


硬核焦点 | 半年,拿下7大顶会“大满贯”!盘点清华大学TEALab最新成绩单

2025上半年发文一览!清华大学具身智能实验室(Tsinghua Embodied AI Lab,简称 TEA Lab)隶属于清华大学交叉信息研究院,由在加州大学伯克利分校(BAIR)获得博士学位、曾在斯坦福视觉与学习实验室(SVL)从事博士后研究的许华哲教授创立并担任负责人。TEA Lab 专注于具身智能、跨模态感知、机器人自主决策等前沿方向,目...
2025-07-18 10:57:36
浙江大学FAST-LAB实验室招聘科研助理(机器人打羽毛球、水上漂机器人项目)

浙江大学FAST-LAB实验室FAST-LAB实验室隶属于浙江大学智能系统与控制研究所(CSC),由许超、高飞两位教授领导。主要从事以下领域:• 自主系统(导航、控制、运动规划、感知、SLAM 等);• 科学机器学习(应用于湍流建模等);• 应用动力学与控制系统。 01“水上漂机器人”项目岗位-科研助理岗位职责:1. 以实习生身份加入课...
2025-07-17 10:56:00
3天搞定人形机器人VLN实战(含强化学习、自主避障等9个项目实战)

随着特斯拉Optimus、Figure等巨头加速商业化,人形机器人已成为科技竞争新赛道。但是人形机器人企业处于探索初期,各家公司都在竞相笼络研发人才,力争在这波风口上存活下来。很多人形机器人企业都在广泛招聘运动控制、强化学习、SLAM、视觉/雷达感知、VLA、C++等岗位的工程师。目前大部分伙伴只对人形机器人的理论和算法有...
2025-07-17 10:56:00
万字盘点|从近2年19项硬核工作看透【具身抓取】:硬件、感知、执行全面梳理!

机器人的抓取「简史」具身抓取(Embodied Grasping)作为机器人领域的核心技术之一,旨在真实或模拟环境里,借助感知、规划与执行能力,构建起机器人抓取物体的闭环流程。其目标就是让机器人如人类一般,灵活适配复杂场景并高效完成抓取任务。要实现具身抓取,究竟需要掌握哪些关键知识点呢?本文将从具身硬件平台、具身感...
2025-07-16 10:56:00
90%机器人项目栽在本地化?【盘点】3种经典部署路径,破解长距自主任务瓶颈!
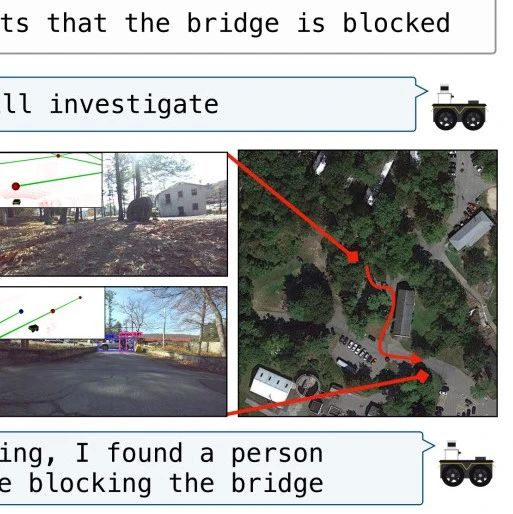
从语言理解到图像识别,从通用问答到代码生成,大模型正在全面刷新AI能力的边界。近年来,越来越多研究者尝试将这些模型嵌入机器人系统,希望赋予它们“听得懂人话、看得懂场景、动得了身子”的能力。这类尝试已在多个视觉-语言-动作(VLA)系统中初见成效:SayCan 和 Code-as-Policies 让机器人能将自然语言翻译为操作序列,...
2025-07-15 10:56:00
融资狂潮 | 4天6家20亿,滴滴首入具身智能,极智嘉上市引爆AMR赛道!

“追踪产业界的各项进展盘点新产品的惊艳亮相把握资本市场的新风向(如果有不全面的地方,欢迎大家补充,以期共同进步。PS:没时间看详细介绍的朋友,【要点速览】可供快速浏览。)我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?欢迎关...
2025-07-14 11:14:11
首个三系统VLA架构!复旦&上海创智学院:世界知识+世界模型+动作模型协同框架

现有的自回归式VLA方法大多关注的是静态场景信息的处理(比如物体识别和场景理解),而往往忽视了机器人执行任务时至关重要的动态因素,包括动作序列的时序关系、环境状态的实时变化以及任务执行过程中的反馈调整等。这些动态要素恰恰是机器人能否成功完成具身化任务的关键所在。复旦大学研究团队最新成果TriVLA —— 首个统...
2025-07-12 10:56:00
R2S2R颠覆性突破?机器人在模仿学习、强化学习训练中,精确操作涨幅最高达250%!

“如何让在虚拟世界中训练的机器人,在真实世界中同样出色地完成任务”?上面这个被称为"Real2Sim2Real"的挑战,一直是阻碍机器人大规模应用的关键瓶颈。来自极佳科技、中科院自动化所和北京大学的研究团队,针对这一难题,提出了首个实现机器人物理和视觉统一的大一统框架——EmbodieDreamer!本文将具体介绍,该框架是如何通...
2025-07-11 10:56:00
斯坦福新成果:用「4D时空坐标系」重构机器人视觉认知,攻克跨视角一致性难题!

「时间连贯性」与「跨视角几何一致性」兼顾在机器人操作任务中,生成具有时空一致性的视频对机器人理解环境动态至关重要。现有模型要么生成的视频画面闪烁、物体形变,要么不同视角下的空间位置错乱,严重制约了机器人在复杂场景中的规划与交互能力。为此,斯坦福大学&丰田研究院团队提出的几何感知4D视频生成模型,通过融...
2025-07-10 10:56:00
【票选】谁将率先上市?刚刚AMR仓储机器人第一股已出炉!不姓"智"、也不姓"宇"……

智元机器人“借壳”上市?(文末投票)上图源自,上纬新材在7月8日晚间披露的一则公告。图中的“智元恒岳”系智元新创及其核心管理团队共同出资设立的持股平台。而智元新创是智元机器人的母公司,基本意味着:——智元机器人以21亿元收购上纬新材63.62%股份。外界也推测智元机器人将选择借壳上纬新材(688585)而非独立IPO。(不...
2025-07-09 18:07:46
