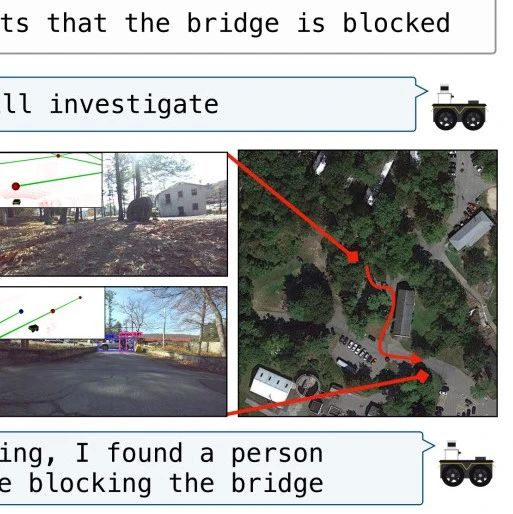
硬核焦点 | 半年,拿下7大顶会“大满贯”!盘点清华大学TEALab最新成绩单
- 2025-07-18 10:57:36


2025上半年发文一览!
清华大学具身智能实验室(Tsinghua Embodied AI Lab,简称 TEA Lab)隶属于清华大学交叉信息研究院,由在加州大学伯克利分校(BAIR)获得博士学位、曾在斯坦福视觉与学习实验室(SVL)从事博士后研究的许华哲教授创立并担任负责人。
TEA Lab 专注于具身智能、跨模态感知、机器人自主决策等前沿方向,目标是让机器人真正看懂世界、主动探索,并完成复杂多变的任务。
截至 2025 年上半年,清华大学 TEA 实验室已经在具身智能的多个核心话题上发表了15篇硬核论文(具体数量以TEAlab实验室网站上的为准)。涵盖了 ICRA、ICLR、ICML、RSS、CVPR、RAL等顶级会议。
本文就一起看看TEA Lab在过去半年里取得了哪些有意思的成果!
感兴趣的读者可以自行查阅论文原文深入阅读(见文末链接),也欢迎在评论区分享你关注的实验室成果。
本文盘点的 15 项工作涉及多个细分方向:
强化学习与可扩展性、数据高效与示范生成、灵巧操作与触觉、多任务通用操纵、基于大模型的推理、人机交互……
全面展示了实验室在推动机器人具身智能多维能力上的持续探索与突破。
接下来进行具体介绍。

强化学习与自主策略扩展
涉及如何让强化学习更可扩展、更稳定地解决高维控制问题,包括在四足机器人等具身平台上优化实际性能。
(ICML)MENTOR: Mixture-of-Experts Network with Task-Oriented Perturbation for Visual Reinforcement Learning
主要内容:
这项工作提出了 MENTOR,一种结合混合专家网络(MoE)和任务导向扰动的新型视觉强化学习方法。
通过替换传统 MLP 为 MoE 并引入任务相关的扰动采样,显著提高了样本效率和复杂任务的适应能力。在 DeepMind Control、Meta-World、Adroit 等仿真环境及真实机器人插销、理线、推球等任务上,MENTOR 都大幅超越现有方法。
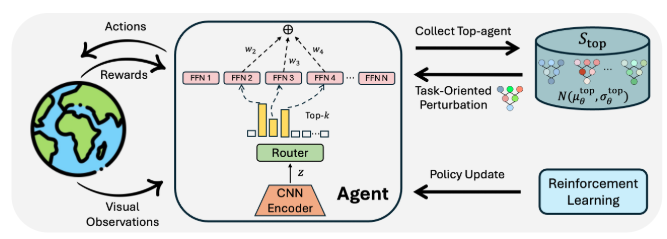
▲图1|Mentor方法框架©️【深蓝具身智能】编译
(ICML)A Forget-and-Grow Strategy for Deep Reinforcement Learning Scaling in Continuous Control
主要内容:
该论文提出了 FoG(Forget and Grow),从神经科学的遗忘与生长启发中获得灵感,通过引入经验回放衰减(逐步遗忘早期数据)和动态网络扩展(训练中增加参数)两大机制,有效缓解深度强化学习中的“首因偏置”问题。
实验证明 FoG 在四大连续控制基准的 40 多个任务上显著超越现有 SOTA 算法。

▲图2|FoG方法框架©️【深蓝具身智能】编译
论文地址:https://arxiv.org/pdf/2507.02712
(ICLR)Looking Backward: Retrospective Backward Synthesis for Goal-Conditioned GFlowNets
主要内容:
该研究针对稀疏奖励和轨迹覆盖不足的问题,提出了 RBS(Retrospective Backward Synthesis),通过在目标条件 GFlowNets 中合成反向轨迹,丰富训练数据的多样性和质量,有效缓解稀疏奖励带来的学习困难。实验证明该方法显著提升了采样效率,并在多个标准基准上超越现有强基线。

▲图3|RBS方法框架©️【深蓝具身智能】编译
论文地址:https://arxiv.org/pdf/2406.01150
代码地址:https://github.com/tinnerhrhe/Goal-Conditioned-GFN
(ICRA)Fine-Tuning Hard-to-Simulate Objectives for Quadruped Locomotion: A Case Study on Total Power Saving
主要内容:
该工作针对四足机器人行走中难以在仿真准确建模的能耗与噪声问题,提出了一个基于真实数据驱动的策略微调框架,用于优化这些硬仿真目标。
通过将真实能耗模型引入仿真训练,显著降低了四足机器人的总功耗(达到 24–28%),为在实际场景中持续改进提供了通用可迁移的方法。
▲视频1|该方法通过反复进行真实数据采集与仿真策略更新,来微调那些难以在仿真中精确建模的目标©️【深蓝具身智能】编译
论文地址:https://arxiv.org/pdf/2502.10956
项目地址:https://hard-to-sim.github.io/

关注在数据有限或示范稀缺的场景下,如何用生成式、单示范或跨机器人数据提高学习效率(模仿学习)。
(RSS)DemoGen: Synthetic Demonstration Generation for Data-Efficient Visuomotor Policy Learning
主要内容:
该研究提出了 DemoGen,一种低成本、完全基于合成的演示生成方法,仅需每个任务一次人类示范,即可通过三维点云编辑合成新场景,生成空间多样化的演示,从而显著提高视觉运动策略在不同物体配置下的泛化能力。
实验证明其在变形物体、灵巧手、双臂操作等复杂任务中同样有效,并具备抵抗干扰和避障的能力。

▲图4|DemoGen方法框架©️【深蓝具身智能】编译
论文地址:https://arxiv.org/pdf/2502.16932
项目地址:https://demo-generation.github.io/
相关阅读:举一反“万” | 2篇开创性工作解读:模仿学习,如何让机器人“操作”突破空间泛化瓶颈!
(ICLR)Stem-OB: Generalizable Visual Imitation Learning with Stem-Like Convergent Observation through Diffusion Inversion
主要内容:
视觉模仿学习方法在性能上表现突出,但在遇到光照、纹理等视觉输入扰动时往往缺乏泛化能力,限制了其在真实世界中的应用。本文提出的 Stem-Ob,利用预训练的图像扩散模型来抑制低层次视觉差异,同时保留高层次场景结构。
这一图像反演过程类似于将观测转化为一个共享的表示,使其他观测都由此衍生,去除了多余的细节。与数据增强方法不同,Stem-Ob 无需额外训练即可对各种未显式指定的外观变化具备鲁棒性。
该方法简单且有效,可以直接插入现有流程中使用。实验结果验证了该方法在仿真任务中的有效性,并在真实世界应用中相比最佳基线平均提高了 22.2% 的成功率。

▲图5|Stem-OB方法框架©️【深蓝具身智能】编译
论文地址:https://arxiv.org/pdf/2411.04919
项目地址:https://hukz18.github.io/Stem-Ob/
(ICRA,Spotlight (Top 5%))DenseMatcher: Learning 3D Semantic Correspondence for Category-Level Manipulation from a Single Demo
主要内容:
该工作提出了 DenseMatcher,一种可在野外对象间计算稠密 3D 语义对应的方法,通过多视角特征投影与 3D 网络提炼生成顶点特征,并利用 functional map 实现高效匹配。
DenseMatcher 在全新构建的多类别彩色网格数据集上显著超越现有基线(提升 43.5%),并在机器人操纵中实现了跨实例、跨类别的长时任务泛化,仅需单次示范,同时还能零样本地完成不同数字资产间的颜色迁移。

▲图6|DenseMatcher方法框架©️【深蓝具身智能】编译
论文地址:https://arxiv.org/pdf/2412.05268
项目地址:https://densematcher.github.io/
(ICLR)Robots Pre-Train Robots: Manipulation- Centric Robotic Representation from Large- Scale Robot Datasets
主要内容:
该研究首先发现,视觉表征的“操纵中心性”是预测下游机器人操作任务成功率的有力指标。
基于此,提出了 MCR(Manipulation Centric Representation),在 DROID 机器人数据集上同时利用图像和机器人本体状态/动作预训练视觉编码器,并引入多种对比损失以捕获任务动态信息。
实验表明,MCR 在 20 个操纵任务上超越最强基线 14.8%,在三项真实操作任务中成功率提升高达 76.9%。
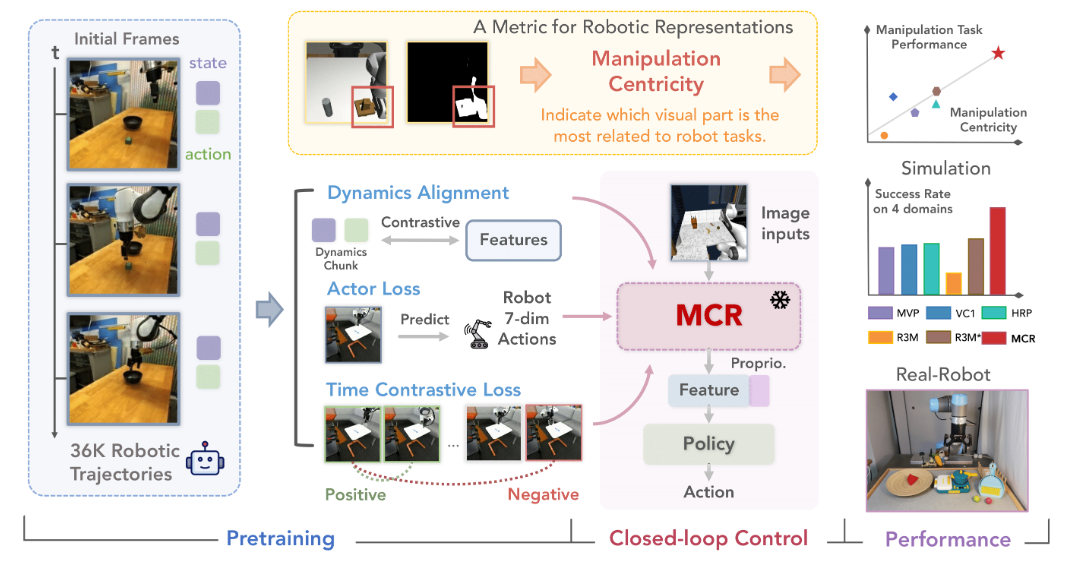
▲图7|MCR方法框架©️【深蓝具身智能】编译
论文地址:https://arxiv.org/pdf/2410.22325
项目地址:https://robots-pretrain-robots.github.io/

探索如何利用触觉反馈、视觉-触觉联合学习,让机器人在复杂接触场景中实现灵巧抓取与快速反应。
(RSS)DOGlove: Dexterous Manipulation with a Low-Cost Open-Source Haptic Force Feedback Glove
主要内容:
该研究提出了 DOGlove,一种低成本(<600 美元)、高精度、带触觉力反馈的灵巧手遥操作手套,具备 21 自由度动作捕捉、5 自由度多向力反馈及指尖振动反馈,可在无视觉条件下显著提升操作表现。
DOGlove 不仅实现了复杂接触任务中的沉浸式精准遥操作,还能用于采集演示数据以训练模仿学习策略。
▲视频2|DOGlove方法框架及演示©️【深蓝具身智能】编译
论文地址:https://arxiv.org/pdf/2502.07730
项目地址:https://do-glove.github.io/
(RSS)Reactive Diffusion Policy: Slow-Fast Visual-Tactile Policy Learning for Contact-Rich Manipulation
主要内容:
该工作提出了结合 TactAR(低成本 AR 实时触觉反馈遥操作系统)与 RDP(Reactive Diffusion Policy) 的新方法,用于学习接触丰富的操作技能。RDP 采用慢速潜空间扩散预测高层动作分块,配合快速触觉闭环控制,实现复杂轨迹与即时触觉响应统一,大幅提升了多项接触任务性能,并适配不同触觉/力传感器。

▲图8|RDP方法框架©️【深蓝具身智能】编译
论文地址:https://arxiv.org/pdf/2503.02881
项目地址:https://reactive-diffusion-policy.github.io/
(ICRA)Catch It! Learning to Catch in Flight with Mobile Dexterous Hands
主要内容:
该研究构建了由移动底盘、6 自由度机械臂和 12 自由度灵巧手组成的移动操纵系统。
提出两阶段强化学习框架,在仿真中高效训练全身控制策略以实现空中接物。通过抛掷条件随机化显著提高了策略对不同飞行轨迹的适应性,仿真抓取成功率达 80%,并能直接迁移到真实世界,实现接住人类抛掷的飞行物体。
▲视频3|Catch it方法Demo演示©️【深蓝具身智能】编译
论文地址:https://arxiv.org/pdf/2409.10319
项目地址https://mobile-dex-catch.github.io/

面向多物体协作、跨平台(如机械臂+移动底盘)操作,追求机器人更强的泛化和场景适应力。
(CVPR)Two by Two: Learning multi-task pairwise objects assembly for generalizable robot manipulation
主要内容:
该研究提出了 2BY2,首个面向日常物品配对装配的大规模注释数据集,涵盖插插头、插花、放吐司机等 18 类真实场景任务(共 517 组配对物体)。
在此基础上,提出了结合对称与装配约束的两步 SE(3) 位姿估计方法,在全部任务上刷新 SOTA,并通过机器人实验证明其对复杂 3D 装配任务的鲁棒性与泛化能力。
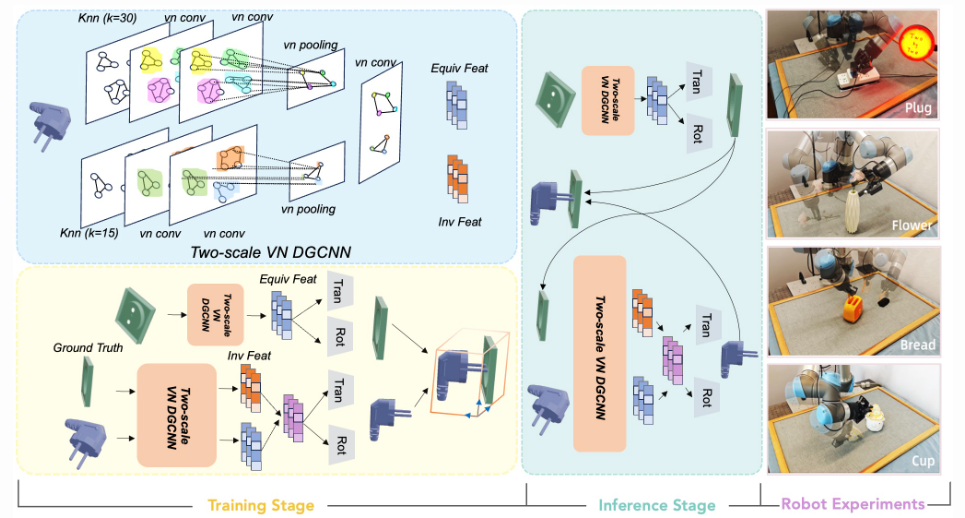
▲图9|2BY2方法框架©️【深蓝具身智能】编译
论文地址:https://arxiv.org/pdf/2504.06961
项目地址:https://tea-lab.github.io/TwoByTwo/
(RAL)DRoboDuet: A Framework Affording Mobile-Manipulation and Cross-Embodiment
主要内容:
该研究提出了 RoboDuet,一种采用双协作策略同时实现行走与操作的四足机器人全身控制框架,不仅能在大范围内完成 6D 位姿跟踪,还可零样本迁移到形态相似的其他四足平台。实验证明在复杂行走-操纵任务中,RoboDuet 成功率较基线提升 23%。
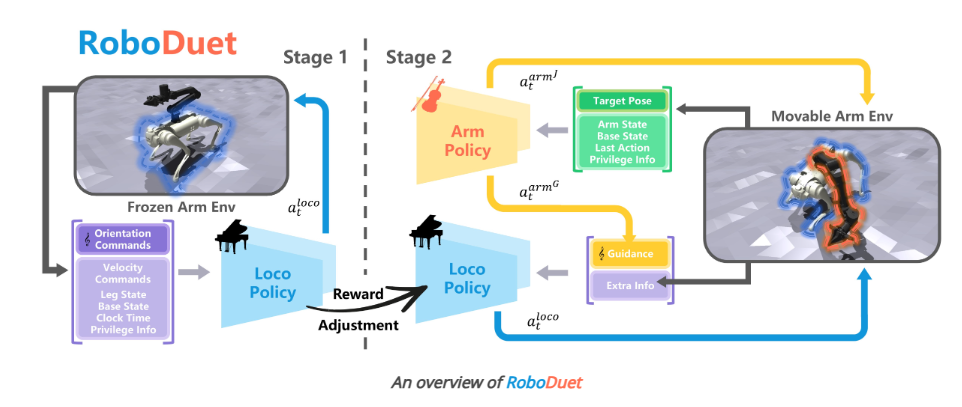
▲图10|RoboDuet方法框架©️【深蓝具身智能】编译
论文地址:https://arxiv.org/pdf/2403.17367v2
项目地址:https://locomanip-duet.github.io/

涉及具身情绪表达、动画机器人以及将大语言模型能力融入具身决策,用自然语言知识辅助任务达成。
(RSS)Morpheus: A Neural-driven Animatronic Face with Hybrid Actuation and Diverse Emotion Control
主要内容:
该工作提出了 Morpheus,一种结合刚性与柔性驱动的新型混合驱动仿生人脸,眼口采用刚性机构实现精确运动,鼻颊用绳索驱动以捕捉细微表情。
算法上引入自建模网络,自动学习面部表情与马达控制间的映射,并将语音输入转为情感驱动的面部控制信号,实现从句子中生成带细腻情绪差异的多样表情(如快乐、恐惧、厌恶、愤怒),超越以往系统的表现力。
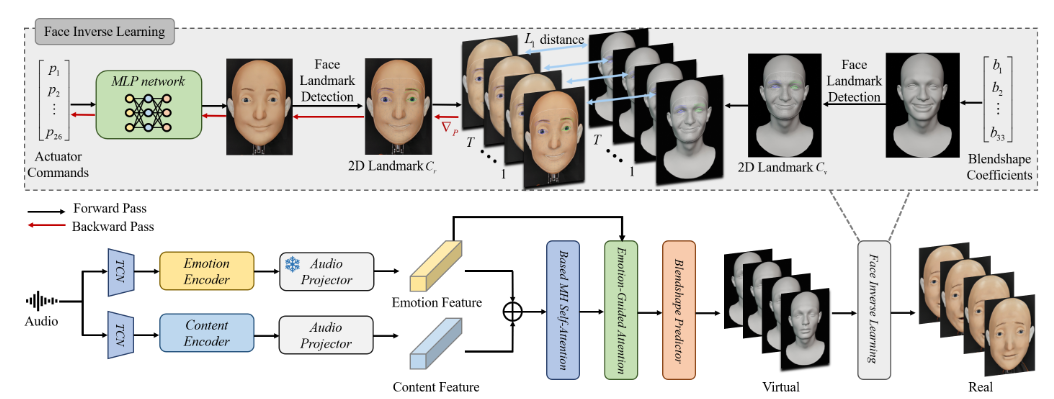
▲图11|Morpheus方法框架©️【深蓝具身智能】编译
论文地址:https://www.roboticsproceedings.org/rss21/p080.pdf
代码地址:https://github.com/ZZongzheng0918/Morpheus-Software
(NAACL)World Models with Hints of Large Language Models for Goal Achieving
主要内容:
该研究提出了 DLLM,一种融合大语言模型(LLM)提示的多模态模型式强化学习方法,通过在模型滚动中注入 LLM 提示子目标,并给予与提示一致的样本更高内在奖励,引导智能体在稀疏奖励、长时序任务中实现更有目的性的探索。实验证明在 HomeGrid、Crafter、Minecraft 等复杂环境中,DLLM 分别比最新方法提升 27.7%、21.1% 和 9.9%。

▲图12|DLLM方法框架©️【深蓝具身智能】编译
论文地址:https://arxiv.org/pdf/2406.07381

总结
回顾这半年来,TEALab在具身智能领域的研究足迹,从灵巧抓取到四足节能,从多模态模仿学习到语言模型赋能的智能探索——这15篇发表在顶会上的工作,正是他们朝着“让机器人真正看懂世界、主动探索,并完成复杂多变的任务”这一目标迈出的坚实步伐。
未来,具身智能将如何进一步演进?期待 TEA Lab 继续带来令人惊喜的突破!如果你对他们某一篇论文特别感兴趣,或是还想看哪些盘点、解读哪些实验室的最新工作,欢迎在评论区留言!
编辑|阿豹
审编|具身君
参考:
TEALab实验室官网:http://hxu.rocks/publication.html
 【深蓝具身智能读者群】-参观机器人:
【深蓝具身智能读者群】-参观机器人:
我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇



点击❤收藏并推荐本文
 扫码添加微信
扫码添加微信
- 点赞 0
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊