


【AI】关于机器人数据,强化学习大佬SergeyLevine刚刚写了篇好文章
- 2025-07-28 08:00:00

我们知道,训练大模型本就极具挑战,而随着模型规模的扩大与应用领域的拓展,难度也在不断增加,所需的数据更是海量。
大型语言模型(LLM)主要依赖大量文本数据,视觉语言模型(VLM)则需要同时包含文本与图像的数据,而在机器人领域,视觉 - 语言 - 行动模型(VLA)则要求大量真实世界中机器人执行任务的数据。
目前而言,Agent 是我们走向通用人工智能(AGI)的重要过渡。训练 Agent 则需要带有行动标签的真实交互数据,而获取这类数据的成本远比从网页上获取文本与图像的成本高昂得多。
因此,研究者一直在尝试寻找一种替代方案,来实现鱼和熊掌兼得的效果:既能够降低数据获取成本,又能够保证大模型训练成果,保持基础模型训练中常见的大规模数据带来的优势。
加州大学伯克利分校副教授,Physical Intelligence 的联合创始人,强化学习领域大牛 Sergey Levine 为此撰写了一篇文章,分析了训练大模型的数据组合,但他却认为,鱼和熊掌不可兼得,叉子和勺子组合成的「叉勺」确实很难在通用场景称得上好用。

博客标题:Sporks of AGI
博客链接:https://sergeylevine.substack.com/p/sporks-of-agi
替代数据
尽管在视觉感知和自然语言处理任务中,真实世界数据一直被视为首选,但在智能体领域,尤其是机器人智能体(如视觉 - 语言 - 动作模型,VLA)中,研究者们始终在尝试寻找「替代方案」—— 即能以较低成本获取的代理数据,来代替昂贵的真实交互数据,同时仍具备训练基础模型所需的泛化能力。本文聚焦于机器人领域,但其他任务也基本遵循类似思路,只是采用了不同形式的替代数据。
仿真是一种经典策略。设想我们可以在《黑客帝国》般的虚拟环境,或高保真的电子游戏中训练机器人,就有可能避免对真实世界数据的依赖。
虽然这些方案产生了大量令人兴奋且富有创意的研究成果,但若从结构上可以将它们统一描述为:人为构建一个廉价代理域与真实机器人系统之间的映射关系,并基于这一映射,用廉价数据替代真实任务域中的昂贵数据。主流的几种方法如下:
仿真(Simulation):
「仿真到现实」(sim-to-real)的方法依赖人类设计者指定机器人的训练环境,并提供相应资源(如物理建模、视觉资产等)。机器人在仿真中学习到的行为很大程度上取决于这些人为设定。实际上,最有效的仿真往往并不追求对现实的高度还原(这本身极具挑战),而是故意引入各种环境变化,如随机的石板路或不同高度地形,以提高机器人鲁棒性。这种设计方式不仅定义了任务「是什么」,也间接规定了任务应「如何完成」。
人类视频(Human Videos):
基于人类视频训练机器人技能的方法,通常需要在人体与机器人之间建立某种对应关系,例如手的位置或手指的抓取动作。这种映射方式预设了一种具体的任务完成策略(例如通过「握持 - 搬运」的方式),同时也必须跨越人类与机器人在动力学和外观上的差异鸿沟。
手持式夹爪设备(Hand-held Gripper Devices):
这种方法并非在训练时构建映射关系,而是通过物理手段直接建立人机之间的映射。具体做法是让人类使用手持设备来模仿机器人夹爪完成任务。这种方式颇具吸引力,因为参与者必须以类似机器人的方式执行任务。但这同样隐含着一套「动作设定」前提:例如,设备默认机器人能在具有 6 自由度的操作空间中,仅使用手指完成任务,且不暴露机器人与人类在运动学结构或外观上的差异。
以上方法都产生了大量有意义的研究成果,并在实践中取得了诸多成功案例。然而,从长远看,我认为这些方法在本质上都代表了一种妥协 —— 这种妥协可能会削弱大规模学习模型原本所具备的强大能力与泛化潜力。
交叉点
在数据采集过程中,人类的判断显然无法回避:即便是最真实、最纯粹的「白板式」学习方法,也必须由我们来设定模型应完成的任务目标。然而,当我们试图规避对真实数据的依赖而做出的一些设计决策,往往会带来更大的问题,因为这些决策本身就限制了解决问题的方式。
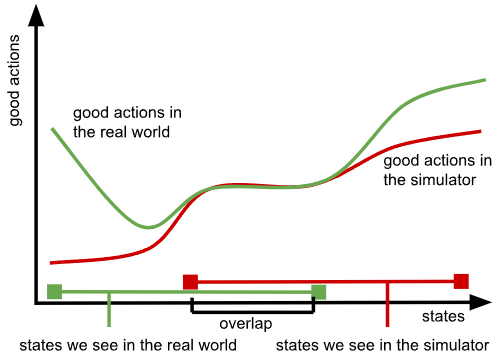
每存在一个领域差异(如模拟环境、视频等),我们所能采用的解决方案就被限定在一个交集之中:

随着模型能力的不断增强,其区分替代数据域与真实世界目标域的能力也在提升(即图中黄色圆圈收缩),这就导致行为策略的交集区域不断缩小。
我们可以尝试通过隐藏信息来对抗这一问题,例如减少观察空间、引入领域不变性损失、限制机器人可用的摄像头视角等等。几乎所有用于缓解领域差异的方法归根结底都是某种形式的信息隐藏。
但这种做法再次削弱了基础模型的最大优势 —— 即整合复杂信息来源、提取人类难以察觉的细微模式的能力。
换句话说,随着模型变强,黄色圆圈变小,而任何试图阻止这一趋势的做法,最终都等同于削弱模型能力。我们只能通过「让模型变傻」,来「欺骗」它不去意识到自己身处「矩阵」之中。
这个交集区域的大小,还严重依赖于我们在构建替代数据时所做的设计决策 —— 设计得越糟糕,绿色圆圈(真实世界中成功策略的空间)与红色圆圈(可用于训练的替代策略空间)之间的交集就越小。
实际操作中,我们往往围绕某几个特定应用场景,精心设计替代数据的获取方式,以尽可能缩小在这些场景下与真实机器人的差异,使得「良好行为」在这两个系统中尽量一致。
但这种一致性在这些应用场景之外并无任何保障。
本质上,当我们用人类的数据来训练机器人基础模型,再让它面对新的任务时,它会试图预测「人类会如何解决这个问题」,而不是预测一个「机器人能如何高效完成这个任务」的策略。
这再次背离了基础模型的核心优势 —— 即具备广泛通用性和强泛化能力,能够将训练模式推广到全新领域。
而如今,每进入一个新领域,我们就需要投入更多的人工工作来改善替代数据与真实世界之间的对应关系;模型原本的泛化能力,反而成了我们的负担 —— 它会放大替代数据与真实机器人之间的差距,使得我们在应对新场景时更为艰难。
当我们真正希望优化机器人的最优行为(例如通过强化学习)时,以上所有问题都会进一步加剧。
真实世界数据
当我们试图回避使用真实世界数据的需求时,实际上是在追求一种「鱼与熊掌兼得」的方案:既希望像模拟或网络视频那样成本低廉,又希望像在大规模真实数据上训练出的基础模型那样高效。
但最终得到的,往往只是一个「叉勺」—— 在极少数符合我们假设的场景中,它既能当叉子用,也能当勺子用,但大多数时候,它只是一个布满孔洞的蹩脚勺子,或一个迟钝无力的叉子。
在机器学习中,一贯最有效的方法是让训练数据尽可能贴近测试环境。这才是「真实的」—— 能够教会模型世界真实运行机制的数据,从而让模型能胜任任务,提取出其中的潜在规律;这些规律往往复杂而微妙,连人类都难以察觉,而模型却能从中进行归纳推理,解决复杂的新问题。
当我们用替代数据代替真实数据时,其实是在做「次优之选」:只有在某些特定条件下,它才能勉强模拟真实情况。
就像你不可能通过单靠对着墙打球,或者看费德勒打网球的录像,就成为一名真正的网球高手 —— 尽管这两者确实复制了部分专业体验;同样的,机器人如果从未在真实世界中「亲自下场」,也无法真正掌握如何在真实世界中行动。
那么,我们应从中得到什么启示?
最关键的一点是:如果我们希望构建能够在真实物理世界中具备广泛泛化能力的机器人基础模型,真实世界的数据是不可或缺的,正如 LLM 和 VLM 在虚拟世界中所展示的强大泛化能力一样。
在构建训练集时,如果我们在广泛而具代表性的真实机器人经验之外,加入包括人类演示、甚至仿真在内的多样化数据源,往往会带来帮助。事实上,可以坦然地将替代数据视为补充知识的来源 —— 它的意义在于辅助,而非替代真实的实践经验。
在这种视角下,我们对替代数据的要求也将发生根本性的转变:我们不再追求它在形态上尽可能接近真实机器人(比如使用手持夹爪,或让人模仿机器人动作录视频),而是将其视为类似于 LLM 预训练数据的存在 —— 不是直接告诉智能体该做什么,而是提供关于「真实世界可能发生什么」的知识来源。
叉勺(Sporks)
在本文中,我探讨了「替代数据」这一「叉勺」 —— 它试图在避免大规模真实数据采集成本的前提下,获得大规模训练的收益。但在人工智能研究中,替代数据并不是唯一的一把「叉勺」。
其他「叉勺」还包括:结合手工设计与学习组件的混合系统,利用人为设定的约束来限制自主学习系统不良行为的方法,以及将我们对问题求解方式的直觉,直接嵌入神经网络架构中的模型设计。
这些方法都试图「兼得」:既要享受大规模机器学习带来的优势,又要规避其高数据需求或繁琐目标设计的代价。这些方法有着相似的核心:它们都是通过某种手工设计的归纳偏置,来应对训练数据不完全的问题。
因此,它们也都面临同样的根本性缺陷:
需要我们人为地将「我们以为我们是怎么思考的方式」编码进系统中。
在任何可学习系统中,任何不是通过学习获得的、而是人工设计的部分,最终都将成为系统性能的瓶颈。
「叉勺」之所以吸引人,是因为它们让我们觉得:只要让模型按我们设定的方式解决问题,就能克服人工智能中的重大挑战。但事实是,这样做反而让我们的学习系统更难以扩展 —— 尽管我们最初的意图正是为了提升其扩展性。
更多信息,请参阅原博客。
☟☟☟
☞人工智能产业链联盟筹备组征集公告☜
☝
精选报告推荐:
11份清华大学的DeepSeek教程,全都给你打包好了,直接领取:
【清华第四版】DeepSeek+DeepResearch让科研像聊天一样简单?
【清华第七版】文科生零基础AI编程:快速提升想象力和实操能力
【清华第十一版】2025AI赋能教育:高考志愿填报工具使用指南
10份北京大学的DeepSeek教程
【北京大学第五版】Deepseek应用场景中需要关注的十个安全问题和防范措施
【北京大学第九版】AI+Agent与Agentic+AI的原理和应用洞察与未来展望
【北京大学第十版】DeepSeek在教育和学术领域的应用场景与案例(上中下合集)
8份浙江大学的DeepSeek专题系列教程
浙江大学DeepSeek专题系列一--吴飞:DeepSeek-回望AI三大主义与加强通识教育
浙江大学DeepSeek专题系列二--陈文智:Chatting or Acting-DeepSeek的突破边界与浙大先生的未来图景
浙江大学DeepSeek专题系列三--孙凌云:DeepSeek:智能时代的全面到来和人机协作的新常态
浙江大学DeepSeek专题系列四--王则可:DeepSeek模型优势:算力、成本角度解读
浙江大学DeepSeek专题系列五--陈静远:语言解码双生花:人类经验与AI算法的镜像之旅
浙江大学DeepSeek专题系列六--吴超:走向数字社会:从Deepseek到群体智慧
浙江大学DeepSeek专题系列七--朱朝阳:DeepSeek之火,可以燎原
浙江大学DeepSeek专题系列八--陈建海:DeepSeek的本地化部署与AI通识教育之未来
4份51CTO的《DeepSeek入门宝典》
51CTO:《DeepSeek入门宝典》:第1册-技术解析篇
51CTO:《DeepSeek入门宝典》:第2册-开发实战篇
51CTO:《DeepSeek入门宝典》:第3册-行业应用篇
51CTO:《DeepSeek入门宝典》:第4册-个人使用篇
5份厦门大学的DeepSeek教程
【厦门大学第一版】DeepSeek大模型概念、技术与应用实践
【厦门大学第五版】DeepSeek等大模型工具使用手册-实战篇
10份浙江大学的DeepSeek公开课第二季专题系列教程
【精选报告】浙江大学公开课第二季:《DeepSeek技术溯源及前沿探索》(附PDF下载)
【精选报告】浙江大学公开课第二季:2025从大模型、智能体到复杂AI应用系统的构建——以产业大脑为例(附PDF下载)
【精选报告】浙江大学公开课第二季:智能金融——AI驱动的金融变革(附PDF下载)
【精选报告】浙江大学公开课第二季:人工智能重塑科学与工程研究(附PDF下载)
【精选报告】浙江大学公开课第二季:生成式人工智能赋能智慧司法及相关思考(附PDF下载)
【精选报告】浙江大学公开课第二季:AI大模型如何破局传统医疗(附PDF下载)
【精选报告】浙江大学公开课第二季:2025年大模型:从单词接龙到行业落地报告(附PDF下载)
【精选报告】浙江大学公开课第二季:2025大小模型端云协同赋能人机交互报告(附PDF下载)
【精选报告】浙江大学公开课第二季:DeepSeek时代:让AI更懂中国文化的美与善(附PDF下载)
【精选报告】浙江大学公开课第二季:智能音乐生成:理解·反馈·融合(附PDF下载)
6份浙江大学的DeepSeek公开课第三季专题系列教程
【精选报告】浙江大学公开课第三季:走进海洋人工智能的未来(附PDF下载)
【精选报告】浙江大学公开课第三季:当艺术遇见AI:科艺融合的新探索(附PDF下载)
【精选报告】浙江大学公开课第三季:AI+BME,迈向智慧医疗健康——浙大的探索与实践(附PDF下载)
【精选报告】浙江大学公开课第三季:心理学与人工智能(附PDF下载)
【AI加油站】第八部:《模式识别(第四版)-模式识别与机器学习》(附下载)
人工智能产业链联盟高端社区

一次性说清楚DeepSeek,史上最全(建议收藏)
DeepSeek一分钟做一份PPT
用DeepSeek写爆款文章?自媒体人必看指南
【5分钟解锁DeepSeek王炸攻略】顶级AI玩法,解锁办公+创作新境界!
【中国风动漫】《雾山五行》大火,却很少人知道它的前身《岁城璃心》一个拿着十米大刀的男主夭折!

免责声明:部分文章和信息来源于互联网,不代表本订阅号赞同其观点和对其真实性负责。如转载内容涉及版权等问题,请立即与小编联系(微信号:913572853),我们将迅速采取适当的措施。本订阅号原创内容,转载需授权,并注明作者和出处。如需投稿请与小助理联系(微信号:AI480908961)
编辑:Zero




 扫码添加微信
扫码添加微信








