选择信息丰富的帧。带有3D坐标嵌入的视觉编码器生成空间感知标记,这些标记被融合成4D时空表示。结合文本标记,这些通过LLM处理,通过动作头解码动作。©️【深蓝具身智能】编译
如图2所示,4D-VLA的整体架构包含了Memory bank sampling模块用于选择信息丰富的历史帧,空间感知编码器生成包含3D坐标信息的视觉标记,以及融合时空信息的LLM Transformer。
这种设计给机器人装上了"立体眼睛"和"短期记忆",使其能够更准确地理解当前状况并做出合适的动作决策。
技术架构详解
空间感知视觉标记(Spatial-aware Visual Tokens)
4D-VLA不是简单地将深度作为额外的输入通道,而是将其转换为显式的3D坐标信息。对于每个像素,系统利用相机的内参K和外参[R|T],将深度值反投影到世界坐标系:
这些3D坐标通过可学习的位置嵌入进行编码,并与原始视觉特征融合,生成包含空间信息的视觉标记。这种设计让模型能够直接理解空间关系,而不是间接地从2D图像中推断。
记忆库采样(Memory Bank Sampling)
面对多帧历史信息,4D-VLA采用了基于内容相似度的智能采样策略。

▲图3|记忆库采样算法流程图。©️【深蓝具身智能】编译
如图2的Memory bank sampling过程所示,系统不是简单地均匀采样历史帧,而是通过滑动窗口动态评估帧间相似度,选择那些具有代表性且避免冗余的关键帧。这种机制类似于人类记忆——作者团队不会记住每一个瞬间,而是记住那些有区别性的关键时刻。
时间位置编码
由于采用非均匀采样,每一帧相对于当前帧的时间间隔各不相同。
模型通过相对时间位置编码来表达时间关系,使其能够区分"1秒前"和"0.1秒前"的不同时间尺度,从而更好地理解动作的时序特征。
训练策略:精确控制每个维度
4D-VLA的损失函数设计体现了对机器人控制精度的深刻理解:
其中平移损失确保位置预测准确,旋转损失保证方向预测正确,抓取损失L_g控制末端执行器状态。特别值得注意的是方向损失——由于机器人动作中的平移量通常较小,简单的L2损失可能忽视方向的重要性。通过显式的方向损失,模型被强制关注动作的方向性,即使位移很小。

实验
DROID数据集实验
研究团队在包含76,000个演示轨迹、约350小时交互数据的DROID数据集上进行预训练。
使用8块NVIDIA A6000 GPU,训练耗时约96小时。通过FlashAttention和bf16精度优化,4D-VLA在引入更复杂输入的同时,将训练成本控制在可接受范围内。
LIBERO基准测试
通过对表1的结果分析显示,4D-VLA在LIBERO仿真环境的所有任务上都取得了显著的性能提升:
LIBERO-SPATIAL(空间推理):88.9% vs 84.7%(OpenVLA),提升5.2%,证明了3D空间信息的价值;
LIBERO-OBJECT(物体理解):95.2% vs 92.5%(DiffusionPolicy),展现出对精细操作的掌控能力;
LIBERO-GOAL(目标达成):90.9% vs 84.6%(Octo),时序信息帮助理解任务目标;
LIBERO-LONG(长期任务):79.1% vs 53.7%(OpenVLA),提升25.4%。

▲表1|LIBERO上成功率的评估。粗体表示表现最佳的模型。作者团队的模型显著优于其他竞争对手,平均成功率比OpenVLA高12.1。†表示没有可用的标准差数据。©️【深蓝具身智能】编译
在长期任务上的巨大提升特别值得关注。这类任务需要机器人执行多个连续的子任务,对时序推理能力要求极高。如前文图1底部的性能对比所示,4D-VLA的优异表现充分证明了时空信息在复杂任务中的关键作用。
MV-Bench:专门的多视角评估
为评估模型的空间理解能力,研究团队创建了MV-Bench基准。该基准在270度前向范围内均匀采样6个训练视角和6个测试视角,如图3所示。

▲图4|作者团队的MV-Bench相机设置。作者团队选择6个不同的视角作为训练视图,并为所有LIBERO-SPATIAL任务渲染图像。新的推理视图放置在训练视图附近。为避免黑盒遮挡,排除了被遮挡区域的测试视图。©️【深蓝具身智能】编译
包含两个评估任务:
In-View(同视角):训练和测试使用相同视角 4D-VLA:81.0% vs OpenVLA:52.2%
Cross-View(跨视角):测试使用未见过的视角 4D-VLA:73.8% vs OpenVLA:50.5%

▲表2|MV-Bench上成功率的评估。Δ符号表示沿z轴与最近训练视点的角度偏差。©️【深蓝具身智能】编译
表2的结果表明,4D-VLA不仅在熟悉的视角下表现优秀,更重要的是展现出了强大的视角泛化能力。这对于实际部署至关重要,因为作者团队不能期望机器人总是从训练时的角度观察场景。
真实世界验证
图4展示了四个真实世界测试任务,充分验证了4D-VLA的实用性。

▲图5|作者团队的真实世界实验设置。这些设置旨在评估模型的空间泛化能力、对干扰物的鲁棒性、放置精度以及遵循指令的能力。每行展示了3帧执行快照。©️【深蓝具身智能】编译
任务1:空间泛化(90%成功率)
要求:从训练中未见过的位置放置黄色方块
挑战:需要理解相对空间关系,而非记忆固定位置
结果:4D-VLA展现出优秀的空间泛化能力
任务2:抗干扰鲁棒性(82.5%成功率)
要求:在杂乱背景下放置两个绿色方块
挑战:需要在视觉干扰中保持稳定性能
结果:深度信息帮助模型有效分割前景和背景
任务3:精确放置(90%成功率)
要求:将黄色方块精确叠放在红色方块上
挑战:需要毫米级的精度控制
结果:3D坐标信息显著提升了精度

任务4:指令跟随(80%成功率)
要求:按照颜色顺序拾取和放置物体
挑战:需要理解并记住复杂的指令序列
结果:时序信息帮助模型跟踪任务进度

消融实验
表3和表5的深入分析针对了各组件的贡献进行了实验分析:

▲表3|真实世界评估结果。作者团队通过添加预训练、坐标编码和通过记忆库采样选择的历史帧,逐步改进基础VLA。©️【深蓝具身智能】编译
仅预训练就将成功率从15.67%提升至47.00%(相比基础模型的巨大提升)
预训练+坐标编码:63.67%(证明3D信息的价值)
预训练+历史帧:65.88%(证明时序信息的价值)
完整模型:85.63%(各组件协同产生最佳效果)

▲图6|历史图像分析。较大的点表示较低的效率。©️【深蓝具身智能】编译
图5展示的历史信息分析进一步表明,窗口大小n对性能影响显著,而采样数量k的影响相对较小。Memory bank sampling策略通过减少冗余,即使在较小的k值下也能获得更好的性能。

4D信息关键的原因
从信息论角度理解
单张RGB图像包含的信息量有限,特别是关于3D结构和时间动态的信息严重不足。4D-VLA通过引入深度和时序信息,本质上是增加了输入信息的信息量,从而降低了输出的不确定性。这种信息增益直接转化为更准确、更稳定的动作预测。
从控制论角度理解
机器人控制是一个闭环反馈系统,需要准确的状态估计、明确的目标理解和合理的路径规划。4D-VLA通过3D空间信息改善了状态估计精度,通过时序信息增强了对任务进展的理解,从而在整个控制回路中提供了更可靠的决策基础。
从认知科学角度理解
人类执行操作任务时同样依赖立体视觉和短期记忆。作者团队通过双眼获得深度信息,通过记忆理解动作的连续性。4D-VLA的设计在某种程度上模仿了这种认知机制,为机器人提供了类似人类的感知和理解能力。

结语
输入设计不应满足于"够用",而要思考什么是"合适"的输入; 将机器人学的先验知识融入模型设计能够带来显著的性能提升; 完善的评估体系(如MV-Bench)对推动领域发展至关重要。
4D-VLA通过深入理解问题本质并设计针对性的解决方案,展示了比简单增加模型规模或数据量更有效的研究路径。随着具身智能技术的发展,机器人正在从执行固定程序的机器转变为能够理解、学习、适应的智能伙伴。4D-VLA代表了这一转变中的重要一步,它让机器人真正拥有了"看"和"记"的能力,为未来更复杂的人机协作奠定了基础。
编译|JeffreyJ
审编|具身君
Ref
论文标题:4D-VLA: Spatiotemporal Vision-Language-Action Pretraining with Cross-Scene Calibration
论文作者:Jiahui Zhang, Yurui Chen, Yueming Xu , Ze Huang, Yanpeng Zhou, Yu-Jie Yuan , Xinyue Cai, Guowei Huang, Xingyue Quan, Hang Xu, Li Zhang
项目主页:https://github.com/fudan-zvg/4D-VLA
 【深蓝具身智能读者群】-参观机器人:
【深蓝具身智能读者群】-参观机器人:
我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇



点击❤收藏并推荐本文

 扫码添加微信
扫码添加微信
- 点赞 0
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊







