


「ACL25」用“点赞/点踩”数据高效对齐大模型,性能媲美DPO,真实场景全面超越)
- 2025-07-24 22:39:02
💡 你是否曾好奇,ChatGPT 是如何“学会”回答得越来越贴心的?
答案是:人类反馈。
但问题来了——我们每天在聊天框里按下“👍”或“👎”,这些简单的二元信号,真的能教会一个千亿参数的大模型“什么是对,什么是错”吗?
传统观点认为:不能。
因为主流对齐方法如 DPO(Direct Preference Optimization)都需要成对的“好 vs 坏”回答,才能训练模型做出偏好判断。
然而,现实是——
用户几乎从不提供成对反馈,只愿轻点一下“点赞”或“点踩”。
收集成对偏好数据成本高昂,且难以规模化。
这就像让厨师凭“这道菜好吃”或“这道菜难吃”来改进菜品,却从不告诉他“和哪道菜比起来更好吃”。
直到现在,Kakao Corp 与 LBOX 联合提出了一种全新框架:Binary Classifier Optimization(BCO),首次从理论层面打通了“二元反馈”与“偏好优化”之间的鸿沟,并证明:
✅ 仅用“点赞/点踩”数据,也能实现媲美 DPO 的对齐效果
✅ 在真实用户评分数据上,BCO 全面超越 DPO 与 KTO
✅ 提出“奖励偏移”技术,揭示并修复了现有方法(如 KTO)的理论缺陷
🚀 这不仅是一次算法创新,更可能重塑未来大模型对齐的范式。
论文链接: https://aclanthology.org/2025.acl-long.93.pdf
一、现实困境:我们想要的 vs. 模型需要的
当你在使用 ChatGPT、Gemini 或 Claude 时,是否注意到右下角那个小小的“👍/👎”按钮?
这是最自然、最便捷的用户反馈方式。无需思考“哪个回答更好”,只需凭直觉判断“这个回答让我满意吗”。
但对 AI 研究者来说,这却是个“甜蜜的烦恼”:
💬 用户给的是“二元信号”(binary signal)
🧠 模型训练却依赖“成对偏好”(preference pair)
1.1 主流对齐方法的“三重门”
目前,大模型对齐的主流路径是 RLHF → DPO:
RLHF(Reinforcement Learning from Human Feedback)
三阶段流程:监督微调(SFT)→ 奖励建模(RM)→ 强化学习(RL)
❌ 三阶段训练复杂、资源消耗大、不稳定DPO(Direct Preference Optimization)
绕过奖励模型,直接用偏好数据优化策略
✅ 简洁高效,已成为工业界标配
❌ 仍需成对偏好数据(chosen vs rejected)

图1:在 UltraFeedback 和 Capybara 数据集上的胜率对比(GPT-4o 评测)
BCO(蓝)在多数配置下表现与 DPO(橙)相当,显著优于 KTO(绿)和 BCE(灰)。这表明:仅用二元信号,也能达到 DPO 级别的对齐性能。
1.2 那些“没人愿意做”的偏好标注
想象一下:
你要标注 1000 个问题的回答质量。
DPO 要求你对每对回答判断:“A 比 B 好吗?”
这需要你同时阅读两个回答,进行对比分析——认知负荷高、标注成本大。
而二元反馈呢?
只需看一个回答,点个赞或踩——几乎零成本。
但学界长期认为:
“二元信号信息量不足,无法支撑有效对齐。”
直到 2024 年,KTO(Kahneman-Tversky Optimization) 的出现打破了这一认知。
二、破局者登场:KTO 与它的“理论黑洞”
KTO 受前景理论(Prospect Theory)启发,提出仅用单个回答 + 二元标签即可对齐模型。
其核心思想是:
对“点赞”样本,最大化其“价值函数” 对“点踩”样本,最大化
其中 是一个动态参考点,通常设为 batch 内平均奖励。
KTO 看似优雅,但论文作者指出:它缺乏坚实的理论基础,且存在一个致命缺陷——
🔴 参考点被强制非负(clipped at zero),导致模型无法有效远离参考模型(over-regularization)

图4(b):KTO 训练过程中参考点 的演化(Llama-3.1-8B on Capybara)
可以看到, 在训练初期迅速坍缩至 0,此后再无变化。这意味着模型始终在“零奖励”附近震荡,无法有效学习到正负奖励的差异,导致对齐效果受限。
三、理论重构:二元分类器如何隐式优化 DPO?
Kakao 与 LBOX 的研究团队提出了一个颠覆性视角:
🌟 对齐大模型,本质上是在训练一个二元分类器
输入:(prompt, completion)
输出:是否值得“点赞”?1 或 0
损失函数:二元交叉熵(BCE)
但他们不止于此——他们从理论上证明:BCE 损失是 DPO 损失的上界。
3.1 核心定理:BCE 是 DPO 的上界
回忆 DPO 损失:
而 BCE 损失为:
论文提出:
定理 1:
$ \mathcal{L}{\text{DPO}} < \mathcal{L}{\text{BCE}} $
证明关键:利用一个不等式:
(见附录 A.1)
这意味着:最小化 BCE 损失,必然导致 DPO 损失下降。
换言之,用二元信号训练分类器,本质上是在优化偏好目标。
3.2 但差距在哪?误差项分析
虽然 BCE 是上界,但二者之间存在一个“误差项”:
当 很大(好回答得分高),第一项小 当 很小(坏回答得分低),第二项小
因此,随着训练进行,BCE 会逐渐逼近 DPO。
但问题来了:
能否主动缩小这个差距,让 BCE 更快、更紧地逼近 DPO?
答案是:能。
——这就是 Reward Shift(奖励偏移) 技术。
四、BCO 的核心创新:奖励偏移(Reward Shift)
作者提出:**将奖励整体平移一个偏移量 **,使正负样本的奖励分布更对称。
新损失函数为:
其中:
即:正负样本平均奖励的中点。
4.1 为什么这更优?
理论最优:作者证明(定理 4),当 时,误差项最小。 避免坍缩:不同于 KTO 将参考点 clip 到 0,BCO 的 是动态、无偏的,允许模型自由探索奖励空间。 梯度更均衡:KTO 的梯度中包含 ,在极端奖励处梯度消失;而 BCO 的梯度为 ,对低奖励样本仍保持学习能力。
4.2 实验验证:误差项真的变小了!

图3:UltraFeedback 数据集上误差项随训练步数的变化
BCO(蓝线)的误差项始终低于 BCE(灰线),证明奖励偏移确实有效缩小了与 DPO 的差距。
五、实验全景:BCO 在三大战场全面胜出
作者在三类数据集上验证 BCO:
成对偏好数据集(UltraFeedback, Capybara) 真实用户 Likert-5 评分数据(HelpSteer2) 主流对齐基准(MT-Bench, AlpacaEval, Arena-Hard)
5.1 战场一:成对偏好数据集
在 UltraFeedback 和 Capybara 上,将成对数据拆解为二元信号,训练 BCO。
结果如图1所示:
BCO ≈ DPO:性能几乎持平,证明 BCO 能达到 DPO 级别对齐 BCO > KTO:显著优于 KTO,尤其在大模型上 BCE < BCO:基础 BCE 损失性能较差,证明奖励偏移至关重要
这说明:即使有成对数据,BCO 也能通过二元信号实现同等甚至更优对齐。
5.2 战场二:真实用户评分数据(HelpSteer2)
这才是 BCO 的“主战场”。
HelpSteer2 包含真实用户对回答的 1-5 分评分(Likert-5 scale)。
作者将其转换为二元信号:
评分 ≥4 → “点赞” 评分 ≤3 → “点踩”
然后分别用 DPO(需构造偏好对)、KTO、BCO 进行对齐。
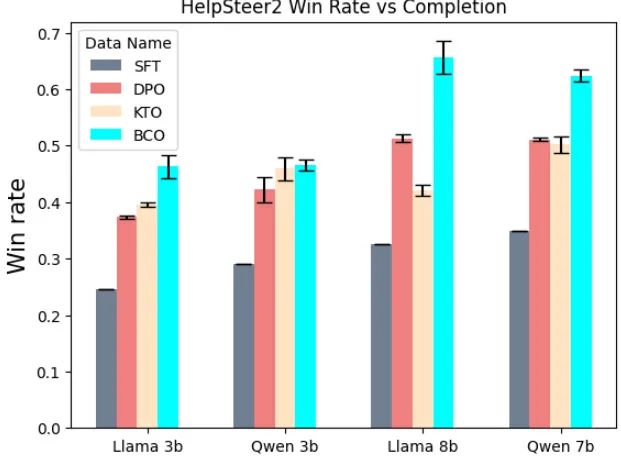
图2:HelpSteer2 数据集上的胜率对比
BCO(蓝)在所有模型上均显著超越 DPO(橙)和 KTO(绿)。
这证明:在真实用户反馈场景下,BCO 不仅可行,而且更优。
5.3 战场三:权威对齐基准测试
作者进一步在 MT-Bench、AlpacaEval 2.0 LC、Arena-Hard 上测试模型性能。
| 8.32 | 28.61 | 31.37 |
(Llama-3.1-8B 结果)
BCO 在 MT-Bench 和 Arena-Hard 上全面领先 KTO 在 AlpacaEval 上表现突出,但 Arena-Hard 上严重掉点,可能因生成过短(仅 432 token) BCO 生成长度(762)与 DPO(830)相近,说明其优化更均衡
📌 关键洞见:
KTO 倾向于生成短、安全的回答(避免被点踩),而 BCO 能在保持安全的同时生成更丰富内容。
六、深度洞察:为什么 BCO 更“健康”?
作者通过 KL 散度分析揭示了不同方法的本质差异。
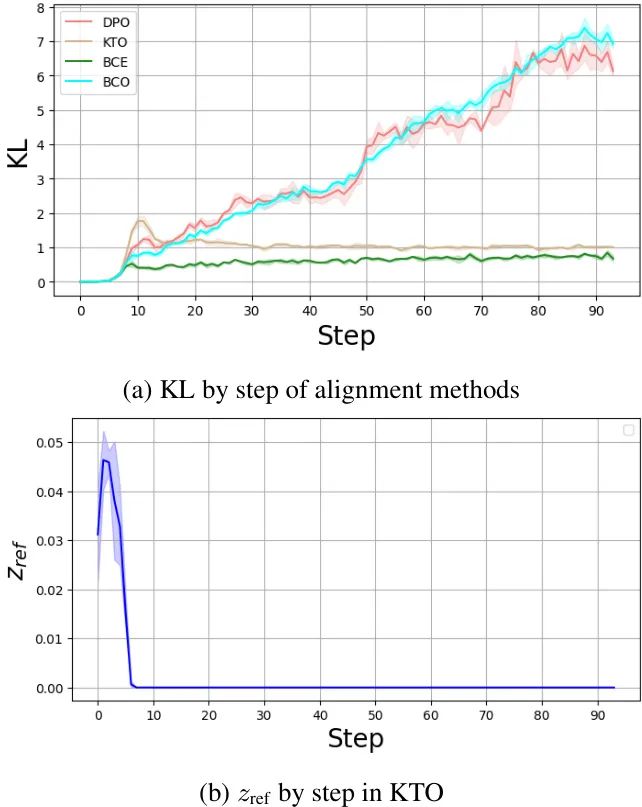
图4(a):不同方法下模型与参考模型的 KL 散度
DPO 与 BCO:KL 值较高,说明模型已充分偏离参考模型,学到新知识 KTO 与 BCE:KL 值较低,模型仍“粘”在参考模型上,学习不充分
这解释了为何 KTO 性能受限——其设计导致模型无法有效探索奖励空间。
而 BCO 通过合理的奖励偏移,既避免了过拟合,又实现了充分学习。
七、BCO 的哲学:从“对比”到“判断”的范式转移
BCO 的意义远不止一个新算法。
它代表了一种对齐范式的转变:
| 对比学习 | |||
| 二元判断 |
后者更符合真实用户行为,也更易于规模化收集。
未来,我们或许会看到:
模型在部署中实时学习用户“点赞” 个性化对齐:不同用户群体使用不同 多信号融合:点赞 + 点踩 + 停留时间 + 转发行为
八、局限与未来:BCO 的挑战与机遇
作者也坦诚指出 BCO 的局限:
缺乏真实二元反馈基准:目前仍用合成数据验证,需真实场景 benchmark 信息利用率低:5 分制评分被压缩为 1 bit,损失了细微偏好 上界优化风险:最小化上界 ≠ 最小化原目标,可能影响泛化
但这些正是未来方向:
构建真实二元反馈数据集 设计多级分类器(1-5 分 → 5 类) 探索 tighter bound 或直接优化方法
九、结语:大模型对齐的“平民化”之路
BCO 的出现,让我们看到:
对齐大模型,不必再依赖昂贵的专家标注。
普通用户的每一次“点赞”,都是一次有效的教学。
这不仅是技术进步,更是民主化 AI 的一步。
Kakao 与 LBOX 用严谨的数学证明告诉我们:
那些看似简单的“👍”和“👎”,
其实蕴含着足以塑造智能的强大力量。
未来,或许每个用户,都是大模型的“隐形教师”。
🚀 BCO,让每一次点击,都更有意义。
📌 论文信息
标题:Binary Classifier Optimization for Large Language Model Alignment
作者:Seungjae Jung♢, Gunsoo Han♢, Daniel Wontae Nam♢, Kyoung-Woon On♣
单位:♢ Kakao Corp, ♣ LBOX
链接:https://aclanthology.org/2025.acl-long.93.pdf
💬 你如何看待“点赞即训练”这一范式?欢迎在评论区分享你的观点!
 扫码添加微信
扫码添加微信
- 点赞 (0)
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊





