聊聊大模型推理系统之 MIRAGE:当KV Cache不够时,把模型参数“变”成缓存
- 2025-07-22 22:43:13

全文约 2000 字,预计阅读时间 5 分钟
在多租户大语言模型(LLM)推理服务中,如何在有限的 GPU 内存下高效处理长短不一、动态到达的请求,是当前产业落地的核心瓶颈。传统方案常因 KV Cache(键值缓存)内存不足而被迫进行计算重算或数据交换,导致响应延迟飙升。近期,一项名为 MIRAGE 的新技术横空出世,通过“参数重映射”机制,在真实场景下实现了高达 86.7% 的吞吐提升 和 99.3% 的尾部延迟降低。这一成果究竟如何实现?其背后的技术逻辑与行业意义又是什么?
核心看点
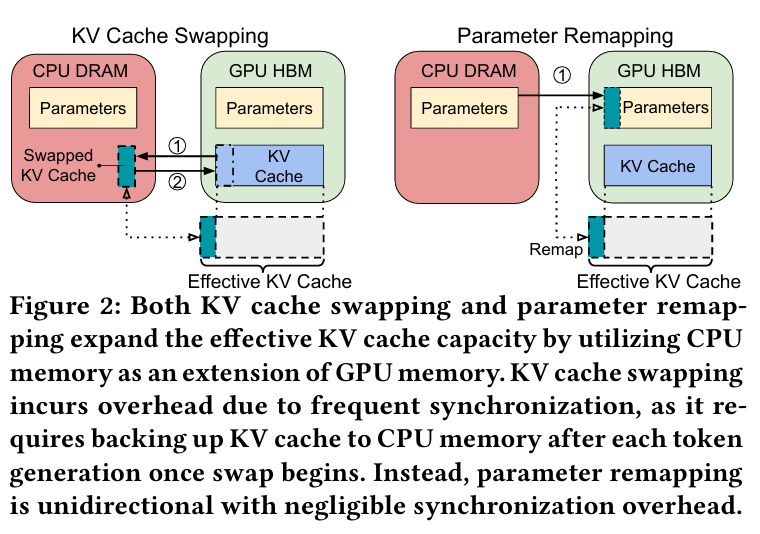
MIRAGE 提出了一种全新的 动态参数重映射(Dynamic Parameter Remapping)机制,从根本上优化了 LLM 推理中的内存使用效率。它不再将模型参数内存视为静态占用,而是将其作为可弹性调配的资源池,在运行时按需将其“重映射”为 KV Cache 内存,从而避免了代价高昂的 KV 缓存换出/换入操作。该技术不仅显著提升了系统吞吐与响应速度,更首次实现了对多租户场景的原生支持,尤其适用于 多智能体协作(Multi-agent Workflow)等新兴应用范式。
研究背景
在当前主流的 LLM 推理框架(如 vLLM)中,KV Cache 是生成过程中逐个 token 存储注意力状态的关键结构,其内存消耗随序列长度线性增长。然而,GPU 显存容量有限,当并发请求增多或序列变长时,极易出现显存溢出。现有解决方案主要依赖 PagedAttention 进行分页管理,但在极端负载下仍需通过 KV Cache Swapping 将部分缓存临时换出至 CPU 内存。这种双向数据迁移不仅耗时,还引入了严重的同步开销,尤其在多模型共存的 多租户环境 中,性能波动剧烈,尾延迟(P99 Latency)难以控制。
MIRAGE 的创新切入点在于:既然模型参数在推理阶段保持不变,为何不能将其暂时“借用”来扩展 KV Cache?特别是在多租户场景下,许多模型长期处于空闲状态,其占用的参数内存实为巨大浪费。由此,研究团队提出了“参数重映射”——一种单向、按层粒度的内存再利用策略,利用现代硬件(如 NVIDIA Grace Hopper Superchip)提供的高带宽 CPU-GPU 互联能力,实现高效的内存弹性调度。
核心贡献

方法创新:动态重映射引擎 + 智能层淘汰算法
MIRAGE 构建了一个独立的 动态重映射引擎,可无缝集成至任意 LLM 推理系统(如 vLLM)。其核心流程如下:当检测到 KV Cache 即将耗尽时,系统自动触发 remapping() 函数,优先从 非活跃模型 中逐层回收参数内存,并将其重新解释为 KV Cache 使用。由于参数本身无需修改,仅需从 CPU 加载至 GPU,因此数据传输为单向,大幅降低了同步开销。
为决定“哪些层应被重映射”,MIRAGE 设计了一种基于 循环执行特性 的淘汰算法。考虑到 LLM 解码是逐层循环的,算法优先选择未来最久才会被调用的层进行重映射。实验表明,采用 MRU(Most Recently Used)策略相比 LRU,可进一步减少 22.0% 的尾延迟,验证了其调度策略的优越性。

理论突破:最优分段传输时间证明
论文通过建立数学模型,分析了重映射过程中的计算与传输时间平衡问题。研究指出,系统总延迟受最慢的一段传输时间限制。通过公式推导,作者证明了当各层间的参数加载时间均等时,系统整体性能达到最优。这为动态调整重映射比例提供了理论依据,即应根据实时批处理大小和计算负载,弹性调节重映射层数,以最大化硬件利用率。
实证成果:全面超越现有方案

在真实多租户场景下的实验显示,MIRAGE 相比基线 vLLM:
尾部 TBT 延迟(P99 Time-Between-Tokens)降低 44.8%–82.5% 尾部 TTFT 延迟(P99 Time-To-First-Token)降低 74.8%–99.3% 吞吐量 提升 39.9%–86.7%
即使面对“长短请求混合”的极端负载(如长 1734 tokens vs 短 634 tokens),MIRAGE 仍能保持稳定,平均吞吐提升 **65.6%**,尾延迟显著下降。与同样利用高带宽硬件的 Pie 系统相比,MIRAGE 因避免了双向交换,在 TTFT 和吞吐方面表现更优,展现出更强的实用性。
行业意义
MIRAGE 的出现,标志着 LLM 推理系统从“静态内存分配”迈向“动态资源编排”的新阶段。它不仅为 高并发、低延迟 的 LLM 服务提供了新范式,更推动了 异构计算架构(如 CPU+GPU 超级芯片)在 AI 推理中的深度应用。其设计理念与国家倡导的 绿色计算 和 算力集约化 政策高度契合,有助于降低大模型部署成本,提升资源利用率。
更重要的是,MIRAGE 对 多租户、多智能体系统 的天然支持,使其成为构建复杂 AI 应用生态的理想基础设施。未来,该技术有望广泛应用于 智能客服集群、企业级 AI 助手平台 及 边缘端大模型服务,推动 AI 服务向更高效、更灵活的方向变革。
论文链接:MIRAGE: KV Cache Optimization through Parameter Remapping for Multi-tenant LLM Serving[1]
第一作者团队:本研究由多位深耕 AI 系统优化 与 大规模模型部署 领域的学者联合完成,相关成果已在 OSDI、ATC 等顶级系统会议上发表,展现了扎实的工程与理论功底。
MIRAGE: KV Cache Optimization through Parameter Remapping for Multi-tenant LLM Serving: https://arxiv.org/abs/2507.11507
-- 完 --
机智流推荐阅读:
1. 分享一个开源深度研究框架:DeepResearch Eco递归式工作流的设计与应用
2. 一起聊聊Nvidia Blackwell新特性之使用Thread Block Clusters的 GEMM
3. 上下文工程万字综述、Qwen“背题”疑云、反思性生成模型,HF本周30篇必读论文揭秘前沿趋势!
4. 从 PPO、DPO 到 GRPO:万字长文详解大模型训练中的三大关键算法
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 智能体 | Agent 技术交流群
 扫码添加微信
扫码添加微信
- 点赞 (0)
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊