


全面碾压π0,国产VLA“弯道超车” | VR教1次就会,字节GR-3开启机器人「闪学」时代,泛化性爆表!
- 2025-07-23 07:45:00
打造一个有温度、有趣味、专业的全栈式AI&AIGC交流社区,
用心写好每一篇文章!
项目主页-https://seed.bytedance.com/zh/GR3
论文链接-https://arxiv.org/pdf/2507.15493
代码链接-未开源

01-GR-3核心优势
GR-3 是字节Seed团队刚发布的一个大规模的视觉-语言-动作(VLA)模型。它对新物体、新环境以及含抽象概念的新指令展现出较好的泛化能力。
另外,GR-3 支持少量人类轨迹数据的高效微调,它可以快速且经济地适应新任务。GR-3 在处理长周期和灵巧性任务(包括需要双手操作和底盘移动的任务)上也展现出稳健且可靠的性能。
此外,Seed团队还推出了一款双臂移动机器人 ByteMini。ByteMini 兼具灵巧性和可靠性,集成了 GR-3 后,能完成各式各样的复杂任务。
02-GR-3落地场景
如上面的视频所示,通过与视觉 - 语言数据的联合训练,GR-3 可以更好地泛化到未见过的环境、指令、物体。在跟随指令和成功率方面,GR-3 均有一定优势。当在训练中去掉视觉 - 语言数据,模型面对未见过的指令和物体性能均有明显下降。这意味着视觉 - 语言数据的联合训练为 GR-3 带来了强大的泛化能力。
上面的视频展示了该方法利用颇具挑战性的挂衣服任务测试 GR-3。该任务中,机器人需要将衣架穿进衣服中,再将其挂在晾衣杆上。虽然机器人训练数据中的衣服均为长袖款式,但是GR-3 对短袖衣物同样能有效处理。
03-GR-3基本原理

上图展示了GR-3的整体架构。为了赋予GR-3遵循分布外(OOD)指令的泛化能力,作者在机器人轨迹和视觉语言数据上联合训练GR-3。机器人轨迹数据以流匹配为目标训练VLM骨干和动作DiT。视觉语言数据仅训练具有下一个令牌预测目标的VLM骨干。
为了简单起见,作者在具有相等权重的小批量中动态混合视觉语言数据和机器人轨迹。因此,联合训练目标是下一个令牌预测损失和流匹配损失的总和。

04-GR-3性能评估


如上图所示,图a展示了不同方法在四种不同的设置上,跟随指令的成功率(IF Rate)和任务成功率 (Success Rate)。 图b展示了用不同数量的人类轨迹数据联合微调后,GR-3 在两种设置下跟随指令的成功率和任务成功率。通过观察与分析,我们可以发现:该模型的多项指标远优于其它基线方法。
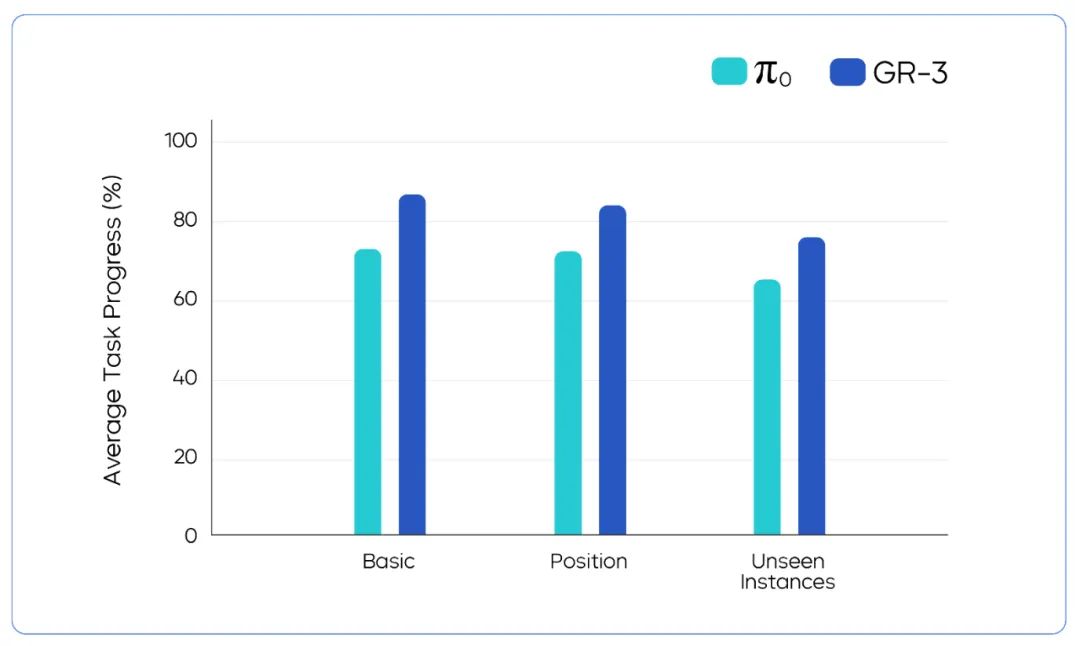
上图展示了GR-3与基线方法π0在挂衣服任务3种不同设置下的性能对比结果。我们可以直观的观察到:该方法在基础任务、特定位置任务和未看见过的实例任务上面的平均精度比π0高出了接近20%。
关注我,AI热点早知道,AI算法早精通,AI产品早上线!

禁止私自转载,需要转载请先征求我的同意!
欢迎你的加入,让我们一起交流、讨论与成长!

 扫码添加微信
扫码添加微信








