通用全身机器人操控更进一步!学习现实世界全身操控任务的统一框架
- 2025-07-28 08:00:00

点击下方卡片,关注“具身智能之心”公众号
作者丨Astribot Team
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
写在前面&出发点
打造通用智能机器人是机器人技术的基本目标,一种有前景的方法是模仿人类进化轨迹,即通过与环境持续互动学习且早期进步由模仿人类行为推动,这面临设计安全且具人类水平物理能力的机器人硬件、开发直观可扩展的全身遥操作界面用于数据收集、创建能从人类示范中学习全身视觉 - 运动策略的算法这三个核心挑战;为在统一框架中解决这些挑战,提出了用于全身操控、旨在应对不同环境中一般日常任务的星尘机器人套件(Astribot Suite),其在一系列需全身协调、广泛可达性、人类水平灵活性和敏捷性的活动中展现了有效性,结果表明该机器人在实体、遥操作界面和学习流程上的紧密整合,是现实世界中通用全身机器人操控的重要一步,为下一代智能机器人奠定了基础。

一些介绍
长期以来,开发能栖息于人类环境、具备类人感知、理解行为后果、安全互动并协助人类日常生活的智能机器人,是科幻小说中未实现的愿景。要实现类人能力及人类水平智能,需从与物理世界的各种精细互动中学习,而模仿人类行为、注重具有广泛可达性、灵活性和敏捷性的全身协调是切实有效的起点。
在日常环境中实现自主全身操控面临三个基本挑战:一是需要精心设计机器人硬件,既要能安全部署于人类环境,又要具备人类水平的物理能力和表现力;二是需要直观且可扩展的数据收集界面,方便非专业人员自然高效地执行各类日常任务;三是需要能捕捉全身控制复杂性且有扩展到开放世界环境和活动潜力的学习模型。
为应对上述挑战,研究提出了一个用于学习现实世界全身操控任务的统一框架,该框架包含三个核心组件:一是开发了高性能机器人平台,即带有灵活躯干和移动基座的双臂操控器,旨在有效且优雅地模仿人类行为;二是引入了注重通用性、高可用性和低延迟的全身遥操作界面,便于普通非专业用户进行可扩展的数据收集;三是提出了全身视觉 - 运动策略(DuoCore-WB)这一简单有效的学习算法,它利用 RGB 观测和精心设计的动作表示来建模协调的全身动作。
硬件系统
本节详细介绍了星尘机器人套件的硬件组件,包括图 2 所示的移动双臂操控器(其设计有两个 7 自由度的手臂、4 自由度的灵活躯干、2 自由度的头部和 3 自由度的全向移动基座,专为需高移动性和扩展末端执行器可达性的日常任务优化),以及一种经济高效的全身遥操作界面(能在广泛现实世界操控场景中实现直观高效的数据收集)。

机器人平台
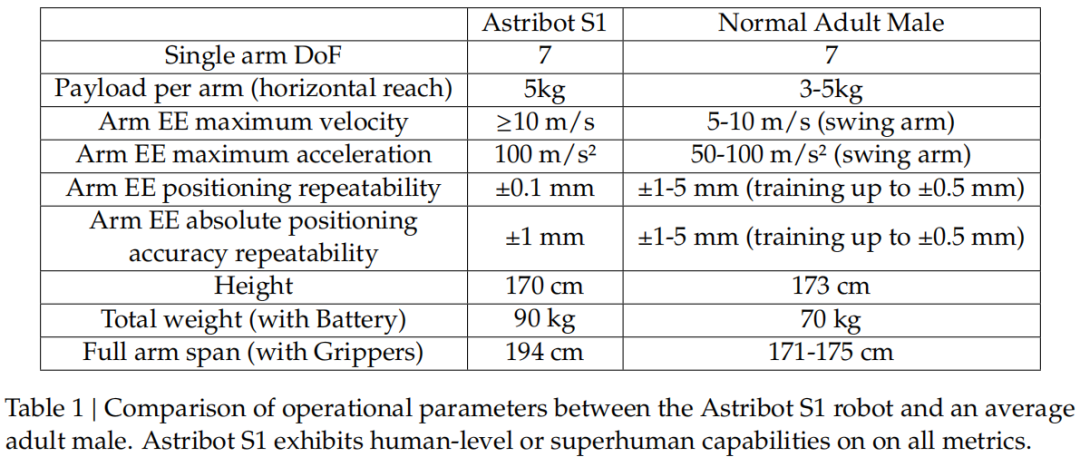
星尘机器人 S1 在 4 自由度躯干上安装了两个 7 自由度手臂,每个手臂配备平行颚式夹具,可处理达 5 公斤载荷、操控多种日常物体,夹具最快 0.15 秒开合,能收集投掷等敏捷类人行为数据;4 自由度躯干允许腰部旋转、髋部弯曲和类似膝盖的关节运动,可使机器人平稳转换站立和蹲坐姿势,增强垂直移动性并扩展有效工作空间;2 自由度头部可实现动态 gaze 控制和任务相关视觉聚焦,模仿人类在大型或杂乱环境中的感知行为;其有效垂直触及范围从地面到 2 米,水平触及可达 1.94 米(带夹具),旨在以人为中心的环境中有效运作并支持多种任务,关键性能指标超过人类平均水平,如表 1 中与普通成年男性的基准对比所示。
星尘机器人 S1 配备多种机载传感器以实现稳健的场景理解和操控,其传感器视场如图 2(c)所示:头部集成立体 RGB 相机和 RGB-D Orbbec Femto Bolt,提供高分辨率视觉输入;手腕安装两个 Intel RealSense D401 RGB-D 相机,用于精细操控时的近距离观测;胸部安装 Orbbec Gemini 335 RGB-D 相机,用于中距离感知;底盘安装 Livox MID-360 激光雷达,用于 360 度空间感知和 mapping,且所有 RGB-D 相机均以 30Hz 频率运行。
为支持稳定且敏捷的导航,S1 机器人的躯干安装在全向移动基座上,该基座能在地面平面全方位运动,最大线速度为 2 米 / 秒,底盘集成四个驱动模块,可实现前后运动、横向平移和原地旋转,在受限环境中机动性高。
用于可扩展数据收集的低延迟遥操作
为实现稳健场景理解和操控等目标,遥操作系统利用 Meta Quest 3S 虚拟现实头显,将头显和手持操纵杆姿态映射到机器人末端执行器,通过全身控制框架转换为关节级命令,实现实时运动同步,且有两种可灵活切换的控制模式。第一人称视角模式中,操作员从机器人视角控制,适合远程精细操控,能完成折叠衣服等任务,提供高精度和沉浸式体验;第三人称视角模式中,操作员站在机器人旁直接观察控制,适合大范围全身运动控制,能消除延迟不确定性,提高安全性和响应性,适合高动态任务或近场数据收集。该系统适用于服务机器人示范等多种场景。
系统实现了直观且实时的全身控制,重新配置 Meta Quest 3S 操纵杆支持遥操作和示范记录,主要命令包括按住握持按钮激活动作跟随模式、触发器控制夹具开合、左操纵杆控制移动基座、右操纵杆调整肢体垂直位置,使用户能直观控制全身运动和基座导航,且系统控制频率 100Hz,端到端响应延迟 20 毫秒,第一人称视角模式图像传输延迟约 100 毫秒(如图3所示)。

系统注重安全性,有两项安全功能:一是机器人损坏保护,通过倾翻保护机制限制重心降低摔倒风险,遵循自碰撞约束并借助相关引擎实现笛卡尔空间目标跟踪;二是冲击力缓解,凭借绳索驱动设计的被动柔顺性,利用基于模型的算法估计外力,结合高频扭矩限制实现主动柔顺控制,防止接触时大冲击力。
系统能提供高质量示范,遥操作界面使示范轨迹重放成功率接近 100%,动作跟踪误差低,这对示范质量和策略可重复性很关键,如 “捡起玩具” 任务中部分关节跟踪误差可视化所示。
系统成本低,遥操作界面仅用现成的 Meta Quest 3S 头显和操纵杆,硬件总成本不到 300 美元,易于获取和扩展,适合广泛部署。
全身策略学习方法
本节介绍了一种简单有效的全身视觉 - 运动策略学习方法,先概述预备知识,再介绍旨在从示范数据中学习全身控制策略的 DuoCore-WB 算法,该方法强调简单性和可扩展性以确保与大规模预训练兼容,其使用通过星尘机器人套件遥操作界面收集的遥操作示范数据进行训练,模型架构概述如图 5 所示。

预备知识
策略学习的去噪扩散中,扩散模型通过向前过程向干净数据添加噪声,再学习逆转噪声(反向过程)来估计去噪分数,其在 T 个时间步将数据分布噪声化为各向同性高斯分布,公式为

训练时扩散模型 通过

学习估计噪声,训练完成后可从有噪声输入和相应噪声预测中估计 x;最近,DDPMs 被广泛用于建模策略 ,以机器人观测 为条件,其中去噪网络 通过行为克隆进行训练。
全身视觉 - 运动策略
提出的基于 Transformer 的 DuoCore-WB 模型,旨在学习通用操控任务的协调全身动作。其在末端执行器(EE)空间对全身动作去噪,而非高维关节配置空间,以减少误差累积;该模型在每个末端执行器的自我中心框架中学习 delta 姿态,可促进视觉观测与动作目标的对齐,增强对全身活动中常见大视角变化的鲁棒性;且仅使用 RGB 观测训练,确保与大规模视觉 - 语言 - 动作(VLA)模型预训练管道无缝兼容。
模型架构方面,从遥操作示范中采样图像 - 状态对和相应动作序列,将动作序列作为预测目标。观测图像来自头部、左手和右手相机,经 ResNet-Small 骨干网络编码等处理后,结合可学习的位置嵌入(指示空间位置和相机来源)形成 patch 令牌;机器人状态被编码为状态向量并投影为状态令牌,添加专用可学习位置嵌入表示模态;3 个相机视图的 patch 令牌与状态令牌连接后输入 Transformer 编码器提取条件特征。之后,通过条件扩散模型对动作序列去噪,有噪声的动作序列经处理形成查询令牌序列,解码器通过交叉注意力关注编码的条件令牌,其输出投影回原始动作空间产生去噪动作序列,由训练目标监督,动作序列包含基座控制命令、躯干运动等内容。
实时轨迹生成模块(RTG)针对当代策略模型生成动作块时存在的块内抖动(同块连续动作不一致)和块间不连续性(不同块间突然过渡导致轨迹不连续,在全身操控中更明显)等问题而提出,这些问题会降低执行稳定性,甚至威胁硬件完整性。
该方法是轻量级后处理模块,可与任何满足特定条件的视觉 - 运动学习算法无缝集成:一是策略模型每个推理周期生成动作块,块中每个动作有与训练数据时间分辨率对齐的时间戳;二是推理时间短于单个动作块执行持续时间(理想不超过一半),以保证有足够重叠实现平滑轨迹过渡。
新动作块生成时,其观测时间戳设为 t=0,总持续时间为 tₑ,推理延迟为 t₁,轨迹生成模块处理时间为 t₂,新动作块为 ,当前执行轨迹为 ;新动作块可用时,自 t=0 已过 t₁+t₂时间,系统会丢弃 ,继续执行 ,并从 t=t₁+t₂开始在 和 (为预定义混合范围且≤ 最后时间戳)间平滑混合。
混合过程借助二次规划(QP)优化生成平滑且动态可行的轨迹,解决连续性、过渡质量和物理约束问题,关键组件包括:平滑项(S₁),最小化轨迹加速度以确保运动平滑等;与旧轨迹的偏差(S₂),用指数下降的时间衰减权重 W₁(t) 惩罚与 的偏差;与新动作块的偏差(S₃),使用权重 W₂(t)=1-W₁(t) 鼓励与 对齐,且 W₂(t) 随时间增加以平滑转移控制权限;速度约束(C₁),强制执行关节速度限制以符合硬件规格。对于初始动作块,通过平滑项(S₁)、固定权重 W₁(t)=1 的偏差损失(S₃)和速度约束 C₁优化生成轨迹,最后用样条插值优化后的离散轨迹,确保运动平滑,且与推理异步执行以实现连续稳定控制。
RTG 在兼容性、全面性和鲁棒性上有优势:作为模型无关的后处理方法,可与任何训练好的策略无缝集成;有效缓解块间不连续性和块内抖动,同时考虑关节速度限制等硬件约束;仅需带时间戳的动作块作为输入,不依赖策略推理时间或频率的精确估计,对通信延迟和推理延迟有弹性。
训练和部署细节:DuoCore-WB 旨在从有噪声的全身动作中预测添加的噪声,损失函数为 ,其中 εᵗ是真实添加的噪声, 是预测的噪声;部署时,推理在配备 NVIDIA RTX 4090 GPU 的工作站上进行,有效延迟 0.05 秒,策略推理以 20Hz 运行,推理结果以相同频率同步输入到 RTG,RTG 以 250Hz 向控制器发出动作命令,即每 0.05 秒生成新策略动作序列并更新 RTG 状态,控制器命令每 0.004 秒刷新一次。
实验分析
实验设置
我们在六个代表性任务上评估星尘机器人套件,包括递送饮料(评估长时任务中移动操控和与铰接物体灵巧交互能力)、存放猫粮(测试受限空间精细操控等)、扔垃圾(考验多阶段双手协调和对铰接部件精确操控能力)、整理鞋子(强调低高度下全身协调和同步双手操控)、扔玩具(突出动态全身运动和准确抓取小物体能力)、捡起玩具(作为多物体操控的综合基准);这些长时、多阶段任务可分解为一系列子任务,每个任务进行 15-30 次评估试验,在首次子任务失败时终止,同时报告每个子任务的成功率和整体端到端任务成功率。
星尘机器人套件遥操作界面对于策略学习既直观又高效
我们从效率和示范数据对下游策略学习的质量两方面评估星尘机器人套件的遥操作系统,比较了人类直接完成任务的时间与专家、非专家使用该遥操作界面完成任务的时间,涉及两个代表性任务。结果显示,简单桌面任务中,专家比人类多花 28.27% 时间,非专家多花 60.93%;更复杂的全身任务(打开两个抽屉、分类放入四个物品并关闭抽屉)中,专家额外时间增至 41.43%,非专家多花 94.80%,这表明该遥操作界面在挑战性全身操控场景中也能实现高效直观操作。同时,该界面能让用户生成平滑准确的机器人动作,跟踪误差低(如 “捡起玩具” 任务中随机选择的六个关节数据所示),体现了所收集示范数据的高保真度,且在各种任务中重播成功率约为 100%,始终提供高质量数据。
DuoCore-WB 是一种简单但有效的全身活动学习方法
六个代表性任务的成功率评估显示,DuoCore-WB 平均成功率 80%,最高 100%,“按下打开垃圾桶盖” 子任务成功率最低,原因在于按钮视觉对比度低、感知线索有限且依赖多视图观测,自我中心框架优势难以发挥。
在动作表示方面,末端执行器(EE)空间表示相比关节空间表示,在全身任务中精度更高,能减轻误差累积,尤其在长误差传播路径的动态全身活动中优势明显;增量动作表示相比绝对动作表示,生成的轨迹在动作块间的不连续性更小,平滑度和时间一致性更优。
参考框架比较中,自我中心框架的增量动作表示在各类任务中平均成功率更高,在腕部相机为主的任务中增强视觉与动作对齐,在头部相机引导任务中受视角变化影响小,在全身协调任务中提供稳定运动目标表示,且在分布偏移时泛化能力和部署鲁棒性更强。
轨迹表示比较表明,自我中心框架的相对轨迹表示在多任务操控学习中性能最佳,其动态更新参考框架,使跨任务轨迹结构更对齐、紧凑,方差低、信息密度高,与机器人感知和控制匹配,能实现有效局部反馈策略,优于世界框架绝对轨迹和机器人框架相对轨迹。
实时轨迹(RTG)生成模块有效性评估显示,与同步推理(有执行停顿)、异步推理(有速度峰值和突然过渡)、带历史融合的异步推理(仍有速度幅度问题)相比,RTG 能将速度约束在安全范围,实现平滑执行,且执行轨迹与预测动作块紧密对齐,减少轨迹漂移和分布外状态,利于提高任务成功率和策略鲁棒性。
总结
本文提出了星尘机器人套件(Astribot Suite),这是一个用于全身操控的机器人学习套件,包含三个核心组件:具有人类水平物理能力的安全机器人平台、用于现实世界数据收集的直观且可扩展的遥操作界面、与大规模策略预训练兼容的简单但有效的全身视觉 - 运动策略。尽管该套件在广泛任务中表现良好,但在学习处理需更高敏捷性、灵活性或长期记忆的更高级任务时存在局限性。未来计划在机器人硬件增强(改进平台以提升能力和安全性)、人机交互(迭代更直观智能的交互方法)、模型和系统可扩展性(优化架构和预训练策略以提高效率,实现可扩展学习系统并广泛部署)等方向重点投入。
参考
[1] Towards Human-level Intelligence via Human-like Whole-Body Manipulation

 扫码添加微信
扫码添加微信

- 点赞 (0)
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊