


具身智能30年权力转移:谁杀死了PID?大模型正在吃掉传统控制论的午餐……
- 2025-07-23 10:56:00


从「小配角」到「占据主导型地位」,AI在机器人这条路上走了30年。
如果用一条清晰的技术演进路径来概括,可以把它划分为三个阶段:
以经典控制为主导的阶段,独占20年。彼时,AI仅仅是点缀其间的“小工具”,扮演着局部分类或简单识别的配角。
2010年起,此后10年间,深度学习席卷感知与操作领域。强化学习更是从虚拟棋盘上的博弈,大步迈向现实世界。
2020年至今,GPT、RT等大模型崛起,一个全新的范式——具身智能,从学术前沿走向“舞台中央”。
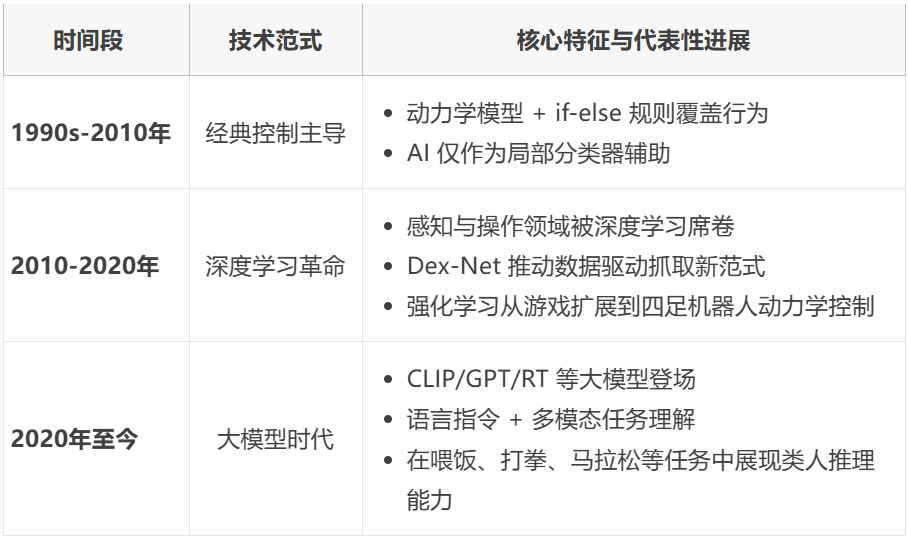
▲表1|AI+机器人的技术发展历程
本文,我们便来梳理梳理 AI 是如何一步步重塑机器人的控制逻辑与认知边界的。
同时也来聊一聊「机器人+AI」在未来发展道路上的显著困境。(正文开始)

▲图1|AI+机器人的进化路径及未来挑战,来自《Nature》旗下子刊Machine Intelligent©️【深蓝具身智能】编译

AI+机器人
里程碑式技术范式
过去三十年,AI 在机器人身上走过了一条从规则驱动到数据驱动、从单模态到多模态、从工程控制到类人推理的蜕变之路。
我们姑且将它“粗暴地”概括为三大阶段,其中每个阶段都带来了技术范式的跃迁,并留下了至今仍在深刻影响研究者的里程碑系统。
第一阶段(90s-2010):以经典控制为中心
这一时期,机器人的主要挑战是如何在受控环境下完成高精度动作。
当时什么PID、状态空间,那叫一个热火朝天。
AI?那时候的AI在机器人领域更多只是用作模式分类、简单路径规划,核心仍然依赖模型驱动的控制理论。
AI撑死了就是个在流水线边上打打下手、帮忙认认螺丝是A还是B的临时工分类器(地位堪比饮水机管理员)。
(事实上,人工神经网络早在上世纪就被提出,但当时算力有限,连解个高维优化都很吃力,所以这项技术在那时并未真正兴起。)
基于动力学的轨迹规划:
典型的六轴机械臂,需要先根据牛顿-欧拉方程精确建模,再在已知刚体参数、关节摩擦等条件下,通过运动规划 + PID 或 MPC 实现执行。
视觉更多只是用于定位:
比如基于 ArUco、棋盘格的手眼标定,抓取完全依赖 CAD(2006 年前后视觉 SLAM 才逐渐兴起)。
在那个时代,Modeled-based、Ruler-based Control、Teach and Repeat 是机器人圈最火的关键词(当然现在依旧有人研究,只不过相较于如今流行的具身智能端到端方法,已显得“冷门”甚至“成熟稳定”)。
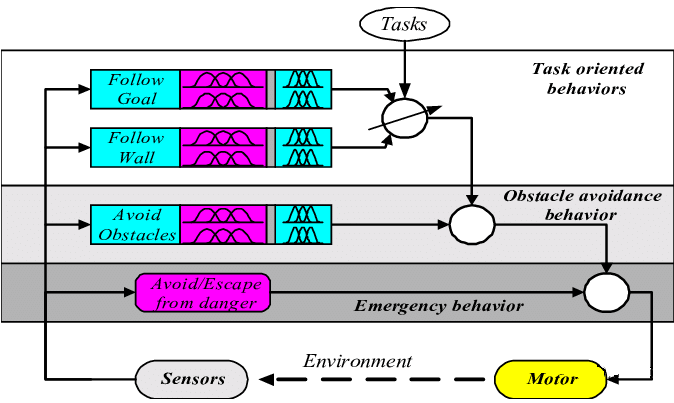
▲图2|传统机器人的控制框架;往往联合多个系统结合既定规则进行决策,几乎没有“AI”含量©️【深蓝具身智能】编译
所谓的“通用知识”“语义理解”在那时还没影子,更多只是被机器人工程师硬写成一条条 if_else 规则,像搭积木一样堆起来。
因此,这一阶段“笨笨的”机器人只能在极度结构化的场景中勉强运行,比如固定的工厂流水线,完全无力应对未知变化。
第二阶段(2010-2020):深度学习重构了感知和动作策略
2012 年 ImageNet 大赛后,CNN 的崛起让深度神经网络开始在视觉领域大放异彩,AI 也终于能“看得懂”更多世界。
机器人由此迎来了几次技术革命:
先是平地一声惊雷,深度学习这尊大神横空出世,几乎掀了控制论的桌子!随后,强化学习更是够狠,从游戏界直接“硬控”进了四足机器人领域。
深度视觉驱动的操作(这里特指Manipulation):
在深度神经网络得到广泛的关注之后,许多机器人学者开始考虑将其引入到传统的机器人控制方案之中,组成了直到现在还是非常热门的模块化设计方案,将神经网络擅长的任务交给神经网络,其余部分依旧使用可解释性强且成熟的传统控制方案。
比如当时受到广泛关注的Dex-Net 提出用物理仿真+深度网络解决未知物体抓取问题。
其核心思想是,先用上万种 3D mesh 物体在仿真里生成抓取点云,基于摩擦锥和 wrench space 的抓取稳健性指标,给出每个抓取的概率评分。然后训练一个 CNN,输入是 RGBD + 局部抓取候选 patch,输出抓取成功概率。
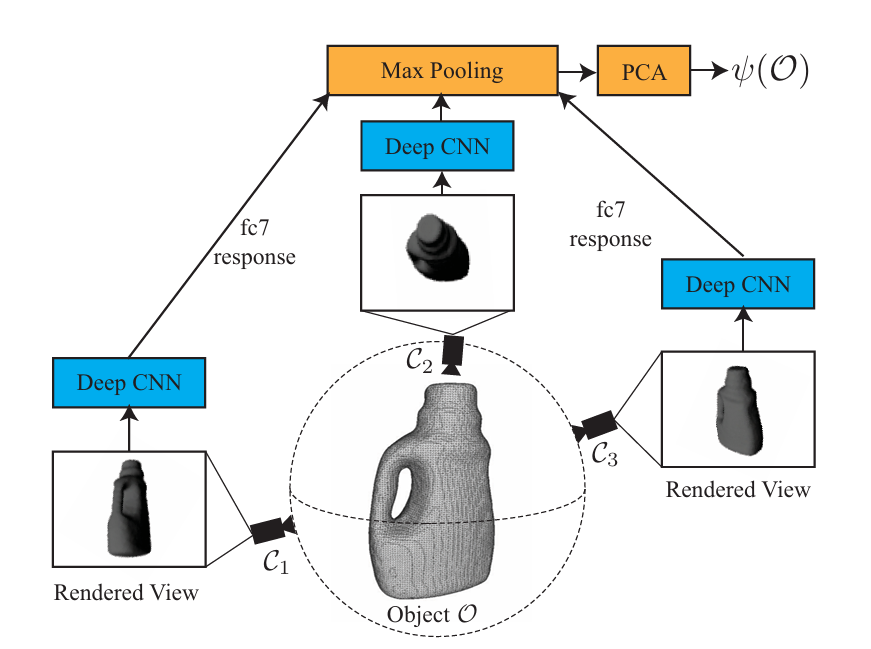
▲图3|Dex-Net的基本框架,可见其在适当的位置引入了Deep CNN来提升表现,其也通过这项创新荣获了当年ICRA的Manipulation领域最佳论文©️【深蓝具身智能】编译
这让机器人可以在仓库 bin picking 任务里,面对从未见过的异形物体,也能给出一个高置信度抓取点。
从今天看,随便一个搞机器人的硕士生都能把这套 pipeline 倒背如流。但在当时,这就是实打实的 SOTA。
它的意义在于:首次把抓取从纯几何+CAD,转向了数据驱动的概率选择。也为后来的 GraspNet 这类 RGBD 端到端网络打下了技术基础。
强化学习在机器人动力学控制的破圈:
过去,RL 在 Atari、围棋上大放异彩,但在机器人动力学控制上却屡屡受挫,这是因为:
(1)探索代价太高(机器人价格普遍非常昂贵)
(2)RL探索需求 vs 机器人容错上限的本质矛盾

▲图4|早期的波士顿动力机器人SPOT(2015),已经具备了当代先进智能机械狗的雏形,搭载了多传感器,但是在算法上依旧沿用传统的MPC策略,和外形一样“硬核”©️【深蓝具身智能】编译
在这个阶段,波士顿动力用传统控制方法让四足机器人翻山越岭,每次放个 Demo 就能让全网沸腾。
直到 2020 年后,RMA¹的提出,才把四足机器人的 RL 真正推上新台阶:
在仿真中大规模生成不同地形、不同摩擦、不同载重场景,用 PPO 学习带 latent encoder 的策略。
上实机后,只需少量里程就能快速在线调节潜变量 z,自适应地面材质或小负载扰动。

▲图5|RMA的基本框架,它的核心意义在于:将大规模离线学习与小规模在线适配结合,从根本上缓解了长期困扰机器人的 sim-to-real gap©️【深蓝具身智能】编译
这让大家第一次真切看到:Learning-based 的机器人控制也可以泛化。
在我个人看来,如果要选这个时代最“AI”的代表,或许大家会想起击败世界冠军的 Alpha Go。
虽然那只是个棋盘程序,但它的示范意义点燃了后来对 RL+机器人无数的憧憬。
第三阶段(2020-至今):大模型推理,具身智能成为热潮
CLIP、GPT、RT 系列的出现,让机器人的推理终于不再停留在像素与关节层面,而是开始理解语言和任务。
从 SayCan 到 RT,研究者们推动了视觉-语言-动作的多模态推理闭环。这些模型往往在海量网页图文、机器人视觉、动作数据上混合训练 Transformer。
输入一句“把盘子收拾干净”,
输出就是一串 robot action token(如 end-effector delta pose 序列)。
还能把场景物体语义、空间关系等全都编码进上下文。之后便演变成:机器人可以做家务、喂饭、学功夫、打擂台、跑马拉松。
我们也逐渐习惯了机器人的智能化表现,几乎下意识就把 AI 与 Robotics 绑定在一起。

▲图6|RT-1基本框架,实现首个机器人领域端到端的动作生成©️【深蓝具身智能】编译
在我看来,如果要现在就票选这个时代最“AI”的机器人,可能还为时尚早。
具身智能的未来能到什么高度,相信大家都在期待。前段时间,特斯拉电动汽车已经实现了从工厂到买家楼下的自动驾驶交付,但似乎我们已经并不奇怪了。

▲图7|马斯克发帖:特斯拉实现世界历史首例自动驾驶交付©️【深蓝具身智能】编译
或许未来真的有一天,钢铁侠里的贾维斯控制战甲走到家门口来显摆,我们也只会说一句:“好啊,不过先往旁边站站”。(野望还是要有的)

下一步
还得跨过哪些坎?
Sim-to-Real 不只是 Domain Randomization,还需要提升泛化性
当前的局限:
大多数 RL 或模仿策略,还是依赖在仿真中训练,然后尝试迁移到真实世界。
但常用的 Domain Randomization(比如随机地板材质、颜色、光照)虽然能对视觉有帮助,却对 动力学差异 无能为力。
仿真通常假设刚体、理想摩擦、理想电机。而真实环境存在关节间隙、传动延迟、材料非线性。
对于抓取、行走这类高度动力学耦合的任务,轻微的物理参数差异都会导致策略失效。
技术发展:不再只在“输入 domain”上做随机化,而是动态适配仿真背后的物理模型,使策略在不同真实场景下都能稳定执行,从而减少sim2real的gap,使得RL在机器人的不同任务中都可以泛化,不仅仅局限于四足机器人的运动控制。
生成式推理需要结合几何与物理约束
当前的局限:
RT-2 这类 VLA 模型能直接把“把红杯子放到餐桌上”翻译成机械臂动作序列。
但它也有几个显著问题,诸如:
不理解物理动态约束,比如可能指令机械臂直接撞穿桌子。
无法保证输出的路径在机器人逆运动学空间可行。
在当前的技术下,已经有部分研究者提出了一些解决思路,我也进行一些简要整理,但真正搞定这个问题,依旧道阻且长。
用 MPC(Model Predictive Control) 在 LLM 输出的轨迹周围生成短期可行走廊,纠偏以保持动力学可行。
或者在 LLM 输出阶段就插入硬约束优化,形成“生成-优化耦合”。
技术发展:让语言-视觉推理提供“任务级指导”,让传统优化或可达性约束实时保证输出的几何合法性 + 动力学可行性。
实际上这里面就涵盖着机器人对于真实物理世界的理解,当前一些Word Model的工作就致力于解决这个问题。
可解释性 & 安全探索是必备监管门槛
现今大多数机器人 RL 或 VLA 策略都像个黑箱:
出错了只能说“网络这么输出了”,很难定位哪个传感器信号或中间 feature 导致的问题。
也不具备因果链条回溯(explainable reasoning)能力。
这在家庭陪护、手术助手、自动驾驶等场景都是不可接受的,但当前为了技术先行,这些方面的法案,法规都相对滞后,在技术上机器人的自我诊断和修复能力也比较滞后。
不过,我们相信这些都会随着机器人+AI的发展得到逐步完善,或许在未来的某天,这也是一个大热的研究方向。

总结
“区区”三十年,AI 已经把机器人从只会机械重复的流水线手臂,变成了能从视频学会抓取、能在崎岖地形自适应行走、还能听懂「帮我把桌上的盘子拿过来」的多模态智能体。
但别忘了,这些“完美”的实验室视频背后,仍藏着一堆必须跨越的技术门槛:
如何真正跨过模拟与真实的差距,不再换个地板材质就摔倒?
如何让大模型生成的动作不只是“合理”,更是物理可执行、安全可追溯?
如何让机器人在用了几年后,依然知道该学新招、该忘旧法,而不是“脑子混乱”?
未来的机器人不只是要更聪明,还得更能自我解释、自我约束,才能真正进入我们的日常生活。
我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇
编辑|阿豹
审编|具身君
参考文献:
1. RMA: Rapid Motor Adaptation for Legged Robots
2. Dex-Net 1.0: A Cloud-Based Network of 3D Objects for Robust Grasp Planning Using aMulti-Armed Bandit Model with Correlated Rewards
3. A raodmap for AI in Robotics
4. RT-1: Robotics Transformerfor Real-World Control at Scale
 【深蓝具身智能读者群】-参观机器人:
【深蓝具身智能读者群】-参观机器人:



点击❤收藏并推荐本文
 扫码添加微信
扫码添加微信
- 点赞 (0)
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊





