


最强开源易主!阿里Qwen3重磅发布,数学碾压GPT-4o,想能超越Kimi-K2,直逼Claude 4,全球性能榜单再次被刷新
- 2025-07-23 15:16:10
阿里巴巴团队发布了其 Qwen3 系列的最新迭代版本:Qwen3-235B-A22B-2507。其公开的基准测试数据,表现堪称惊艳。

这究竟是一款怎样的模型?
Qwen3-235B-A22B-Instruct-2507 是阿里云 Qwen 团队在 2025 年 7 月推出的旗舰级大语言模型。
它采用先进的混合专家架构,总参数量高达 2350 亿,但每次推理仅激活 220 亿,实现了效率与性能的精妙平衡。
该模型在指令遵循、逻辑推理、文本理解、数学、科学、编码和工具使用等多个维度都进行了深度优化。
Qwen3-235B-A22B-Instruct-2507
经过与社区的深入交流和内部的慎重考虑,我们决定停止混合思维模式的探索。
未来,我们将分别训练指令模型和思维模型,以追求极致的性能。
今天,我们正式向所有人发布 Qwen3-235B-A22B-Instruct-2507 及其 FP8 量化版本。
Qwen 的研究人员自信地表示,新模型更智能、知识更渊博、能力更全面,并且在智能体任务上的表现远超以往。
模型核心参数
Qwen3-235B-A22B-Instruct-2507 的核心技术规格如下:
类型: 自回归语言模型 训练阶段: 预训练与后训练 参数量: 总计 2350 亿,激活 220 亿 非嵌入参数量: 2340 亿 层数: 94 注意力头: 64 个查询头 (Q),4 个键值头 (KV) 专家数量: 128 激活专家数: 8 上下文长度: 原生支持 262,144 tokens
非常有趣的是,就在月之暗面发布 Kimi-K2 的模型卡和技术报告后,Qwen 的这款模型就紧随而至。
请仔细审视这张图表,它揭示了重要的信息。
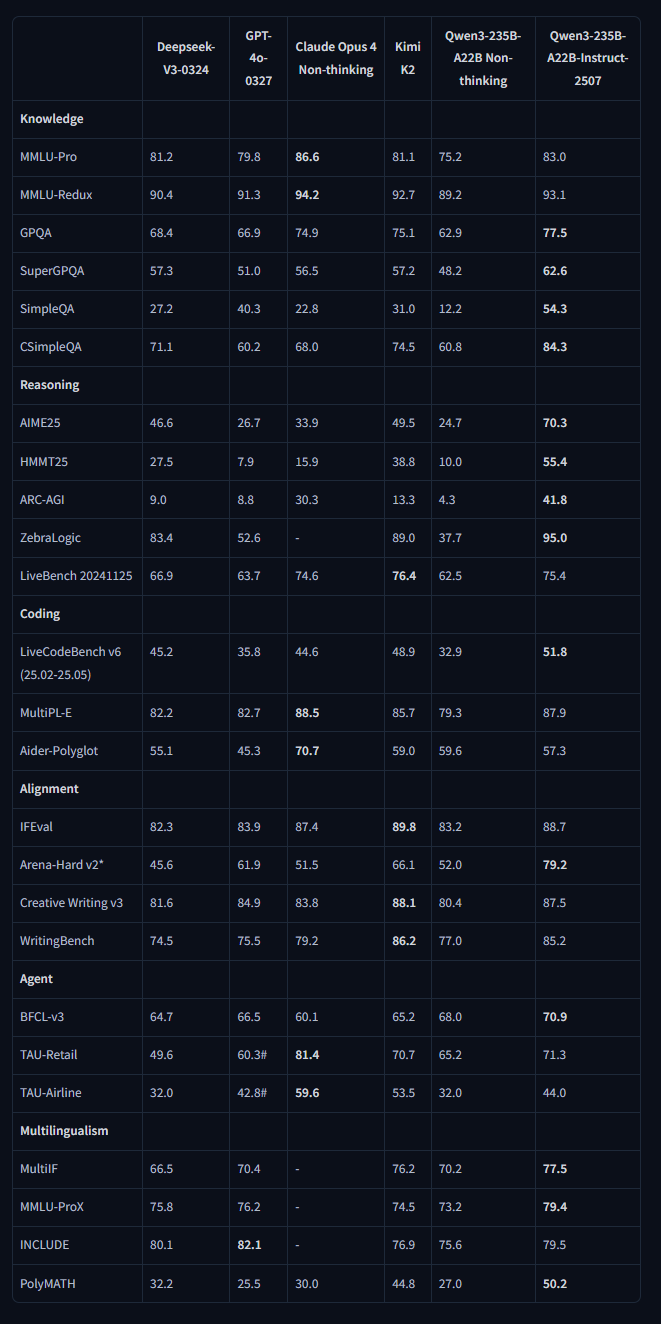
据我所知,这是 Qwen 团队首次将 ARC-AGI 基准测试纳入评测。
这个指标极好地反映了在 2025 年年中,中国的开源模型技术已经达到了非常领先的水平。
从 2023 年 4 月的通义千问到 2025 年 4 月的 Qwen 3,阿里巴巴的 Qwen 系列模型在全球科技和商业领域掀起了一波又一波的浪潮。
如果你持续关注开源 AI 领域,就会发现 Qwen 似乎在很长一段时间里,始终是行业的领军者或关键的开拓者之一。
新一代 Qwen3 的核心特性
模型多样性: 提供密集模型与混合专家模型,覆盖从 0.6B 到 235B 的多种参数规模。
双模式无缝切换: 在单一模型内,思维模式(处理复杂逻辑、数学、编码)与非思维模式(高效通用聊天)可无缝切换,适应不同应用场景。
推理能力飞跃: 在数学、代码生成和常识推理上,性能显著超越前代模型。
卓越的人类偏好对齐: 在创意写作、角色扮演和多轮对话中,提供更自然、更沉浸的交互体验。
顶尖的智能体能力: 能与外部工具高效协同,在复杂的智能体任务中,性能位居开源模型前列。
强大的多语言支持: 支持超过 100 种语言和方言,具备出色的多语言指令遵循和翻译能力。
迭代速度惊人的 Qwen
Qwen 的发布节奏展示了其惊人的迭代速度:
2025.07.21: 发布 Qwen3-235B-A22B-Instruct-2507,显著增强并支持 256K 长上下文。
2025.04.29: 发布 Qwen3 系列。
2024.09.19: 发布 Qwen2.5 系列,新增 3B, 14B, 32B 尺寸。
2024.06.06: 发布 Qwen2 系列。
2024.03.28: 发布首个 MoE 模型 Qwen1.5-MoE-A2.7B。
2024.02.05: 发布 Qwen1.5 系列。
Qwen3 与 Kimi-K2 的较量
这张 AI 生成的分析图提供了一个直观的对比,但请注意,这是基于 Qwen3 的旧版本,新模型的表现将截然不同。
阿里巴巴同时也是月之暗面的投资者,这意味着他们很可能掌握着中国顶尖 AI 实验室的大部分前沿技术。

此外,阿里巴巴与 01.AI(其部分人才源于此)和 Manus AI(已迁至新加坡)等公司也建立了特殊的合作关系。
Qwen3 在 2025 年的纸面实力
种种迹象表明,新版 Qwen-3 相较于前代是一次巨大的飞跃,在部分基准上甚至超越了像 Claude 4 这样的顶级闭源模型。
可以说,2025 年中国在 LLM 领域正以惊人的速度追赶美国,技术差距可能已缩短至 3-6 个月。而在开源模型领域,中国已经处于领先地位。
它原生支持 256k 的超长上下文,确保了强大的长文本理解能力。
Qwen3 的能力覆盖自然语言理解、文本生成、视觉、音频、工具使用、角色扮演和 AI 智能体等多个方面。
值得注意的是,该模型专注于非思维模式,致力于提供高效、通用的响应。
它在多语言任务、长尾知识覆盖面,以及处理主观和开放式问题时与用户偏好的对齐度上,都比前代有显著提升。
在与 GPT-4o、Claude Opus 4 和 Kimi K2 的对比中,Qwen3 展现出强大的竞争力,尤其在数学推理和编码基准上。
该模型基于 Apache 2.0 协议开源,并提供了 FP8 量化版本以降低部署门槛,可通过 Hugging Face、Qwen Chat 和 ModelScope 等平台进行访问。
新版本究竟强在何处?
2507 版本的核心改进
通用能力: 在指令遵循、逻辑推理、文本理解、数学、科学、编码和工具使用方面取得重大突破。
知识覆盖: 大幅增强了在多种语言下的长尾知识储备。
用户对齐: 在处理主观和开放式任务时,能更好地契合用户偏好。
长上下文理解: 进一步优化了 256K token 的长文本处理能力。
性能亮点速览
新模型在各大权威基准测试中均取得了卓越的成绩:
推理与数学
AIME25: 70.3% (性能领先) HMMT25: 55.4% (得分顶尖) ARC-AGI: 41.8% (推理能力卓越) ZebraLogic: 95.0% (逻辑推理能力出众)
编码
LiveCodeBench v6: 51.8% (参评模型中拔得头筹) MultiPL-E: 87.9% (多语言编码能力强悍)
知识与对齐
SimpleQA: 54.3% (事实准确性极高) Arena-Hard v2: 79.2% (用户偏好得分顶级) Creative Writing v3: 87.5% (创作能力优秀)
在AI霸权的全球竞赛中,阿里巴巴的存在感正变得前所未有的强大。
参考资料:
https://huggingface.co/Qwen/Qwen3-235B-A22B-Instruct-2507
https://modelscope.cn/models/Qwen/Qwen3-235B-A22B-Instruct-2507
https://github.com/QwenLM/Qwen3
https://discord.com/invite/CV4E9rpNSD
https://qwen.readthedocs.io/en/latest/
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
 扫码添加微信
扫码添加微信

- 点赞 (0)
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊







