


双杀!具身VLA硬核解析:国内2篇「互补性」工作,成功打破传统自回归范式!
- 2025-07-04 10:56:00

在机器人学习的时代叙事中,「自回归策略」一度被视为通往智能行为的“正统之路”:
通过逐步预测“下一个动作”,重现人类专家演示轨迹,从而实现类人的任务执行能力。
传统模仿学习范式,尤其是基于序列建模的自回归方法,主张用统一的token预测框架来处理连续控制问题。然而,随着任务复杂性的提升,这种单向、逐步递推的“朴素自回归”策略在长期规划与高精度控制场景中暴露出结构短视、误差累积、泛化能力弱等核心瓶颈。
在认知层面,人类并非总是线性思考与行动。我们常常先设想任务目标,再倒推策略路径;先提取几个关键动作节点,再细化动作细节;甚至在面对动态或不确定环境时,会双向修正计划以适应新信息的介入。
若希望构建真正类人的机器人智能,自回归建模也必须突破“顺序生成”的桎梏,引入更具结构感知与全局一致性的策略表达方式。
基于这一反思,来自上海交通大学的 Dense Policy 与字节跳动的 Chain of Action,分别从两个互补方向出发,提出了对传统自回归范式的系统性重构!

DensePolicy
首先是上海交通大学卢策吾老师组的新作 DensePolicy,已被ICCV2025接受。
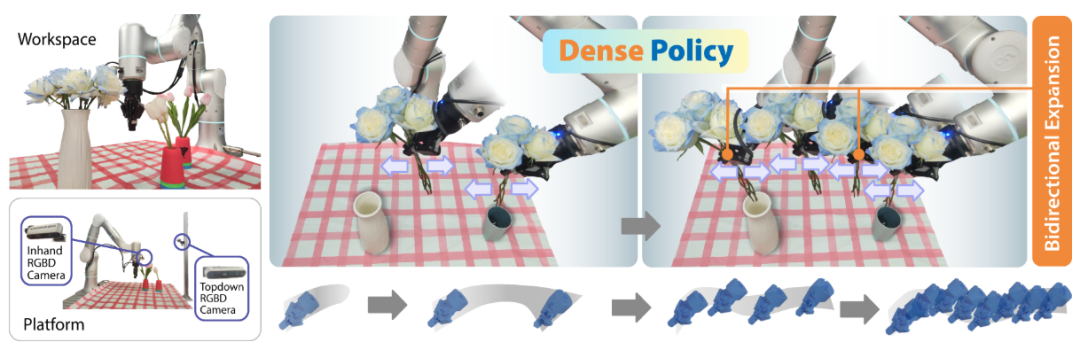
背景
自回归模型的全部潜力是否已经被实现并用于动作生成?
——当然还没有,还有各种更拟人的自回归建模范式。考虑人的操作方式:与其一步一步地顺序推断动作,人类通常会设想几个跨越整个任务执行的关键帧,并随后细化操作过程。
现有方法不足
建模方式:
现有方法(如 ACT)对整个动作序列的联合分布进行一次性建模,通常依赖单步变分推断。
生成流程:
ACT 用一次变分推断完成全部预测,DP 需要多个扩散步骤逐步生成。
自回归策略逐步递推,NextChunk 按段生成,二者复杂度为线性。

为此,作者提出了Dense Policy:一种“先粗后细”的双向层次扩展自回归范式。
通过对稀疏关键帧执行双向填充与细化,实现对整个轨迹的对数级自回归生成:
新的自回归策略,它在模拟和真实世界中,包括2D和3D场景,都表现出优于现有生成策略的性能。
第一个行动的双向自回归学习方法,并展示了其卓越的任务执行能力。
采用仅编码器架构,并展示其在轻量级、快速推理和易于训练方面的优势。
方法
1. 任务定义与分层动作建模
在给定观测信息(如 RGB 图像、点云或本体感知信息)的前提下,Dense Policy 的目标是预测未来若干时间步内的动作序列,每个动作表示机器人末端执行器的空间位姿。
Dense Policy 将完整动作序列分解为多个层次,每一层对应一种不同的时间粒度。例如,较高层表示稀疏关键帧,较低层表示更密集、更精细的动作点。最低层为一个固定向量,作为无偏的起点,避免引入人为假设。
整个动作生成过程是自回归的,当前层的预测依赖于前面所有层的动作输出与观测信息。

2. 观测编码方式
虽然 Dense Policy 的创新重点在于动作生成模块,但其设计具备良好的输入兼容性:
视觉输入方面,默认采用 ResNet18(带 GroupNorm)处理二维图像,使用稀疏卷积网络处理三维点云;
本体感知信息通过多层感知机(MLP)编码,并在训练时随机遮蔽部分末端位姿,以防止模型过度依赖静态动作位置,从而提升泛化能力;
整体框架可与任意主流视觉编码器集成,不影响核心策略模块的表现。
3. 动作生成机制(密集过程)
在完成观测编码后,动作生成遵循层级结构进行,具体包括:
上采样初始化:对于上一层已生成的稀疏动作序列,先进行线性插值上采样,构建当前层的初始动作序列;
特征融合与细化:利用一个基于 BERT 架构的 Transformer 编码器,将上采样动作与观测特征进行融合。交叉注意力机制使得模型在每一层都能利用已有动作作为先验知识,引导更精细动作的生成;
逐层递推生成:上述过程会在每一层中重复执行,直到动作序列扩展至所需的时间长度;
最终输出与训练:最终生成的动作序列通过线性变换投射至实际动作空间,并通过 L2 损失函数与真实动作进行监督对齐。
实验
1. 仿真实验表现
在2D与3D任务中,Dense Policy在大多数任务上均显著优于基线方法。
相较于DP3成功率提升19%,相较于DP提升27%。
在如shelf place、bin picking、pen manipulation、peg insert side等高难任务中表现尤为突出,显示出在高自由度、接触丰富、时序长的任务中具有更强的动作建模能力与任务完成能力。

2. 消融实验结果
在Door、Bin Picking等任务中,对比单向自回归预测(如next-token、next-chunk),双向层次建模策略(Dense Policy)收敛更快、成功率更高。
表明双向建模更适应需要动作一致性和误差容忍度低的任务场景。

3. 真实机器人实验表现
Dense Policy在4个现实任务中表现优异,明显优于2D方法(如DP、ACT),在3D任务上整体优于RISE(当前SOTA)。

Put Bread into Pot:在软体物体操作中表现稳健,能根据姿态误差自动调整动作。

Open Drawer:在高精度配合操作中展现更高动作预测精度。

Pour Balls:在6-DoF任务中,平均完成率和动作流畅性优于基线,尽管部分试验中夹爪力度偏大导致初步成功率略低。

Flower Arrangement:在多物体、长时序任务中,Dense Policy展现出显著更强的空间推理与任务完成能力,在多个评估维度上优于RISE。

4. 训练效率与推理性能
训练更高效:Dense Policy相较于VAE类和扩散类策略,训练收敛更快,性能更稳定。
推理更轻量:相比ACT,Dense Policy推理速度相当,参数量更少;相比DP,参数略多但推理速度快近10倍。
其层次递归结构使其具备对数级推理复杂度,实现了性能、速度、模型规模三者的良好平衡。

小结
Dense Policy 提出一种层次化、双向自回归策略生成方法:先生成稀疏关键帧,再逐层细化出完整动作轨迹,形成“粗到细”的生成过程。
相较于现有自回归方法(如ACT、DP),它具备更高的生成效率、更强的动作一致性与更优的任务表现,在2D/3D仿真及真实机器人任务中均显著超越现有方法,特别适合高自由度、长时序、接触丰富等复杂任务。

Chain of Action
接下来是字节跳动的最新研究 Chain of Action。
实验背景
为了更好地对多模态动作分布建模并减少复合误差,学术界和工业界已经提出了各种建模范式。但绝大多数方法遵循forward-predcition的建模方式,始终存在一个局限:
即,执行过程中复合误差的积累。
根本原因是模型通常被期望基于当前观察预测下一步行动的最优性,而不是确保最终成功完成长期任务。虽然引入了动作分块等方式,但这只能缓解复合误差,没有解决根源:
即,forward-predcition具有短视性。
案例
为什么基于学习的机器人系统抓一个苹果经常失败,而基于规则(轨迹优化)的机器人系统做这个问题不在话下?
根本在于轨迹优化是有约束优化,而深度学习是无约束优化。
具体来说:轨迹优化可以把机器人起始状态和目标状态(抓住瓶子的位姿)定义为硬约束,然后进行求解中间位姿,这样的情况下,只要求解器能求解,那一定能达到最终目标,即抓住瓶子。
但是深度学习只能根据起始状态去预测未来动作,期望最终抓住瓶子(模仿学习利用loss,强化学习利用reward作为软约束),不能确保一定抓住苹果,但他会尽可能去学。
这时候如果环境变了,瓶子所处的位置变了,机器人能否抓住苹果完全依赖该模型是否良好的建立了苹果位置与机器人动作之间的因果关联。就算建立了,最后能否抓住也不一定,因为forward-predcition存在复合误差。

因此有约束优化和无约束优化的关键区别在于——
硬约束和软约束决定了最终目标是否能精确达成。
因此,本文作者从相反的方面来处理这个问题,即反向生成动作序列:
从关键帧动作开始,向后朝向初始状态生成动作序列,而不是以向前、逐步的方式预测动作。
关键帧动作编码了特定任务的目标,这提供了一个强大的结构性先验,以指导整个动作序列。
通过从目标向后显式生成动作,该方法加强了全局到局部的一致性,显著减少了复合误差并增强了分布变化下的泛化能力。
自回归框架+四个特殊设计
自回归框架
为了实现这种反向推理范式,同时保持端到端训练的可扩展性潜力,研究将整个反向生成过程统一到一个自回归框架中。

(1)采用源自C2F-ARM中关键帧的定义,关键帧被定义为手爪状态改变或关节速度接近零的时间步长。这种简单而有效的启发式方法捕获语义上的阶段转换(例如抓取完成或对象放置)。
(2)将目标表示为一个动作允许它与所有其他动作共享相同的嵌入空间,从而实现无缝的向后生成。
(3)我们在动作之间实施了一个反向因果依赖,产生了一个以目标为条件的推理链。这种反向推理链是我们框架的核心,它将轨迹分布建模为:

连续动作表征
离散化动作会引入量化误差,并在长序列自回归中不断累积。研究采用连续动作表示,以保留轨迹的细粒度结构和高保真度。
(1)通过可学习编码器将连续动作映射为潜在向量,替代传统的离散令牌嵌入。
(2)自回归解码时,潜在空间缺乏时序约束,编码误差会在多步预测中不断累积并放大。
(3)在训练中加入潜在一致性损失,强制模型在相邻时刻保持潜在向量的一致性,从而抑制误差扩散,提升生成稳定性。

动作分块预测
虽然后向自回归能有效传递高级目标意图,但未显式建模子轨迹内部的局部依赖。
(1)在训练中引入multi token prediction(MTP),联合预测短动作组块,以增强局部一致性并稳定训练。
(2)解码器的最后 K 层用于联合预测接下来 K 个token,以在一次前向传递中建模局部时间依赖。
(3)MTP引入了时间局部正则化,增强长期生成的稳定性,同时保留全局到局部的自回归结构。需要注意的是,MTP 仅在训练阶段开启,推理时移除。
动态停止
闭环执行要求模型在正确时刻停止,但连续动作空间中无离散的EOS标记。研究设计了基于与目标距离的停止准则,达到阈值时自动终止,减少过度生成并提升执行效率。
反向兼容时间集成
受ACT启发,研究提出一种反向兼容的变体:
(1)关键帧动作对齐:首先预测一组关键帧动作,并将其作为各自子轨迹的反向解码锚点;
(2)多条子轨迹融合:从每个关键帧向前推演,生成多个反向子轨迹;
(3)集成增强:将这些子轨迹的预测结果集成(如取加权平均),以提升关键帧动作的精度。

这样,每条完整轨迹都依赖于关键帧动作的准确性,复合误差被天然约束在关键帧误差范围内;集成步骤则进一步减小这一误差上界,从而有效减少闭环执行中的漂移和时间错位。
实验
仿真环境与平台
使用常见的仿真基准 RLBench(基于 CoppeliaSim + PyRep)进行评估,机器人为 7-DoF Franka Emika Panda,工作台上方布置四个摄像头(前视、左肩、右肩、腕部),RGB 图像分辨率 128×128。
基线方法
对比方法包括 ACT、Diffusion Policy(DP)和 Octo。ACT/DP 全部严格遵循 RLBench 的训练协议,Octo 则使用官方微调流程以保证公平性。
训练与评估流程
每个任务采集 100 条示例演示数据,仿真中仅用 variation 0 变体训练以节省成本;评估时对 60 个任务进行闭环测试,每个任务 25 条演示;另选 10 个常用任务与 Octo 及消融模型做深入对比。

1. 整体性能对比
成功率统计
在 10 个代表性任务上,CoA 平均成功率 75.6%,显著优于 ACT(48.8%)、DP(41.6%)和 Octo(64.4%),具体如表 1。
任务级提升
相较 ACT,CoA 在 81.7% 任务上实现性能提升,平均提升 +16.3%;相较 DP,在 80% 任务上提升 +23.2%。
空间泛化优势
在涉及大范围物体位置变化的任务中,CoA 的增益尤为显著,表明其对视觉-运动策略在空间分布漂移场景下的更强鲁棒性。

2. 空间泛化深入分析
成功率 vs. 空间方差
随着物体在工作区中放置分布方差增大,所有方法成绩都有所下降;但 CoA 的下降幅度最小(Pearson r = −0.168),ACT/DP 分别为 −0.247/−0.246,且 CoA 相对优势在高方差时更大。

内插/外推性能
以 “Push Button” 任务为例,CoA 在内插(训练分布)和外推(分布外)的成功率分别为 94% 和 48%,而 ACT 仅为 54%/8%,DP 18%/4%,进一步凸显逆向自回归对分布外场景的适应能力。

3. 消融研究
建模范式
Forward ordering(去掉目标锚定的顺序生成)成功率 66.8%;Hybrid ordering(兼具目标锚定但正向生成)仅 60.0%;验证了“目标锚定 + 反向自回归”二者协同的必要性。
多令牌预测头数
5 个 MTP 头最优(75.6%),过少或过多均降低局部与全局平衡能力。
潜在一致性 vs. 动作重构
用直接动作重构替代潜在一致性后,平均成功率骤降至 21.2%,表明潜在一致性正则在稳定自回归生成中至关重要。
时间集成策略
不采用反向集成时成绩为 66.0%,而使用后回升至 75.6%,凸显多条反向子轨迹汇聚的误差抑制效果

小结
Chain of Action 通过反向自回归建模解决传统自回归中的复合误差问题:
从任务目标关键帧向前生成动作序列,实现全局-局部一致性。
配合连续动作表征、动作分块预测、潜在一致性正则和反向时间集成等机制,显著提升了泛化能力与闭环稳定性,在高空间变化任务中表现出优于ACT、DP、Octo的综合性能。

全文总结
Dense Policy 和 Chain of Action 分别从两个方向革新自回归动作生成策略:
Dense Policy 借助层次结构和双向填充,实现更细致、更高效、更拟人的动作生成过程;
Chain of Action 从目标出发,逆向建构路径,减少复合误差并增强泛化性能。
它们代表了一种趋势:自回归不应再只是“按顺序预测下一步”,而应具备全局规划意识与结构化生成能力。从动作的局部一致性到目标导向的整体结构,两者的努力标志着自回归策略的范式升级,也为下一代通用机器人策略的可学习性与可靠性打开了新的可能。
未来,自回归的尽头可能不是一步一步地走完,而是像人一样,先看清远方,再一步到达。
编辑|无意
审编|具身君
参考文献:
1.Dense Policy: Bidirectional Autoregressive Learning of Actions
2. CHAIN-OF-ACTION: FAITHFUL AND MULTIMODAL QUESTION ANSWERING THROUGH LARGE LANGUAGE MODELS
 【深蓝具身智能读者群】-参观机器人:
【深蓝具身智能读者群】-参观机器人:
我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇



点击❤收藏并推荐本文
 扫码添加微信
扫码添加微信
- 点赞 (0)
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊





