


Zebra-CoT:开创性视觉思维链数据集问世,多模态推理准确率提升13%
- 2025-07-25 08:00:00
点击下方卡片,关注“具身智能之心”公众号
作者丨Ang Li等
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。

背景
人类在解决复杂问题时,常借助图表、草图等视觉辅助工具。训练多模态模型实现类似能力——即视觉思维链(visual CoT),面临两大挑战:一方面,现有视觉CoT性能欠佳,阻碍了强化学习的应用;另一方面,缺乏高质量的视觉CoT训练数据。
当前,尽管前沿多模态模型在视觉CoT方面取得一定进展,主要通过代理管道利用外部工具实现视觉编程,但具备 interleaved 文本和图像生成能力的模型,要么无法生成有用的推理视觉辅助工具,要么未在推理过程中进行固有的多模态生成训练,导致推理的强化学习方法难以实施。同时,专门模型虽在特定场景(如合成迷宫)展示了视觉CoT,但通用高质量视觉CoT的基础模型仍缺失,主要原因是缺乏大规模、多样化的 interleaved 文本-图像推理训练数据集。
核心创新点
提出Zebra-CoT,一个大规模(182,384样本)、多样化的数据集,包含逻辑连贯的 interleaved 文本-图像推理轨迹。 覆盖四大任务类别(科学问题、2D视觉推理、3D视觉推理、视觉逻辑与策略游戏),每个类别包含多个子领域,是首个在广泛领域提供多样化、逻辑连贯的多模态推理轨迹的数据集。 相比现有数据集,突破了单一任务限制(如VISUAL-COT仅关注视觉搜索),也克服了多数 interleaved 数据集语义对齐弱、无明确推理结构的问题,以高质量文本推理数据集的标准精心构建。
主要工作
数据集构建
覆盖范围:聚焦四类任务,具体包括:
科学推理:几何、物理、化学、算法问题(如竞争编程、图算法)等; 2D视觉推理:视觉搜索(图表、文本/文档、关系推理等)、视觉拼图; 3D视觉推理:3D多跳目标计数、具身CoT、机器人规划; 视觉逻辑与策略游戏:国际象棋、跳棋、迷宫、俄罗斯方块、密码等,如Figure 2所示。
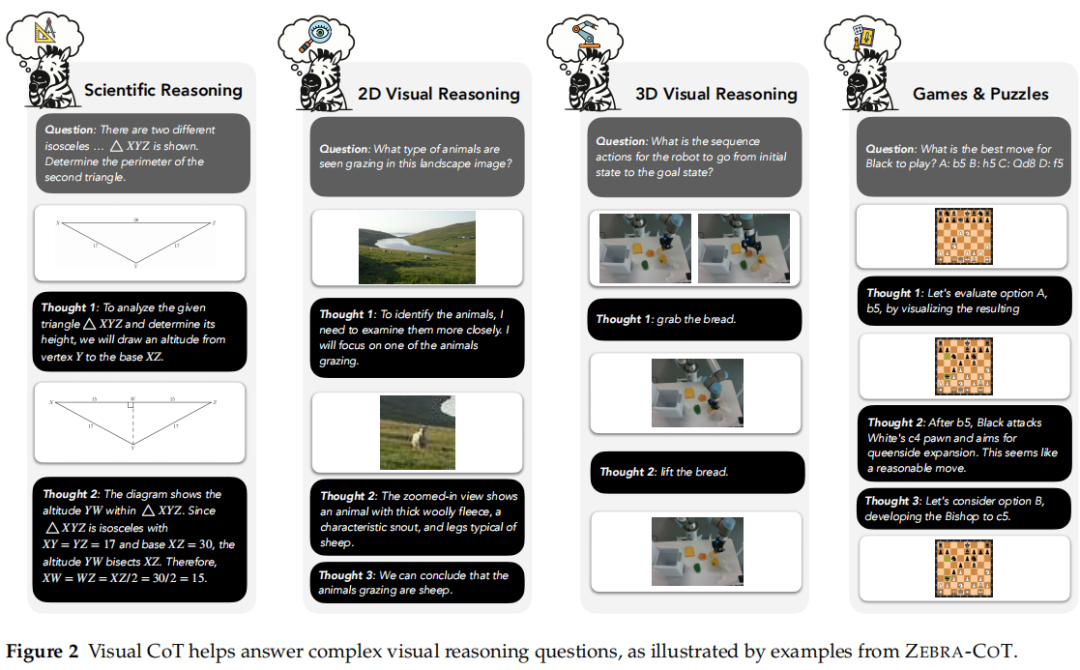
数据来源与处理:
真实世界数据:从在线资源(如数学、物理、编程、国际象棋比赛数据集)获取高质量问题,提取并清洗含文本和图像的原始推理轨迹,解决模态间逻辑连接不清晰、图像引用难解析等问题。 合成数据:通过生成图像或利用在线真实图像,结合推理模板创建示例,利用VLM填充模板占位符、增强推理轨迹,确保文本推理的多样性和表达性,流程如Figure 3所示。

规模与分布:总计182,384个样本,各子类别分布如Table 3所示,其中视觉逻辑与策略游戏占比36.7%,2D视觉推理占28.5%,3D视觉推理占21.7%,科学推理占13.2%。

模型微调与性能
Anole-Zebra-CoT:在Zebra-CoT上微调Anole-7B模型后,分布内测试集准确率从4.2%提升至16.9%,相对提升4倍;在7个视觉推理基准测试中平均提升4.9%,其中视觉逻辑基准提升达13.1%,如Table 2所示。

Bagel-Zebra-CoT:微调Bagel-7B模型后,其能够生成高质量的 interleaved 视觉推理链,原本该模型无法原生生成 interleaved 文本-图像输出,微调后实现了这一能力,展示了数据集在培养多模态推理能力上的有效性,示例见Figure 4。

相关工作
视觉思维链研究:现有工作多通过视觉编程生成图像(如Visual Sketchpad),或利用扩散模型生成中间图像辅助推理,但多为专门模型,缺乏通用基础模型,主要因缺乏大规模多样化的 interleaved 文本-图像推理训练数据。 视觉推理数据集:多数多模态推理数据集仅在输入中体现多模态,推理轨迹仍为纯文本;少数 interleaved 文本-视觉推理数据集(如VISUAL-COT)局限于单一任务;大规模 interleaved 文本-图像数据集(如OmniCorpus、MINT-1T)多为网页抓取,图像主要用于识别、 captioning 或作为文本推理的补充上下文,语义对齐弱,不适用于精细推理任务。 对比优势:Zebra-CoT在任务多样性、推理轨迹质量和逻辑连贯性上超越现有数据集,如Table 1所示。

局限
合成数据依赖模板生成,尽管通过VLM增强,文本推理的多样性和表达性仍可能受限。 数据集虽覆盖多领域,但部分子任务样本量较小(如几何占0.6%、竞争编程占0.7%),可能影响模型在这些子任务上的推理能力。 模型微调效果在部分子任务上提升不显著,甚至下降(如Anole-Zebra-CoT在EMMA的物理子任务上性能下降),需进一步优化数据集与模型适配性。
参考
[1]Zebra-CoT: A Dataset for Interleaved Vision Language Reasoning

声明:本文内容及配图由入驻作者撰写或合作网站授权转载。文章观点仅代表作者本人,不代表科技区角网立场。仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
点击这里
 扫码添加微信
扫码添加微信
扫码添加微信
- 点赞 (0)
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊





