


NVIDIA最新!GraspGen:基于扩散模型的六自由度抓取生成框架
- 2025-07-22 08:00:00

点击下方卡片,关注“具身智能之心”公众号
作者丨Wentao Yuan等
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
概述
抓取是机器人的核心技能,但现有基于学习的6自由度抓取方法仍存在泛化能力不足的问题——难以适应不同机械结构和真实复杂场景。GraspGen正是针对这一挑战提出的框架,它将物体中心的抓取生成过程建模为迭代扩散过程,结合DiffusionTransformer架构提升抓取生成能力,并搭配高效判别器对采样抓取进行评分和过滤。更重要的是,其创新的“生成器上训练”策略大幅提升了判别器性能,同时通过新发布的大规模模拟数据集,实现了对不同物体和夹具的适配。
核心方法
扩散生成器:建模6自由度抓取分布
GraspGen将6自由度抓取生成建模为SE(3)空间中的扩散过程(SE(3)即三维欧氏空间中的旋转和平移群)。与传统能量基模型(如SMLD)相比,采用的Denoising Diffusion Probabilistic Model(DDPM)计算更快、实现更简单。
平移归一化:由于平移范围依赖物体尺度,通过数据集统计计算归一化系数:
其中是物体正抓取姿态的平移分量,避免了人工设置或网格搜索的低效。
对象编码:采用PointTransformerV3(PTv3)作为骨干网络,将非结构化点云转换为结构化格式后输入Transformer,规避了传统点云处理中近邻球查询的瓶颈,相比PointNet++减少5.3mm平移误差,提升4%召回率。
扩散网络:如图2所示,噪声预测网络以点云和抓取姿态为输入,通过10步去噪生成抓取(远少于图像扩散的数百步,因抓取维度更低)。训练损失为预测噪声与真实噪声的L2损失:,其中为噪声预测网络,为物体点云。
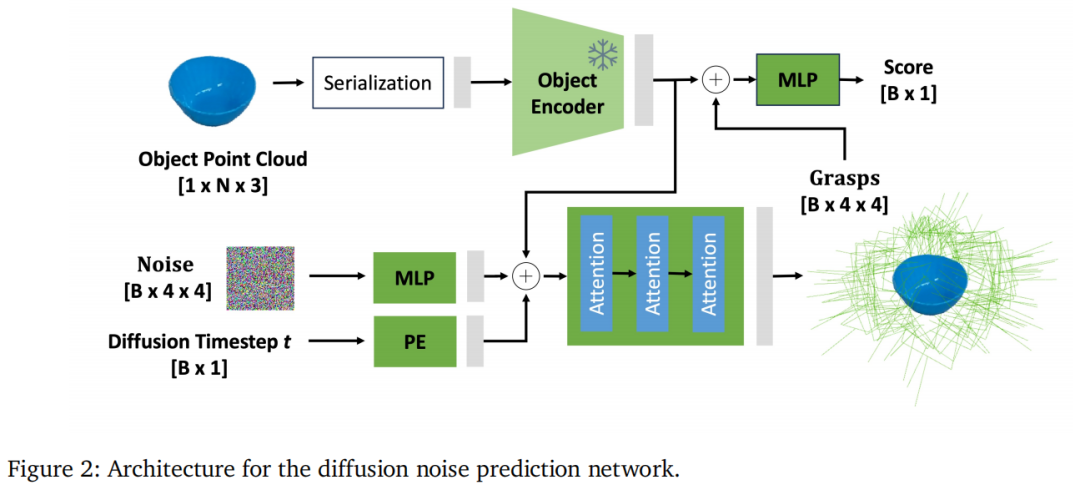
判别器:高效评估与生成器上训练
生成模型易产生假阳性抓取,需判别器过滤。GraspGen的判别器设计有两大创新:
高效评估:复用生成器的对象编码器,通过MLP结合对象嵌入与SE(3)格式的抓取姿态,输出成功概率(sigmoid得分)。相比传统将抓取姿态转换为点云输入的方法,内存使用减少21倍。
生成器上训练:传统判别器依赖离线数据集,但扩散模型生成的抓取分布与离线数据存在偏移(如图6左所示,正负样本的Earth-Movers Distance非零)。为此,用生成器在训练集上生成约7K物体×2K抓取/物体的数据集,通过模拟器标注后用于训练判别器,使其识别生成器的失败模式(如碰撞、远离物体的抓取)。

数据集
为支撑泛化能力,发布了含5300万抓取的模拟数据集,特点包括:
覆盖范围:包含Franka Panda、Robotiq-2f-140、吸盘(30mm)三种夹具,每种约1700万抓取;物体来自Objaverse(与LVIS类别重叠,共36366个网格模型)。
生成方式:在Isaac模拟器中,每个物体采样2K抓取姿态,通过摇晃测试判断成功(摇晃后保持稳定接触则为正样本);吸盘夹具的成功与否通过解析模型判断。
实验结果
模拟实验:全面超越基线
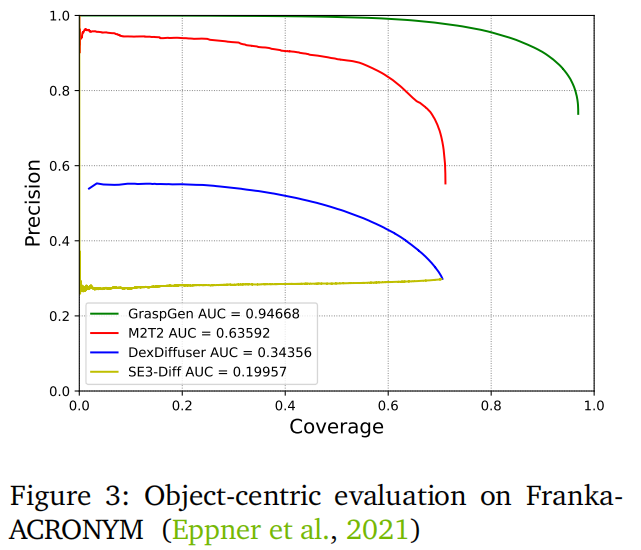
单物体场景:在ACRONYM数据集上,GraspGen的精度-覆盖率曲线AUC超过基线48%(如图3所示)。带判别器的方法(GraspGen、DexDiffuser、M2T2)均优于纯生成模型SE3-Diff,印证判别器的重要性。
clutter场景(FetchBench):如图4所示,在100个场景×60任务中,GraspGen的任务成功率和抓取成功率均为最优,超过Contact-GraspNet 16.9%、M2T2 7.8%。

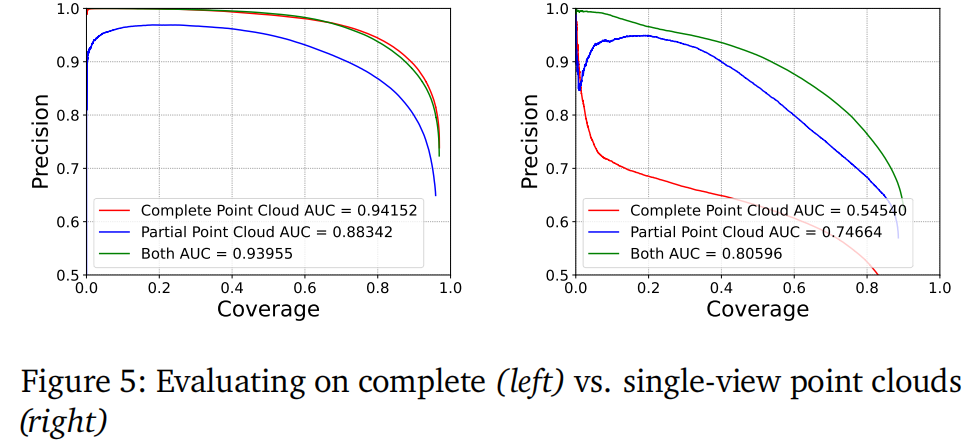
遮挡鲁棒性:如图5所示,混合训练(50%完整点云+50%单视图点云)使模型在两种输入下均保持高性能,解决了传统方法对输入类型敏感的问题。
生成器上训练的有效性
如图6右所示,仅用生成器数据训练的判别器AUC达0.947,显著高于仅用离线数据的0.886,证明其能更好过滤假阳性。
多夹具与真实机器人表现
多夹具泛化:在Robotiq-2f-140和吸盘夹具上,GraspGen的AUC远超M2T2和SE3-Diff(如Robotiq的AUC为0.68873,M2T2仅0.24265,如图9所示)。

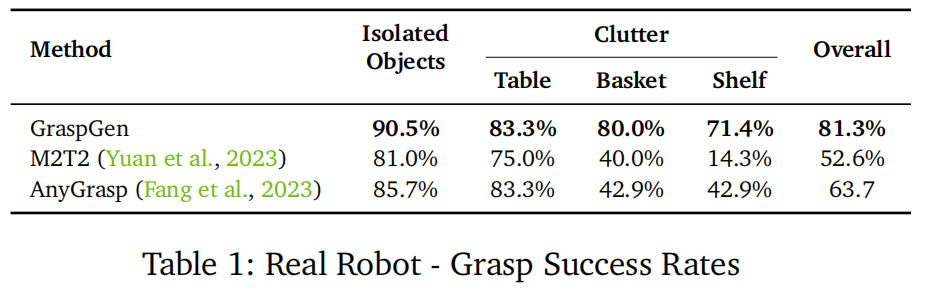
真实机器人实验:在UR10机械臂上,GraspGen在孤立物体、桌面 clutter、篮子、架子四种场景中整体成功率81.3%,超过M2T2(28%)和AnyGrasp(17.6%),尤其在复杂的架子和篮子场景中优势明显(如表1所示)。
结论与局限
GraspGen通过扩散模型与生成器上训练的判别器,实现了6自由度抓取在泛化性、效率上的突破,在模拟和真实场景中均达SOTA。但存在局限:依赖深度传感和实例分割质量,对立方体物体表现较差,训练需约3K GPU小时(NVIDIA V100),未来需进一步优化计算成本与场景适应性。
参考
[1]GraspGen: A Diffusion-based Framework for 6-DOF Grasping with On-Generator Training

 扫码添加微信
扫码添加微信
- 点赞 0
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊





