


字节跳动发布Seed GR-3:一个可泛化、支持长序列复杂操作任务的机器人操作大模型
- 2025-07-22 13:19:02
摘要
Abstract
GR-3 是一个大规模的视觉 - 语言 - 动作(VLA)模型。
项目地址:https://seed.bytedance.com/zh/GR3
GR-3 是一个大规模的视觉 - 语言 - 动作(VLA)模型。它对新物体、新环境以及含抽象概念的新指令展现出较好的泛化能力。此外,GR-3 支持少量人类轨迹数据的高效微调,可快速且经济地适应新任务。GR-3 在处理长周期和灵巧性任务(包括需要双手操作和底盘移动的任务)上也展现出稳健且可靠的性能。
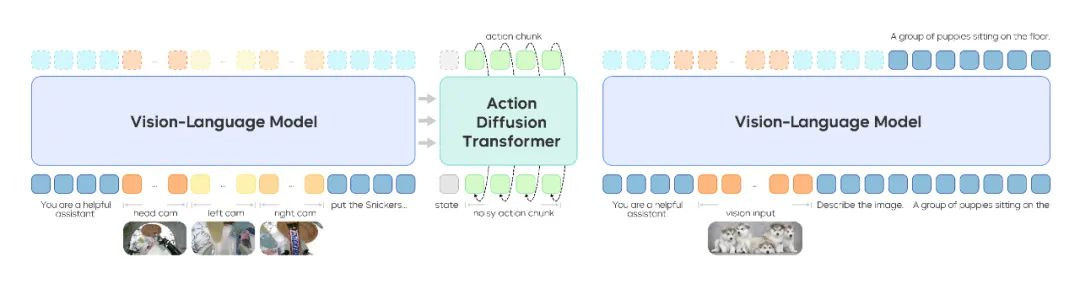
这些能力源自—种多样的训练方法,具体包括:利用大规模的视觉 - 语言数据联合训练、征集了用户授权的基于 VR 设备的人类轨迹数据进行高效微调,以及基于机器人轨迹数据进行有效地模仿学习。
此外,我们还推出了一款双臂移动机器人 ByteMini。ByteMini 兼具灵巧性和可靠性,集成了 GR-3 后,能完成各式各样的复杂任务。
通过大量真实世界实验,我们证明了 GR-3 面向各种挑战性的任务有较好表现。我们希望,GR-3 能成为迈向通用机器人“大脑”的重要一步。
指令跟随与泛化能力
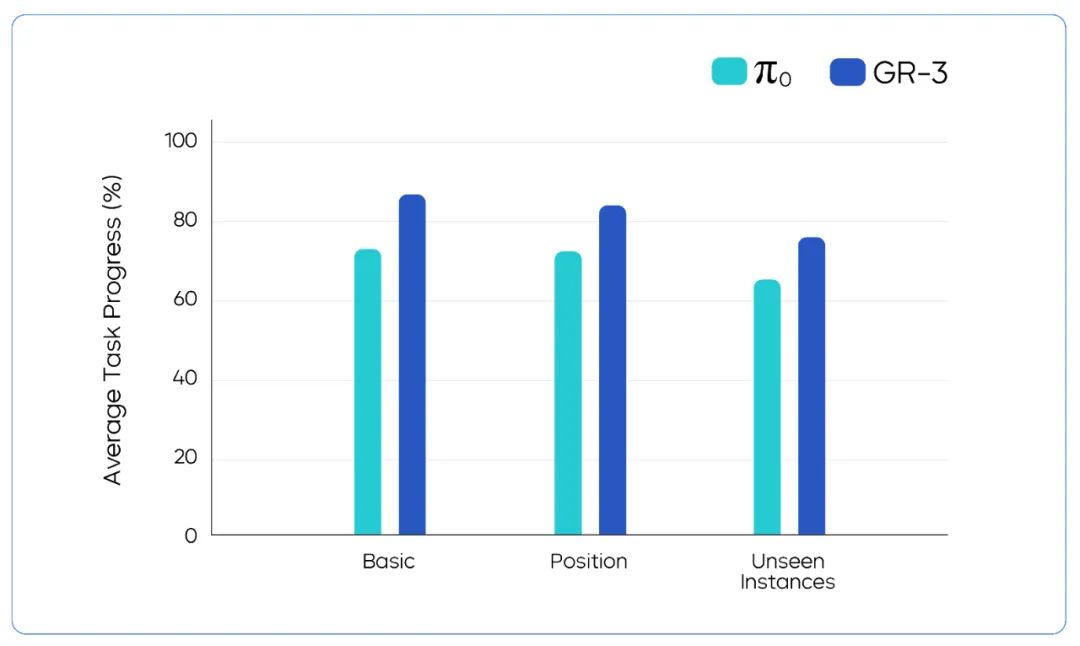
我们首先在拾取放置任务上,评估模型的指令跟随与泛化能力,具体分为四个测试设置:
基础场景(Basic):环境与物品均为训练过程中已见过的;
未知环境场景(Unseen Environments):在四个训练中未见过的环境中进行评估;
未知指令场景(Unseen Instructions):评估模型对含抽象概念的未知指令的理解能力;
未知物品场景(Unseen Objects):使用 45 个训练中未见过的物品进行评估。

(a) 图中展示了不同方法在四种设置上,跟随指令的成功率(IF Rate)和任务成功率 (Success Rate)。(b) 图中展示了用不同数量的人类轨迹数据联合微调后,GR-3 在两种设置下跟随指令的成功率和任务成功率。
通过与视觉 - 语言数据的联合训练,GR-3 可以更好地泛化到未见过的环境、指令、物体。在跟随指令和成功率方面,GR-3 均有一定优势。当在训练中去掉视觉 - 语言数据,模型面对未见过的指令和物体性能均有明显下降。这意味着视觉 - 语言数据的联合训练为 GR-3 带来了强大的泛化能力。另外,通过使用人类轨迹数据进行联合微调, GR-3 也可以快速泛化到机器人数据中未见过的物体。加入人类轨迹数据微调,对见过的物体的操作成功率几乎没有影响。随着人类轨迹数据从 1 条/物体逐渐增加到 10 条/物体,GR-3 在未见过的物体上的成功率也逐渐提升。
鲁棒的长序列任务能力
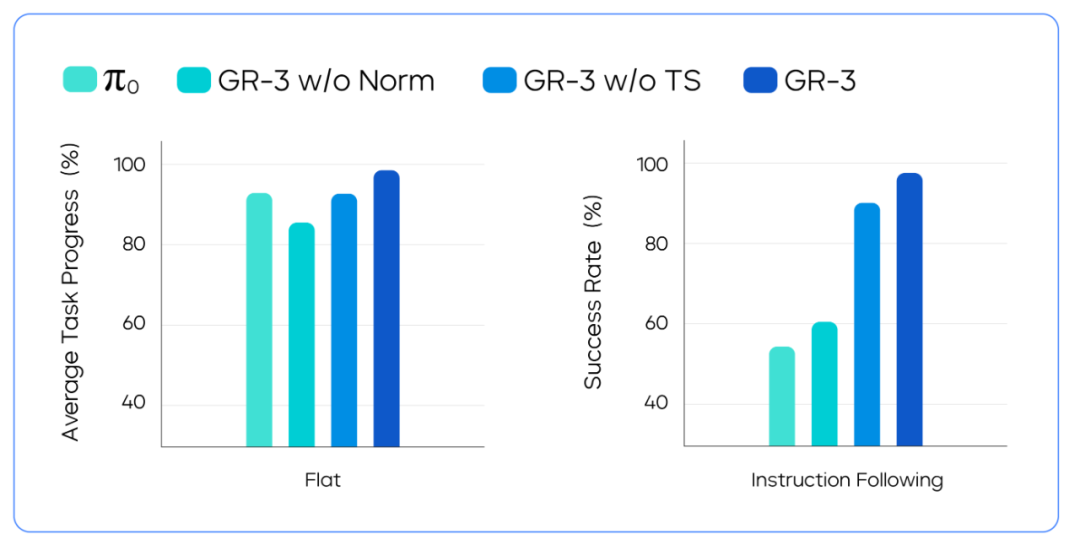
左图展示了“长程”(Flat)设置中,不同方法的任务完成度。右图展示了“指令跟随” (Instruction Following)设置中,不同方法的成功率。
可稳健地执行长序列操作,对机器人在现实世界中的部署至关重要。在本任务中,机器人需要清理一张摆满杂乱餐具、食物、餐盒和餐具收纳盒的桌子。在“长程”(Flat)设置中,我们给模型输入通用任务指令“清理餐桌”,机器人需要连续完成整个收拾餐桌的长序列任务。
而在“指令遵循”(Instruction Following)设置中,我们给模型输入多个子任务指令,机器人需要严格跟随子任务指令来完成任务。团队观察到,GR-3 和基线模型在长程设置中表现均尚可,但在指令遵循任务中,GR-3 的表现显著更优。
柔性物体的复杂操作能力
GR-3 与基线方法在挂衣服任务 3 种设置下的性能对比。
在机器人操作中,柔性物体操作向来是一项难题。我们用颇具挑战性的挂衣服任务测试 GR-3。
该任务中,机器人需要将衣架穿进衣服中,再将其挂在晾衣杆上。GR-3 在我们测试的三种设置中都表现较好。即使衣服摆放比较混乱,GR-3 也能稳定鲁棒地应对。
此外,GR-3 还能泛化到训练数据中未包含的衣服类型。举例而言,尽管机器人训练数据中的衣服均为长袖款式,但 GR-3 对短袖衣物同样能有效处理。

往期文章
全球首篇自动驾驶VLA模型综述重磅发布!麦吉尔&清华&小米团队解析VLA自驾模型的前世今生
字节跳动Seed实验室发布ByteDexter灵巧手:解锁人类级灵巧操作
具身专栏(三)| 具身智能中VLA、VLN、VA中常见训练(training)方法
具身专栏(二)| 具身智能中VLA、VLN分类与发展线梳理
具身专栏(一)| VLA、VA、VLN概述
π0.5:突破视觉语言模型边界,首个实现开放世界泛化的VLA诞生!
斯坦福&英伟达最新论文:CoT-VLA模型凭"视觉思维链"实现复杂任务精准操控
RoboTwin2.0全面开源!多模态大模型驱动的双臂操作Benchmark ,支持代码生成!
开源!Maniskill仿真器上LeRobot的sim2real的RL训练代码开源(附教程)
迈向机器人领域ImageNet,大牛PieterAbbeel领衔北大、通院、斯坦福发布RoboVerse大一统仿真平台
CVPR 北大、清华最新突破:机器人操作新范式,3.3万次仿真模拟构建最大灵巧手数据集
人形机器人四级分类:你的人形机器人到Level 4了吗?(附L1-L4技术全景图)建议收藏!
斯坦福最新论文:使用人类动作的视频数据,摆脱对机器人硬件的需求
爆发在即!养老机器人如何守护2.2亿老人?产业链+政策一览,建议收藏!


 扫码添加微信
扫码添加微信
- 点赞 0
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊







