各类任务上超越π0!字节跳动推出大型VLA模型GR-3,推动通用机器人策略发展
- 2025-07-22 18:00:00

编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
GR-3的性能与优势
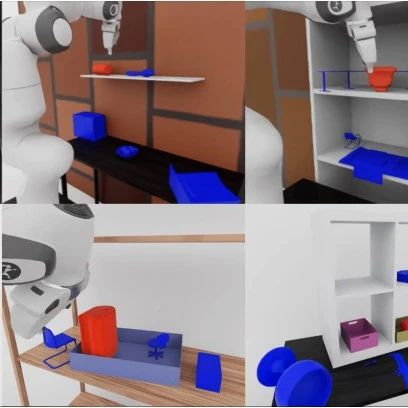
GR-3是字节跳动(ByteDance Seed)研发的大型视觉-语言-动作(VLA)模型,旨在推动通用机器人策略的发展。该模型能根据自然语言指令、环境观察和机器人状态,生成动作序列控制双臂移动机器人,在新物体、新环境和抽象指令的泛化能力、少量人类轨迹数据的高效微调,以及长周期和灵巧任务的执行上表现卓越。
这些能力通过多维度训练方案实现:包括与网络级视觉语言数据的协同训练、基于VR设备采集人类轨迹数据的高效微调,以及机器人轨迹数据的有效模仿学习。此外,还推出了ByteMini——一款具备卓越灵活性与可靠性的多功能双臂移动机器人,与GR-3结合可完成多样化任务。大量真实场景实验表明,GR-3在各类挑战性任务上均超越当前最先进的基线方法π0。我们期待GR-3能推动通用机器人技术的发展,最终实现辅助人类日常生活的目标。

文章首发于具身智能知识星球,更多内容欢迎加入我们的具身社区,近2000人啦!

GR-3核心能力与定位
GR-3本质是一个大规模视觉-语言-动作(VLA)模型,它的核心价值在于解决传统机器人"认不全、学不快、做不好"的三大痛点:
泛化能力:能应对从未见过的物体(如新型餐具)、陌生环境(如从厨房到会议室)和抽象指令(如"把最大的水果放进盒子")。 高效适配:仅需少量人类演示数据(如用VR设备录制的操作视频),就能快速学会新技能,大幅降低适配成本。 复杂任务处理:在长周期任务(如餐桌清理)和精细操作(如衣物悬挂)中表现稳定,尤其擅长双手协同和移动作业。
为实现这些能力,GR-3采用"数据驱动+架构优化"的双路径设计:一方面通过多源数据融合学习通用知识,另一方面通过轻量化结构设计保证实时控制。这种设计让它既能理解"把带触手的动物放进纸箱"这类抽象指令,又能实际完成布料折叠等需要精细感知的操作。
技术架构:从感知到Action的全链路设计

1)模型核心结构
GR-3采用端到端的VLA架构,整体分为"感知理解"和"动作生成"两大模块:
感知层:基于预训练视觉语言模型(Qwen2.5-VL-3B-Instruct)处理图像和文本,能同时理解camera画面(如识别"红色杯子")和语言指令(如"把杯子放到托盘上")。 动作层:通过动作扩散Transformer(DiT)生成连续动作序列,控制机器人的19个自由度(包括双臂和移动底座),确保动作流畅且精准。
模型总参数达40亿,为平衡性能和效率,动作生成模块的层数仅为感知模块的一半,并通过KV缓存复用感知结果,大幅提升推理速度。
2)关键技术创新
流匹配动作预测:借鉴流体动力学思想,将动作生成视为"从随机噪声逐步优化至目标动作"的过程,比传统方法更稳定,尤其适合连续控制场景(如布料拉扯)。
RMSNorm稳定性优化:在模型关键层添加归一化处理,解决训练中常见的不稳定问题,使指令遵循准确率提升约30%。
任务状态感知:通过"进行中/已完成/无效"三种状态标记,让机器人能判断指令可行性(如"把不存在的刀放进篮子"时会拒绝执行),避免无效操作。
这些设计让GR-3既能精准执行"把胡椒移到橙子旁"这类具体指令,也能处理"整理桌面"这类需要自主规划的长周期任务。
训练方案:多源数据的协同学习
GR-3的强大能力源于独特的"三位一体"训练策略——融合机器人轨迹、视觉语言数据和人类演示,实现"从通用到专用"的渐进式学习。

1)机器人轨迹模仿学习
通过真实机器人采集的操作数据(如拾取、放置、移动等),让模型掌握基础物理交互能力。为保证数据质量,团队开发了智能调度系统:
自动生成任务组合(如"拿起杯子+放到抽屉") 控制环境变量(如光线、背景) 过滤无效轨迹(如操作失败的记录)
训练中采用"最大似然估计"目标,让模型模仿专家动作,同时通过"随机替换指令"的反例训练,强化对语言指令的关注(如故意输入无效指令,训练模型识别并标记"无效"状态)。
2)视觉语言数据联合训练
为突破机器人数据的局限,GR-3与海量互联网视觉语言数据(如图片+描述、视觉问答)联合训练。这些数据涵盖:
图像理解(如"描述图片内容") 语义推理(如"哪个物体能装水") 空间关系(如"杯子在盘子左边")
这种训练让模型获得"常识"——例如从未见过"章鱼玩偶",但能通过"带触手的动物"这一描述找到目标。实验显示,联合训练使模型对新物体的识别成功率提升约40%。
3)人类轨迹少样本微调
针对全新场景(如操作特殊工具),GR-3支持用人类VR演示快速适配:
数据采集:人类通过VR设备演示动作(如"折叠衬衫"),每小时可生成450条轨迹,效率是传统机器人采集的1.8倍。 迁移学习:仅需10条演示数据,就能让模型掌握新物体操作(如特殊形状的容器),成功率从57.8%提升至86.7%。
这种方式避免了大量机器人试错,特别适合家庭、办公室等个性化场景。
硬件载体:ByteMini机器人设计

GR-3的落地依赖专为其开发的ByteMini双臂移动机器人,这款硬件在灵活性、可靠性和易用性上做了针对性优化:
1)核心设计亮点
灵巧操作:7自由度机械臂采用"球形腕关节",能像人类手腕一样灵活转动,解决传统机器人在狭小空间(如抽屉内)操作受限的问题;肘部可大幅内收,使双臂能在胸前完成精细协作(如扣纽扣)。
稳定移动:全向移动底座+升降机构,既能在光滑地面平稳滑动,也能调节高度适应不同操作台;采用准直接驱动(QDD)电机,动作响应快且力控精准(如轻握鸡蛋不破碎)。
感知能力:头部和双腕配备RGBD相机,近处靠腕部相机观察细节(如布料纹理),远处靠头部相机定位目标(如餐桌另一端的盘子)。
2)系统控制优化
为配合GR-3的实时控制需求,机器人采用:
全身柔顺控制:自动调整关节角度,避免动作卡顿或碰撞(如手臂碰到障碍物时自动避让)。 轨迹优化:通过算法平滑动作曲线,减少机械冲击(如移动底座启动和停止时不会晃动)。
这些设计让机器人能在家庭、办公室等真实场景中稳定作业,续航可达10小时以上。
实验验证:三大核心任务挑战
在真实环境中设计了三类高难度任务,全面测试GR-3的能力,并与当前最优方法对比。

1)通用拾取放置任务

测试目标:验证模型对新物体、新环境和抽象指令的适应能力。
场景设置:
基础环境:训练过的熟悉场景 新环境: checkout柜台、会议室等陌生场景 新指令:含空间关系("把左边的可乐放进盒子")或常识("把带触手的动物放进盒子")的指令 新物体:45个训练中未见过的物品(如特殊造型的玩具) 关键结果:
在新环境中,GR-3成功率仅比熟悉环境下降5%(下降20%),显示强环境适应性。 新指令理解上,GR-3成功率77.1%(仅40%),能准确处理"最大物体""左边物品"等抽象描述。 通过10条人类VR轨迹微调后,新物体操作成功率从57.8%提升至86.7%。
2)长周期餐桌清理任务

测试目标:验证长流程任务的规划和执行能力。
任务要求:打包食物→收纳餐具→清理垃圾,需自主规划多步动作。
场景变体:
多物体:同类型餐具(如5个杯子)需全部收纳 多目标:餐具需分放到不同容器 新目标:餐具放入训练中未搭配过的容器(如叉子放进垃圾桶) 无效指令:要求移动不存在的物品(如"把蓝色碗放进盒子"但桌上没有蓝色碗) 关键结果:
整体任务进度:GR-3达89%(仅62%),尤其擅长处理多步骤衔接。 无效指令识别:GR-3拒绝执行率97.5%(仅53.8%),避免无意义操作。 ablation实验显示:去除RMSNorm后,新目标适应率下降40%;去除任务状态标记后,无效指令识别率下降50%。
3)灵巧衣物操作任务
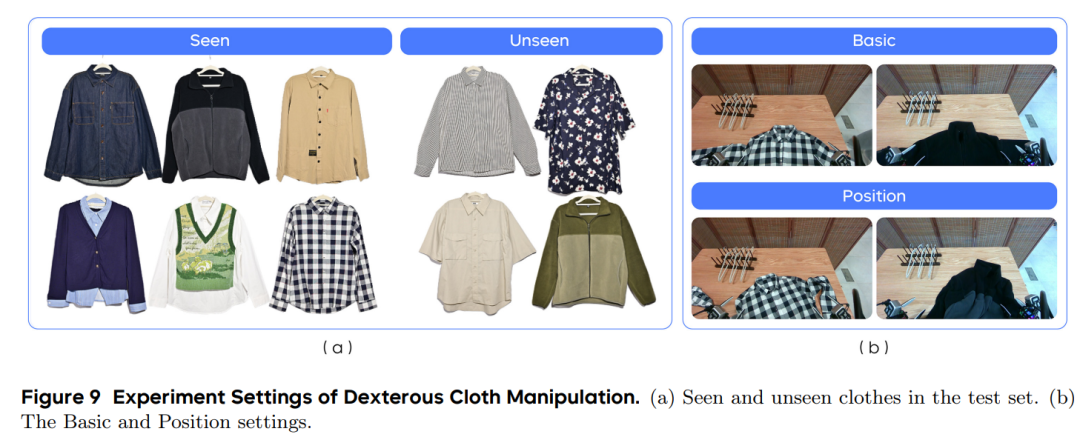
测试目标:验证对柔软变形物体的控制能力(机器人领域公认难题)。
任务要求:拿起衣架→将衣物(T恤、衬衫等)挂到衣架上→挂到晾衣杆。
场景变体:
熟悉衣物:训练过的款式 新衣物:未见过的款式(含短袖,训练中均为长袖) 复杂姿态:衣物褶皱或摆放角度刁钻 关键结果:
基础任务成功率:GR-3 86.7%( 61%),尤其在"套衣领"这一难点步骤表现更稳定。 新衣物适应:GR-3成功率75.8%(仅42%),能通过视觉判断衣物结构。 失败分析:主要失败点是衣架滑落(占失败案例的60%),未来需优化抓取力控。
参考
[1] GR-3 Technical Report.


 扫码添加微信
扫码添加微信
- 点赞 0
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊