


清华大学具身智能多传感器融合感知综述
- 2025-07-28 08:00:00
作者丨Shulan Ruan等
编辑丨视觉语言导航
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。

作者:Shulan Ruan, Rongwei Wang, Xuchen Shen, Huijie Liu, Baihui Xiao, Jun Shi, Kun Zhang, Zhenya Huang, Yu Liu, Enhong Chen, You He 单位:清华大学,中国科学技术大学,合肥工业大学 论文标题:A Survey of Multi-sensor Fusion Perception for Embodied AI: Background, Methods, Challenges and Prospects 论文链接:https://arxiv.org/pdf/2506.19769v1
主要贡献
提供了一个全面的多传感器融合感知(MSFP)研究综述,从任务无关的角度对多模态、多智能体、时间序列以及MM-LLM融合方法进行了系统性总结。 对现有的MSFP方法进行了分类和分析,包括多模态融合(点级、体素级、区域级和多级融合)、多智能体融合、时间序列融合以及MM-LLM融合方法。 讨论了MSFP在数据层面、模型层面和应用层面面临的挑战,并提出了未来可能的研究方向。
I. 介绍
A. 具身智能的背景
具身AI的定义:具身AI是一种通过物理实体作为载体,利用实时感知能力在动态环境中实现自主决策和行动能力的智能形式。它在自动驾驶、机器人集群智能等领域有广泛应用。 具身AI的重要性:具身AI被认为是突破AI发展瓶颈、实现人工通用智能(AGI)的关键路径之一。
B. 多传感器融合感知的核心地位
传感器数据理解的重要性:在具身AI系统中,传感器数据的理解是物理世界与数字智能之间的核心纽带。与传统的以视觉为主的感知模式不同,具身智能体需要整合多模态传感器数据来实现对环境的全景感知。 多传感器融合的必要性:不同的传感器(如视觉相机、毫米波雷达、激光雷达等)在不同的环境条件下表现各异。例如,相机在光照变化下容易受到干扰,而激光雷达在雨雾天气中性能会显著下降。因此,通过多传感器融合可以实现更鲁棒的感知和准确的决策。
C. 当前研究的局限性

现有综述的局限性: 大多数现有综述集中在单一任务或研究领域(如3D目标检测或自动驾驶),这使得其他相关任务的研究人员难以直接从中受益。 大多数综述仅从多模态融合的角度介绍MSFP,缺乏对其他融合方法(如多视图融合和时间序列融合)的考虑。 现有方法的局限性: 数据异构性:跨模态数据的异构性使得特征空间的统一变得困难。 时空异步性:不同传感器之间的时空异步可能导致融合错误。 传感器故障:传感器故障(如镜头污染和信号阻塞)可能导致多模态信息的动态丢失。
II. BACKGROUND背景
A. 传感器数据
在MSFP中,不同类型的传感器数据是实现环境感知的基础。论文详细介绍了三种常见的传感器数据类型:相机数据、激光雷达(LiDAR)数据和毫米波雷达(mmWave Radar)数据。
相机数据
特点:相机能够捕捉物体的丰富外观特征,包括颜色、形状和纹理,这些特征对于多种感知任务至关重要。 局限性:作为被动传感器,相机对光照条件非常敏感。在夜间或恶劣天气(如雾、雨)下,图像质量会显著下降。
激光雷达(LiDAR)数据
特点:激光雷达通过测量发射和接收激光信号的时间差来计算物体距离,直接输出包含空间几何信息的高精度3D点云数据,在3D感知中具有独特优势。 局限性:激光雷达通常对天气敏感,且由于其固有的稀疏性和非均匀性,有效地表示和理解激光雷达点云数据仍然是一个挑战。
毫米波雷达(mmWave Radar)数据
特点:毫米波雷达通过发射和接收无线电波来检测物体,与激光雷达点云相比,雷达点云更稀疏,难以准确描述物体轮廓,但在恶劣天气下仍能保持良好的性能,并且可以直接测量物体的速度。
B. 数据集
为了支持MSFP的研究和开发,多个基准数据集已经被创建,这些数据集涵盖了不同的场景和传感器组合。

KITTI
特点:包含14,999张图像及其对应的点云数据,分为训练集和测试集。数据涵盖了城市、乡村和高速公路场景。 注释:包含8个类别,分为简单、中等和困难三个级别。
nuScenes
特点:在波士顿和新加坡收集,包含700个训练场景、150个验证场景和150个测试场景。每个场景持续约20秒,共40个样本。 注释:包含140万张相机图像、39万次激光雷达扫描、140万次雷达扫描和140万标注的边界框。
Waymo Open
特点:包含感知和运动数据集,涵盖了白天、夜间、黎明、黄昏和雨天场景。 注释:感知数据集包含126万3D边界框、118万2D边界框、10万图像的全景分割标签等。
Cityscapes 3D
特点:基于Cityscapes数据集,增加了3D边界框注释,主要用于城市街道场景的3D场景理解任务。
Argoverse
特点:包含3D跟踪数据集和运动预测数据集,涵盖了360度视野,提供了高定义地图。
A*3D
特点:主要在新加坡城市道路上收集,包含39k标注帧,覆盖了多种天气条件和城市道路条件。
ApolloScape
特点:包含140k高分辨率图像,覆盖了多个时间段和天气条件。
AIODrive
特点:由卡内基梅隆大学的研究团队开发,针对城市场景,包含多种传感器数据。
H3D
特点:专注于城市环境中的3D目标检测和跟踪,包含约160个场景,总计约27k帧。
感知任务
目标检测
任务描述:目标检测是感知系统中最基本的任务之一,其目标是通过传感器数据准确定位和识别各种类型的物体。 输出:在2D目标检测中,系统需要输出物体的类别信息和2D边界框(x, y, w, h)。在3D目标检测中,检测结果需要包括3D位置坐标(x, y, z)、3D尺寸信息(l, w, h)和目标的方向角θ。
语义分割
任务描述:语义分割任务的目标是对场景中的每个基本单元(如图像像素)进行分类,将其分配到语义类别中。 输出:给定一组输入数据(如图像像素集合)和预定义的语义类别集合,分割模型需要为每个基本单元分配相应的语义标签或类别概率分布。
深度估计
任务描述:深度估计旨在从传感器数据中获取场景的深度信息,为具身智能体提供3D几何理解。 输出:给定输入图像和对应的稀疏深度图,深度估计系统需要输出密集深度图,通过深度补全过程实现。
占用预测
任务描述:占用预测可以提供对3D空间的密集语义理解。通过将连续的3D空间离散化为体素,占用感知模型可以预测每个体素的占用状态和语义类别。 输出:为自主决策提供完整的场景表示。
III. 多模态融合方法
多模态融合方法通过整合不同传感器的数据,减少感知盲点,实现更全面的环境感知。例如,激光雷达可以提供准确的深度信息,而相机则保留更丰富的语义信息。如何更好地融合这些多模态数据以提供更准确和鲁棒的感知,已成为广泛研究的热点。

A. 点级融合

点级融合方法的目标是在单个点的水平上实现激光雷达点云和图像数据之间的特征融合。通过整合点云的几何坐标信息和图像的语义细节(如颜色和类别属性),可以提高多模态感知的准确性。
PointFusion:分别从RGB图像和点云中提取特征,然后将它们连接起来进行融合。 PointPainting:将每个激光雷达点用图像特征进行标注,通过投影激光雷达点到分割掩码上实现融合。 MVP:通过将2D检测结果投影到虚拟3D点上,并将其与激光雷达数据合并,增强稀疏点云。 DeepFusion:采用交叉注意力机制动态对齐激光雷达和图像特征,并通过逆数据增强解决几何错位问题。
B. 体素级融合

体素级融合方法将不规则的激光雷达点云转换为规则的网格(如体素或柱状结构),以便于高效处理,同时保留几何信息。
CenterFusion:通过将雷达点扩展为3D柱状结构,并将雷达检测与图像对象关联,解决高度信息不准确的问题。 PointAugmenting:通过增强激光雷达点的图像特征,并对增强后的点云进行体素化,提高感知能力。 VFF:引入点到射线的投影方法,沿射线融合图像特征,为检测遮挡和远处物体提供更丰富的上下文信息。 AutoAlign:引入可学习的多模态融合框架,动态对齐图像和点云特征,无需依赖投影矩阵。
C. 区域级融合

区域级融合方法侧重于聚合来自2D图像和其他模态的区域特定信息,如特征图、感兴趣区域(ROI)或区域提议。这些方法在模态之间的空间对齐相对容易实现的场景中特别有效。
AVOD:引入多模态融合区域提议网络,分别处理鸟瞰图(BEV)和RGB图像以生成高分辨率特征图。 RoarNet:采用两阶段框架,第一阶段直接从图像预测3D姿态,避免投影相关的信息丢失,第二阶段使用点云推理细化预测。 TransFusion:利用Transformer进行激光雷达-相机融合,通过建立激光雷达点和图像像素之间的软关联,适应上下文信息,解决由图像质量差或传感器校准错误引起的鲁棒性问题。
D. 多级融合

多级融合方法在不同层次上整合多模态信息,以实现更全面的感知。这些方法通常结合多阶段融合、注意力机制或对比学习等技术,以提高感知的鲁棒性。
MVX-Net:执行点级和体素级融合,结合多模态信息以提高感知性能。 EPNet:引入LI-Fusion模块,通过在不同尺度上融合图像和点云特征,减少无关信息的干扰,提高鲁棒性。 LoGoNet:结合全局和局部融合与动态特征聚合,提高复杂环境中的检测精度。 CSSA:采用轻量级通道切换和空间注意力机制,实现高效的融合。
IV. 多智能体融合方法
在复杂开放环境中,尤其是当能见度受阻或在恶劣天气条件下,单个具身智能体的感知系统面临着诸多挑战。多智能体协作感知技术可以通过整合多个智能体和基础设施的感知数据来解决这些问题,这对于应对遮挡和传感器故障至关重要。本节将重点关注智能体之间的多视图融合(Agent-to-Agent, A2A)协作感知。
A. 多智能体融合的动机
单智能体的局限性:在复杂环境中,单个智能体的传感器可能因遮挡或恶劣天气而失效,导致感知能力受限。 多智能体的优势:通过多个智能体之间的协作,可以共享感知数据,从而提高感知的鲁棒性和准确性。
B. A2A融合方法

多智能体融合方法主要关注智能体之间的协作感知,通过共享和融合来自多个智能体的感知数据来提高整体感知能力。
CoBEVT
方法描述:CoBEVT是首个通用的多智能体多相机感知框架,通过稀疏Transformer生成鸟瞰图(BEV)分割预测。它引入了轴向注意力模块,用于高效融合多智能体多视图相机特征,捕捉局部和全局空间交互。 特点:能够处理多智能体之间的空间交互,提高感知的全局一致性。
CoCa3D
方法描述:CoCa3D提出了一种创新的协作相机感知框架,仅使用相机的智能体可以通过共享视觉信息来解决深度预测偏差问题。通过共享相同点的深度信息,CoCa3D减少了误差,改善了深度模糊问题,并扩展了检测能力到遮挡和远距离区域。 特点:特别适用于仅使用相机的多智能体系统,能够显著提高深度感知的准确性和鲁棒性。
V2VNet
方法描述:V2VNet引入了一种基于图神经网络的框架,用于融合多个车辆的中间特征表示。它通过图结构建模智能体之间的关系,实现高效的特征融合。 特点:适用于车辆之间的协作感知,能够处理复杂的交通场景。
MACP
方法描述:MACP探索了如何利用预训练的单智能体模型来实现协作感知,通过高效的模型适配,减少参数数量和通信成本。 特点:在保持高性能的同时,显著降低了计算和通信开销。
HM-ViT
方法描述:HM-ViT提出了一个统一的框架,用于多模态A2A感知问题,能够融合来自不同类型传感器(如多视图图像和激光雷达点云)的特征,实现高效的多模态协作感知。 特点:支持多种传感器数据的融合,提高了感知的多样性和鲁棒性。
MRCNet
方法描述:MRCNet通过引入运动增强机制来解决运动模糊问题,通过捕获运动上下文,减少运动模糊对目标检测的影响,从而在嘈杂场景中实现更好的性能。 特点:特别适用于处理运动模糊问题,提高了动态场景下的感知能力。
C. 通信优化方法
When2Com
方法描述:When2Com提出了一个框架,用于学习如何构建通信组以及何时进行通信。通过握手机制和非对称消息大小,减少了带宽使用,同时在语义分割和3D形状识别任务中取得了良好的性能。 特点:通过动态调整通信策略,优化了通信效率。
Who2Com
方法描述:Who2Com通过学习握手通信机制,提高了语义分割任务的准确性,并且相比集中式方法使用了更少的带宽。 特点:通过优化通信机制,减少了通信开销,提高了协作效率。
How2Com
方法描述:How2Com提出了一个基于信息论的通信机制和时空协作Transformer,通过特征过滤、延迟补偿和时空融合,提高了协作感知的效率和鲁棒性。 特点:在3D目标检测任务中表现出色,显著提高了协作感知的性能。
CodeFilling
方法描述:CodeFilling通过信息填充策略和码本压缩技术,优化了协作消息的表示和选择,实现了低通信成本的高效协作感知。 特点:在保持高性能的同时,显著降低了通信成本。
V. 时间序列融合

时间序列融合是多传感器融合感知(MSFP)系统中的一个关键组件,它通过整合多帧数据来解决单帧感知的局限性,增强感知的连续性和时空一致性。时间序列融合方法特别适用于动态环境,例如自动驾驶中的车辆运动、行人行为预测等场景。
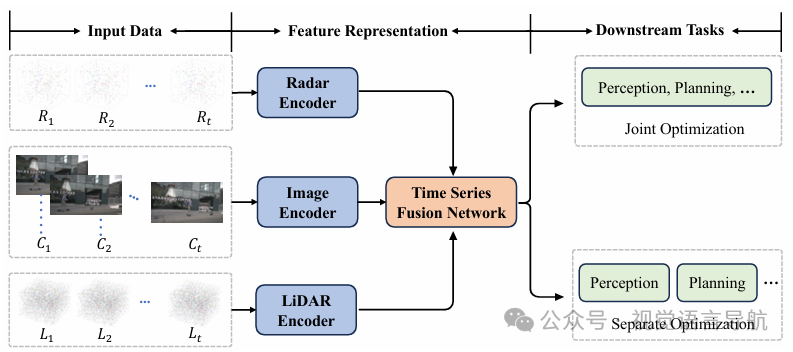
A. 时间序列融合的重要性
单帧感知的局限性:单帧感知方法在处理动态环境时容易受到噪声、遮挡和传感器故障的影响,导致感知结果不准确。 时间序列融合的优势:通过整合多帧数据,时间序列融合方法可以利用时间维度上的冗余信息,提高感知的鲁棒性和准确性,同时能够预测未来的状态,增强系统的决策能力。
B. 基于查询的时间序列融合方法
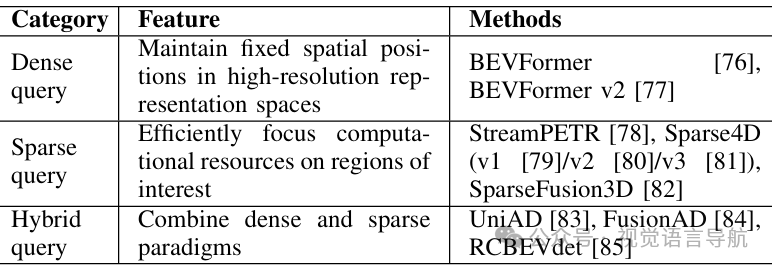
近年来,随着Transformer架构在计算机视觉中的兴起,基于查询的时间序列融合方法成为主流。这些方法通过将感知特征编码为查询(queries),并与时空中的键(keys)和值(values)进行交互,实现有效的特征对齐。这些方法可以分为三类:密集查询(Dense Query)、稀疏查询(Sparse Query)和混合查询(Hybrid Query)。
密集查询方法
特点:密集查询方法(Dense Query Methods)在高分辨率的空间表示中为每个查询点分配固定的栅格化空间位置,适用于需要高分辨率表示的任务,如语义分割。 代表方法: BEVFormer:基于DETR和Deformable DETR,通过可变形注意力机制在多个相机视图中实现自适应特征交互。BEVFormer引入了一个额外的编码器,基于密集的BEV查询生成密集的BEV特征,支持语义分割任务。 BEVFormer v2:采用两阶段检测架构,结合视角检测和BEV检测,通过视角监督自适应学习3D场景表示,无需依赖昂贵的深度预训练数据。 BEVDet4D:基于LSS(深度驱动的自底向上方法),将3D检测扩展到4D时间域,通过空间对齐和特征拼接融合前一帧的BEV特征与当前帧的特征。 BEVerse:作为一个统一的感知和预测框架,从多相机视频序列中生成4D BEV表示,通过共享特征提取和提升模块实现。
稀疏查询方法
特点:稀疏查询方法(Sparse Query Methods)通过在稀疏的时空表示中高效地分配计算资源,特别适用于需要实时决策的任务。这些方法通过稀疏查询与多帧图像特征的交互来避免密集BEV特征的时间关系建模带来的计算负担。 代表方法: StreamPETR:通过目标查询系统地传播长期信息,避免了在密集BEV特征中建模时间关系的计算负担。 Sparse4D:通过4D关键点采样和层次特征融合实现高效的时空特征提取。 Sparse4D v2:采用递归方法,使用稀疏实例进行时间信息传播,避免多帧采样以提高特征融合效率。 Sparse4D v3:进一步提出时间实例去噪和质量估计,加速模型收敛并提高性能。 MUTR3D:第一个端到端的3D多目标跟踪框架,将目标检测与下游任务(如路径规划和轨迹预测)通过3D多目标跟踪连接起来,并提出了3D跟踪查询机制,用于建模跨帧的目标时空一致性。 PF-Track:采用“通过注意力跟踪”框架,使用目标查询在时间上一致地表示跟踪实例。在长期遮挡情况下,通过未来推理模块维持目标位置并实现重新关联。
混合查询方法
特点:混合查询方法(Hybrid Query Methods)结合了密集和稀疏查询范式,通过在对象级任务中使用稀疏查询,在空间完整任务中保持密集表示,实现了计算效率和全面场景理解之间的平衡。 代表方法: UniAD:作为一个混合架构,将感知、预测和规划集成在一个统一框架中。它使用稀疏对象查询进行高效的检测和跟踪,同时保持密集的BEV特征用于轨迹预测和规划任务。 FusionAD:将混合方法扩展到多模态时间融合,通过基于Transformer的架构处理相机和激光雷达数据,根据任务需求在稀疏和密集表示之间自适应切换。 RCBEVdet:引入双流网络,为雷达流设计RadarBEVNet以提取点云BEV特征,为相机流使用图像主干和视图变换器,通过基于可变形DETR的跨注意力多层融合模块实现有效的4D毫米波雷达-相机融合。
VI. 多模态大模型融合方法
A. MM-LLM在MSFP中的作用
多模态大语言模型(MM-LLM)能够处理和融合来自不同来源的数据,例如文本、图像和传感器输出,从而极大地丰富对复杂环境的理解。然而,将这些模型集成到具身AI的实际应用中仍然面临挑战,尤其是在处理稀疏和不规则的传感器数据(如激光雷达和雷达点云)时。
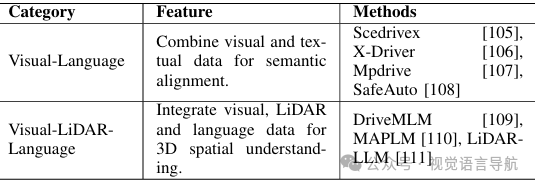
B. 视觉-语言融合方法

视觉-语言融合方法通过结合视觉数据(如图像)和文本数据来实现语义对齐。这些方法通常利用预训练的LLM来处理文本信息,并将其与视觉特征进行融合,以完成各种任务,如图像描述、视觉问答等。
Sce2DriveX:提出了一个通用的LLM框架,用于从场景到驾驶的学习,通过视觉和语言的结合来提高驾驶决策的准确性。 X-Driver:提出了一个统一框架,利用多模态LLM进行链式推理和自回归建模,实现了闭环自动驾驶的卓越性能。 MpDrive:引入了一种基于标记的提示学习框架,通过简洁的视觉标记来表示空间坐标,并构建双粒度视觉提示,以提高需要高级空间理解的任务的性能。 SafeAuto:提出了一种知识增强的安全自动驾驶方法,通过多模态基础模型来提高自动驾驶的安全性和可靠性。
C. 视觉-激光雷达-语言融合方法

视觉-激光雷达-语言融合方法通过结合视觉数据、激光雷达数据和文本数据来实现3D空间理解。这些方法通常利用图像作为中间媒介,将激光雷达数据和文本数据进行对齐,从而实现更有效的融合。
DriveMLM:提出了一种基于时间的QFormer方法,用于处理多视图图像,能够有效捕捉不同时刻和不同视角下的时空动态和空间关系。 MAPLM:将3D激光雷达点云数据投影到鸟瞰图(BEV)图像中,并通过视觉编码器提取特征。这种方法将3D数据转换为2D表示,便于利用传统的深度学习模型进行处理。 LiDAR-LLM:提出了一种新的框架,将3D场景理解重新表述为语言建模任务,通过位置感知的Transformer(PAT)和三阶段训练策略来弥合3D与语言模态之间的差距,实现了3D描述、定位和问答等任务的最新性能。
VII. 挑战和未来机遇
A. 数据层面
数据是MSFP系统的基础,但现有的数据集和数据处理方法仍存在许多挑战。
数据质量
问题:现有数据集(如KITTI、nuScenes、Waymo Open)存在长尾分布问题,即某些类别或场景的数据量远少于其他类别,这限制了模型对罕见但关键场景的泛化能力。此外,数据中可能存在缺失值、异常值、偏差和漂移等问题,缺乏标准化的评估方法和公共数据集。 解决方案: AIGC技术:利用人工智能生成内容(AIGC)技术生成合成数据,填补真实数据集的空白,特别是对于罕见或多样化的场景。例如,通过光逼真渲染和扩散模型生成高质量的合成数据。 自动化错误检测工具:开发用于检测合成数据中错误的自动化工具,确保生成数据的质量。 量化质量指标:引入量化质量指标,帮助识别数据中的问题,如缺失值、异常值和数据漂移。
数据增强
问题:多模态数据增强需要在不同传感器模态之间保持同步,这带来了独特的挑战。例如,在对激光雷达点云应用旋转或平移时,需要对相应的相机图像应用等效的变换,以保持空间一致性。 解决方案: 跨模态几何约束:利用跨模态几何约束来确保在增强过程中保持空间一致性。例如,将激光雷达点云的变换与相机图像的齐次变换相结合。 AIGC技术:利用扩散模型等AIGC技术生成逼真且同步的增强数据,模拟传感器噪声和环境变化,同时确保跨模态一致性。
B. 模型层面
模型设计和融合策略对于提高MSFP系统的性能至关重要,但现有方法仍存在一些局限性。
有效的融合策略
问题:在多模态传感器数据的对齐和融合过程中,信息丢失是一个关键问题。传感器模态之间的物理配置、分辨率和视角差异可能导致对齐不准确,进而影响融合效果。此外,天气和光照条件的变化会加剧这些差异,使得精确同步更加困难。 解决方案: 多表示融合技术:结合体素网格、点云和2D投影等多种表示方法,以保留空间和语义信息。 上下文感知方法:利用时间一致性和自适应学习方法,动态响应环境变化,提高对齐精度。 注意力机制:在融合过程中选择性地强调每种模态的关键特征,减少信息丢失。 自监督和对比学习:通过自监督表示学习和对比学习捕捉和利用跨模态关系,为对齐提供更丰富的监督信息。
多模态LLM方法
问题:将多模态LLM集成到实际的具身AI应用中面临挑战,尤其是在处理稀疏和不规则的传感器数据(如激光雷达和雷达点云)时。此外,LLM在多样化数据集上训练得到的外部知识可能与具身AI的具体需求冲突。 解决方案: 混合架构:结合几何学习技术(如图神经网络或基于点的学习模型)与多模态处理能力,开发混合架构以处理稀疏和不规则的传感器数据。 动态适应机制:利用检索增强生成(RAG)等机制动态适应多传感器数据提供的上下文,调整外部知识以满足具体需求。 注意力机制:通过注意力机制强调相关特征,过滤掉无关或误导性内容,确保外部知识与具身AI系统的实时需求一致。
C. 应用层面
在实际应用中,MSFP系统需要在复杂多变的环境中保持稳定性能,这带来了许多挑战。
现实世界适应性
问题:现实世界中的环境条件(如光照、天气和交通模式)变化无常,MSFP系统需要在这些动态变化中保持可靠的性能。例如,从白天到夜晚或从晴天到雨天的突然变化可能会使系统失效。 解决方案: 自适应算法:开发能够实时响应环境变化的自适应算法,通过领域适应和在线学习技术,使模型能够适应新的数据分布,而无需从头开始重新训练。 零样本学习方法:探索零样本学习方法,使模型能够泛化到未见过的场景,处理新型环境条件,而无需针对特定场景进行预先训练。
可解释性
问题:在安全关键的应用中,MSFP模型的可解释性至关重要。然而,理解每种传感器模态在不同条件下的贡献以及不同模态之间的相互作用是具有挑战性的,尤其是在复杂的现实场景中。 解决方案: 上下文感知解释方法:开发基于上下文的解释方法,根据环境条件和融合阶段澄清每种模态的作用。例如,通过注意力机制可视化工具突出显示在特定场景下贡献最大的传感器,增强决策过程的透明度。 可解释融合网络:设计能够输出模态特定置信度分数的可解释融合网络,提供对每个数据源如何影响输出的清晰理解,特别是在关键或模糊的情况下。
结论与未来工作
结论: MSFP在具身AI中具有重要的作用,通过整合多种传感器数据,可以显著提高系统的感知能力和决策准确性。然而,MSFP仍面临数据质量、模型融合策略、应用适应性等多方面的挑战。 未来工作: 数据层面:开发高质量的数据集,利用人工智能生成内容(AIGC)技术生成合成数据以填补真实数据集的空白。 模型层面:开发更有效的融合策略,减少信息损失,并探索结合几何学习技术与MM-LLM的混合架构。 应用层面:提高MSFP系统在真实世界中的适应性,开发自适应算法以应对环境变化,并增强模型的可解释性。

本文只做学术分享,如有侵权,联系删文
 扫码添加微信
扫码添加微信

- 点赞 (0)
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊







