


这家具身公司的定位很工业化?!待遇最高100w招募算法研究员

OneStar由吉利集团孵化,以“真实 数据驱动的智能进化机器人”为核心定位,锚定大工业场景,通过持续积累与优化真实场景数据,让机器人在实践中实现智能迭代,为工业生产与智能化升级提供全新解题思路。 一星机器人联合全球顶尖多模态大模型及FastUMI数采技术团队,融合吉利新能源汽车三电与智能能力,构建“模型+数据+本体”综...
2025-07-17 15:00:00
果然!秋招会惩罚每一个本末倒置的研究生!

随着秋招开始,有不少同学又开始了内耗和焦虑。就业形势一直在变,大家对于工作的渴望却日渐攀升,纷纷感慨:如果能重来,我一定多发论文,多积攒项目实践!对于毕业的小伙伴们,我能给到的建议就是抓紧时间、注重复盘、注重复盘、整合资源。简单来说就是校招、社招两手抓,有的放矢进行查漏补缺,要善于利用一切资源来帮助...
2025-07-17 12:00:00
小模型逆袭!复旦&创智邱锡鹏团队造出「世界感知」具身智能体,代码数据完全开源!

点击下方卡片,关注“具身智能之心”公众号作者丨Junhao Shi等编辑丨具身智能之心本文只做学术分享,如有侵权,联系删文>>点击进入→具身智能之心技术交流群更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。——开源LVLM新框架WAP登顶EmbodiedBench榜单1. 引言(Introducti...
2025-07-17 08:00:00
一周年啦,心酸历程!从野路子到一个专业的具身教育平台

具身智能之心一周年了!1年前的这个时候,我们在自动驾驶之心平台发布了两周年自驾推文!那个时候,也正是我们筹备具身智能业务的时候,到现在足足1年了。这一年无论是产品层面还是融资、技术层面,具身领域是突飞猛进的扩张。2家明星公司,也陆续传来即将上市的消息,对整个产业是一个巨大的鼓舞。具身智能之心是新孵化的...
2025-07-17 08:00:00
BeDAViN:大规模音频-视觉数据集与多声源架构研究
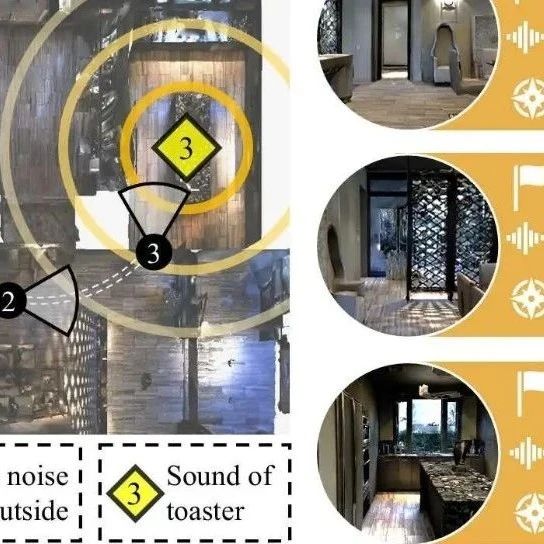
作者丨视觉语言导航点击下方卡片,关注“具身智能之心”公众号>>点击进入→具身智能之心技术交流群更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。作者:Zhanbo Shi, Lin Zhang, Linfei Li, Ying Shen单位:同济大学计算机学院论文标题:Towards Audio-visual Navigatio...
2025-07-17 08:00:00
为什么纯人形VLA方案很少?这些公司的方案是哪些?

为什么现在的很多工作都在机械臂VLA,包括头部几个大厂的工作,人形全身的VLA和移动操作的VLA,甚至说四足的VLA基本没啥很好的工作。why?先分析下行业里面是怎么用VLA的?机械臂 VLA 目前主要应用于移动抓取和放置任务,这些任务相对单一且主要依赖视觉,辅以触觉或力觉传感器,容易落地。人形机器人的数据采集困难、控制...
2025-07-16 12:00:00
重磅直播!RoboTwin2.0:强域随机化双臂操作数据生成器与评测基准集

点击下方卡片,关注“具身智能之心”公众号>>直播和内容获取转到→具身智能之心知识星球点击按钮预约直播双臂机器人在协同装配、工具使用和物体交接等复杂场景中具有重要作用,但要训练出通用的 VLA 等操作策略,现有数据收集和仿真管线面临多重瓶颈。一方面,真实示教数据规模化获取成本高、耗时长,难以覆盖足够多的任务、物...
2025-07-16 07:00:00
让 VLMs 更适配机器人:小型VLMs也能展现出强大的视觉规划能力

点击下方卡片,关注“具身智能之心”公众号作者丨Andy Yun等编辑丨具身智能之心本文只做学术分享,如有侵权,联系删文>>点击进入→具身智能之心技术交流群更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。出发点&研究背景大语言模型(LLMs)在机器人程序规划中展现出潜力...
2025-07-16 07:00:00
物理模拟器与世界模型驱动的机器人具身智能综述

作者丨机器之心编辑丨机器之心点击下方卡片,关注“具身智能之心”公众号>>点击进入→具身智能之心技术交流群更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。本文作者来自:南京大学、香港大学、中南大学、地平线、中国科学院计算所、上海交通大学、慕尼黑工业大学、清...
2025-07-16 07:00:00
TACTILE-VLA:激活VLA模型的物理知识以实现触觉泛化(清华大学最新)

点击下方卡片,关注“具身智能之心”公众号作者丨x编辑丨具身智能之心本文只做学术分享,如有侵权,联系删文>>点击进入→具身智能之心技术交流群提出背景与核心问题视觉-语言-动作模型凭借其强大的语义理解和跨模态泛化能力,已成为通用型机器人代理研发的核心驱动力。这类模型依托预训练的视觉-语言backbone网络,能够解读抽...
2025-07-15 16:00:00
