


Deepmind 巨作!LLM 幻觉的三大发现
- 2025-07-28 18:27:00

论文题目:How do language models learn facts? Dynamics, curricula and hallucinations
论文地址:https://arxiv.org/pdf/2503.21676

创新点
研究发现语言模型在学习过程中经历了三个阶段:初始语言理解阶段、性能平台期以及知识获取阶段。在初始阶段,模型学习整体属性值分布;在平台期,模型性能停滞不前,这一阶段与注意力机制的形成相吻合;最后,模型开始获取个体特定的知识。
通过设计注意力修补实验,研究者们能够将参考模型在训练过程中产生的注意力模式应用于修改后的模型中,从而观察这些注意力模式对模型性能的影响。实验结果表明,随着参考模型训练的深入,其注意力模式对修改后的模型越来越有益,尤其是在平台期形成的注意力模式对后续学习至关重要。
研究发现数据分布的不平衡性对学习动态有显著影响。具体来说,不平衡的数据分布可以缩短平台期的持续时间,但可能导致过拟合。
方法
本文的主要研究方法是通过设计一个合成的事实回忆任务来深入研究语言模型在学习过程中的动态变化。研究者们首先改编了 Allen-Zhu 和 Li(2023)提出的合成任务,生成人工传记以测试事实回忆,使其适合于研究联想记忆的形成。在这个任务中,模型需要预测特定的属性值,这些预测的准确性被用来衡量模型的知识水平。通过精心设计这些合成传记,研究者们能够将模型对特定标记的预测能力归因于其获得的知识,并通过这些标记的性能高效地测量其知识。
合成传记数据集的数据生成过程

本图展示了用于训练的语言模型的合成传记数据集的生成过程。首先,生成一个包含多个个体(每个人都有一个独特的名字和六个属性:出生日期、出生地、大学、专业、公司和当前位置)的人口。然后,对于每个个体,从有限的模板池中为每个属性采样一个模板,用个体的信息填充这些模板,并将生成的句子随机排列并连接起来,形成一个完整的传记。图中还展示了如何通过预测属性值标记来衡量模型的知识,这些标记用蓝色突出显示。通过这种方式,研究者可以精确控制数据分布,并在模型训练过程中高效地测量其知识。
知识获取的三个阶段
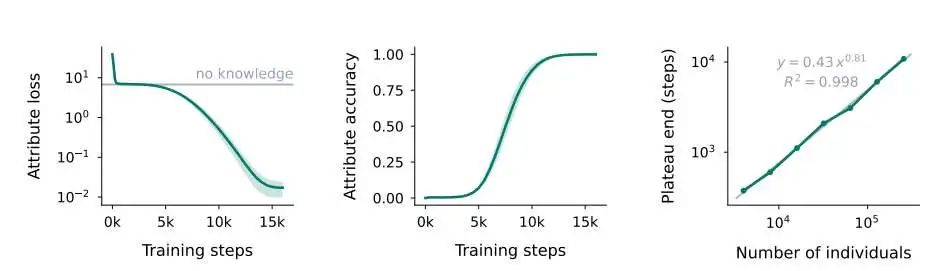
本图展示了语言模型在学习过程中的知识获取动态,呈现出三个阶段的一致模式。首先,在非常短的第一阶段,模型学习整体属性值分布。接着,性能进入一个平台期,此时模型的表现与没有个体特定知识的理想模型相当(对应于“无知识”基线和接近零的知识准确率)。这个平台期的持续时间几乎与个体数量成正比(右图)。最后,模型进入知识获取阶段,在这个阶段,它逐渐学习个体与属性之间的关联,知识开始显现。图中的结果是基于5个不同种子的平均值(±标准差)。图中还展示了平台期结束时的步数与个体数量之间的关系,表明平台期的长度与个体数量几乎成线性增长。
注意力机制在回忆中的作用
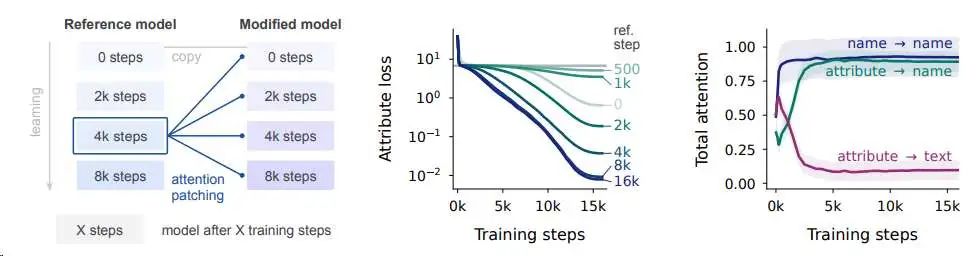
本图展示了注意力机制在回忆中的作用。左侧图展示了注意力修补实验的设计,研究者们训练了一个参考模型,并在训练过程中的不同阶段保存了参考检查点。然后,他们从头开始重新训练,但在整个训练过程中用参考模型产生的注意力模式替换了修改后的模型的注意力模式。中间图显示了随着参考模型训练的深入,其注意力模式对修改后的模型越来越有益,尤其是在平台期形成的注意力模式对后续学习至关重要。右侧图展示了在训练过程中,模型在预测第一个属性值标记时对名字标记的注意力变化,表明在平台期,模型对名字标记的注意力逐渐增加,这与注意力机制的发展相吻合。
实验结果

本表提供了本文实验中使用的默认超参数配置的详细信息,这些配置是研究者们在训练语言模型以研究其学习动态时所采用的标准设置。模型参数方面,模型拥有44M非嵌入参数,表明其规模适中,能够处理复杂的任务同时保持一定的计算效率。模型结构为8层,每层有8个注意力头,这样的设计使得模型能够捕捉到数据中的不同特征并进行有效的信息整合。模型的维度(残差流)为512,而多层感知机(MLP)的隐藏维度为2048,这种配置有助于模型在保持计算效率的同时,具备足够的容量来学习复杂的模式。键和值的维度为64,这一设置在注意力机制中较为常见,能够在保证计算效率的同时,提供足够的精度来处理长距离依赖关系。在训练设置上,模型总共训练16k步,使用128的批量大小,这表明研究者们在训练过程中注重平衡计算资源和模型性能。学习率调度器采用余弦调度器,没有预热阶段,最大学习率为4×10^-4,这种学习率策略有助于模型在训练过程中稳定收敛。权重衰减设置为0.1,这有助于防止模型过拟合,保持模型的泛化能力。
-- END --

关注“学姐带你玩AI”公众号,回复“2025大模型”
领取2025大模型创新方案合集+开源代码

 扫码添加微信
扫码添加微信
- 点赞 (0)
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊





