AI绘画翻车元凶找到了!新神器IMBA损失,在线轻调立竿见影,效果炸裂!清华&快手出品
- 2025-07-22 00:01:00
如您有工作需要分享,欢迎联系:aigc_to_future
作者:Yukai Shi等
 论文链接:https://arxiv.org/pdf/2507.13345
论文链接:https://arxiv.org/pdf/2507.13345

亮点直击
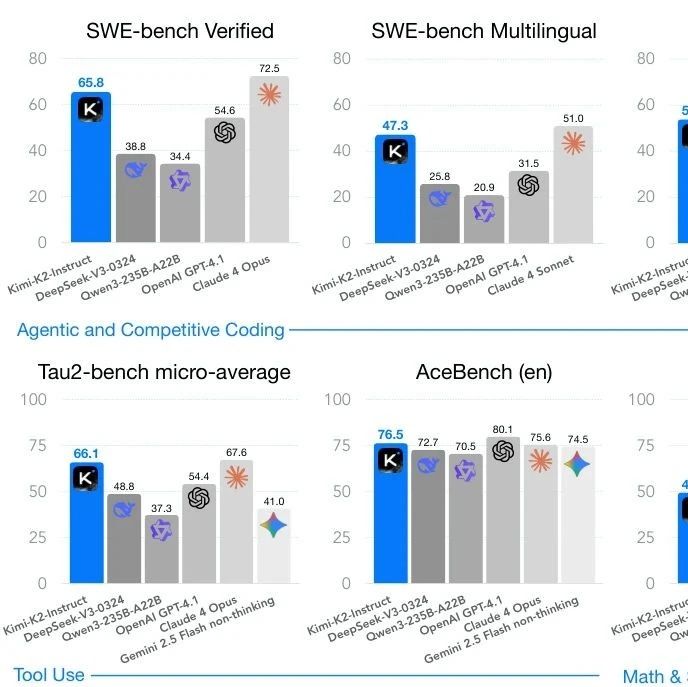
展示了当模型和训练数据达到足够规模时,数据分布成为模型概念组合能力的主要决定因素。 提出了概念级均衡方法(IMBA 损失),用于解决训练数据中概念分布不均的问题。该方法易于实现、成本低,并适用于不同模型。在三个基准测试上取得了有前景的结果。 引入了一个新的概念组合基准测试集,名为Inert-CompBench。该基准包含了在开放世界场景下对组合构成挑战的概念,作为对现有基准的补充。
总结速览
解决的问题
在视觉生成任务中,复杂概念的响应与组合不稳定、易出错,尤其在开放世界场景下表现不佳。 当前对此类问题的研究仍然不足,缺乏对概念响应不佳的成因的深入分析。 训练数据中存在概念分布不均衡的问题,影响模型的组合泛化能力。
提出的方案
通过精心设计的实验,系统性地分析复杂概念响应不良的因果因素。 提出一种概念级均衡损失函数(IMBA loss),用于自动平衡训练过程中不同概念的学习强度。 设计并发布一个新的复杂概念组合基准测试集:Inert-CompBench,用于评估模型在复杂组合场景下的表现。
应用的技术
IMBA loss:一种在线计算的损失函数,无需离线数据处理,便于集成,仅需极少量代码改动即可应用于不同模型。 大规模模型与训练数据分析:揭示数据分布对概念组合能力的决定性作用。 新基准测试集(Inert-CompBench):涵盖多种开放世界下难以组合的复杂概念,补充现有评测体系。
达到的效果
在 Inert-CompBench 以及两个公开测试集上,显著提升了基线模型的概念响应能力。 所提出方法具有良好的通用性与易用性,在保持低实现成本的同时,取得了高度竞争力的性能表现。 为未来研究复杂概念组合机制提供了实验工具与理论依据。
概念组合的因果因素
本节旨在弥合合成实验与文本-图像生成任务之间的差距,进一步探索影响概念组合能力的因果因素。在文本-图像数据集上进行受控实验,重点研究三个关键因素的影响:模型规模、数据集规模和数据分布。
实验设置 为了保证数据集一致性并提高训练效率,对开源数据集 [45] 进行了重新标注,构建了一个更高质量的数据集,因为现有的开源预训练模型,如[2, 12, 33] 并未公开其训练数据。本文数据集包含 3100 万 对文本-图像样本,平均文本长度为 100 个词,共包含 2 万个名词概念,其分布如图2所示。
为了确保结论的普适性,我们使用了一个 基于 DiT 的扩散模型,未进行任何特殊设计。为了准确评估模型的概念组合能力而非图像清晰度,除了使用 CLIP 分数外,还引入了基于 VLM的 VQA 机制作为定量指标。
检测每个标题中的所有名词概念,并进行两两配对,要求 VLM 回答以下问题以验证图像中概念的存在及其关系:
“图像中是否存在概念 A?” “图像中是否存在概念 B?” “概念 A 和 B 之间的关系是否与标题一致?”
当所有回答均为 “是” 时,判定该样本为组合成功。
模型规模 在生成任务中,模型能力也遵循扩展规律(scaling law),即参数越多的模型通常具有更强的生成能力。我们保留 Stable Diffusion的 VAE 模块不变,在同一个 3100 万样本的数据集上,从头训练参数量分别为 1亿、2亿、5亿和10亿 的扩散模型,唯一差异为网络的 block 数和通道数。
在 LC-Mis 基准测试集上评估模型的 CLIP 分数和组合成功率,结果如下图3所示。实验发现:
当模型规模超过 2亿参数 后,概念组合能力的提升速度明显减缓; 这表明:当模型规模相对于数据集达到一定程度后,模型规模不再是限制概念组合能力的因果因素。

数据集规模 需要明确的是,此处所指的数据集规模仅指单一概念的样本数量,不涉及不同概念之间的共现频率或覆盖范围,后者被归类为数据分布因素。
为了控制数据分布不变,从数据集中选取从未共现过的两个概念组成组合对,并提取包含这两个概念的样本,构建一个分布不均衡的新数据集。然后保持两个概念的样本比例不变,从中采样出两个不同规模的子集,保证它们大致遵循相同的分布。
接着,使用一个从未见过这两个概念的模型进行微调训练(supervised finetuning),训练步数为 2 万步。为每个概念组合生成 25 个标题,用于 VQA 评估。
为消除随机性,选取了两个不平衡分布的概念组合对:
“钢琴-潜艇”(piano-submarine),分布比例为 100:1; “火山-双胞胎”(volcano-twins),分布比例为 10:1。
如下图4所示,尽管数据集规模扩大了5倍,但概念组合能力并未显著提升。在下表1中也可以看到,失败案例的数量并没有随着数据集规模的增加而减少。

因此,仅仅增加数据规模而不改变数据分布,并不能提升模型的概念组合能力。
数据分布在实验中人为构建了平衡与不平衡的数据集。具体做法如下:
从数据集中选取两个从未共现过的概念组成概念对,并提取包含这两个概念的样本,构建一个分布不均衡的数据集,作为不平衡数据集。随后,对高频概念的样本进行下采样,构建一个分布平衡的数据集。
依然使用 “钢琴-潜艇”(piano-submarine)和 “双胞胎-火山”(twins-volcano) 作为概念组合对进行对比:
在不平衡数据集中,它们的样本比例分别为 100:1 和 10:1; 在平衡数据集中,样本比例均为 1:1。
如上图4和上表1所示,尽管不平衡数据集包含了平衡数据集中的所有样本,但在平衡数据集上训练的模型仍然展现出更强的概念组合能力。
这表明,平衡的数据分布可以显著提升模型对组合概念的理解和生成能力。
此外,考虑到现实中的开放世界数据集大多遵循长尾分布,因此解决数据不平衡问题是提升模型概念组合能力的关键任务之一。
方法
本文提出了一种在线的概念级均衡训练策略以实现数据平衡,确保效果与效率兼具。本文首先从理想数据分布推导损失权重的形式。然后提出 IMBA 距离,作为一种更准确且高效的数据分布衡量方式。进一步地,本文引入了新颖的在线 token 级 IMBA 损失。最后,本文从开放集数据集中提取惰性概念,用于构建新的 Inert-CompBench 基准。
理论分析
在不失一般性的前提下,本文在 -预测 DDPM 框架下进行推导。值得注意的是,该方法可以轻松扩展到其他扩散模型变体,例如 flow matching。在常见实现中,扩散模型的训练损失由参数 表示,可写为:

其中, 是文本提示, 是由图像 和随机高斯噪声 在时间步 得到的噪声图像。受到已有工作的启发,其中图像区域对提示中的概念短语作出响应,本文将损失函数重写如下:

其中, 是数据集中包含的第 个概念(共 个概念), 是属于概念 的所有图像区域, 是概念 在所有概念中出现的频率比例。自然地,本文有 ,并假设图像区域集合 与图像集合 存在一一对应且满射的映射关系。
本文假设概念的最优平衡分布为 ,即服从离散均匀分布。于是本文可以基于公式 (2) 写出最优的损失函数如下:

其中, 是本文希望获得的损失权重。由于当 服从离散均匀分布时是一个常数,本文只需要估计 。
另一方面,本文希望模型对不同概念的响应强度相近。因此,本文将响应强度表示为条件分布与无条件分布之间的差异,如下所示:

其中,强度仅依赖于 。同时,本文在无分类器引导(classifier-free guidance)中对条件分布与无条件分布的形式化表示如下:

在训练过程中,无条件分布是在多个概念的加权期望上进行训练的:
 然后本文将公式 5、6 和 7 应用于公式 4:
然后本文将公式 5、6 和 7 应用于公式 4:

其中, 是概念 的条件分布与无条件分布之间的差异,本文称之为 IMBA 距离。由于它与 正相关,本文使用它来表示数据集中该概念的频率比例。然后本文将公式 8 应用于公式 3 以获得最优损失:
 其中本文用真实值 替换条件分布 以提高训练稳定性。最终,本文将损失函数重新写回图像 和文本提示 :
其中本文用真实值 替换条件分布 以提高训练稳定性。最终,本文将损失函数重新写回图像 和文本提示 :
 其中本文使用 范数来实现该距离,并在训练过程中停止梯度。本文将这一新颖的损失函数称为 IMBA loss。IMBA loss 在训练过程中动态自适应,无需额外的离线建模,从而确保了有效性与效率。
其中本文使用 范数来实现该距离,并在训练过程中停止梯度。本文将这一新颖的损失函数称为 IMBA loss。IMBA loss 在训练过程中动态自适应,无需额外的离线建模,从而确保了有效性与效率。
IMBA 距离
由于文本提示相比于类别更为复杂,衡量数据平衡性尤其具有挑战性。此外,随着数据集的指数级增长,离线数据裁剪会导致数据浪费以及显著的计算和时间成本。在本节中,本文通过合成实验和文本-图像生成实验展示了 IMBA 距离能够表示概念的频率比例。
合成实验
如下图 5 所示,本文在二维空间中模拟扩散模型的训练和推理结果。所有数据样本都由二维坐标表示,并初始化为两个类别,分别遵循正态分布 (棕色点)和 (紫色点)。本文构建了平衡和不平衡的训练集,它们总共都包含 10K 个样本点,但类别 1(棕色点)与类别 2(紫色点)的比例分别为 1:1 和 99:1。然后本文在两个数据集上用一个两层的 MLP 训练扩散模型。
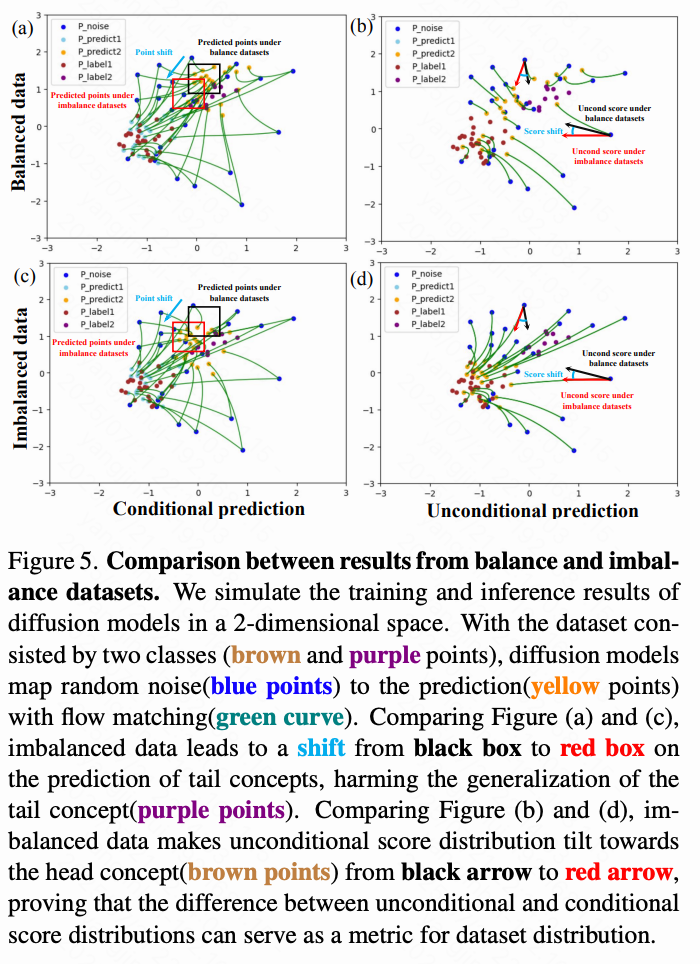
在推理过程中,遵循标准正态分布的随机噪声点(蓝色点)通过基于类别的 flow(绿色曲线)匹配映射到两个目标分布,从而得到预测点(天蓝色和黄色)。在上图 5 中,图 (a,b)/(c,d) 分别展示了在平衡/不平衡数据下的(有条件、无条件)推理结果。
比较图 (a) 和 (c),本文发现尽管推理时有条件地使用类别信息,不平衡数据仍然将尾部概念(紫色点)的预测结果(黄色点)拉向头部概念(棕色点)。具体表现为图 (a) 中黑框内的预测点在不平衡数据下漂移到图 (c) 中红框内。这表明不平衡的数据集损害了尾部概念的泛化能力。
同时,比较图 (b) 和 (d),本文观察到在平衡数据集下,无条件分数分布指向两个类别之间的中间位置(图 (b) 中的黑箭头)。但在不平衡数据集下,它直接指向头部概念(图 (d) 中的红箭头),表现出非常明显的分数偏移(蓝色曲线)。这表明在不平衡数据集下,无条件分数分布倾向于偏向头部概念,从而减少了头部概念的条件分布与无条件分布之间的差异,这与公式 10 中的分析一致。因此,IMBA 距离可以作为一种自平衡、有效且高效的数据分布度量方式,用于训练过程中的监控。
文本-图像生成实验
在本节中,本文进一步展示 IMBA loss 可以作为文本-图像实验中数据分布的度量方式。本文首先从训练集中收集一组概念,在下表 2 中头部和尾部概念各占一半。然后,本文将头部和尾部概念配对,创建新的标题以生成组合图像。本文选择合理的样本以计算 IMBA 距离和扩散损失。

在公式 10 中,由于 IMBA 距离与 相关,因此在不同内容和时间步下不可比较。因此本文选择 ,即整个图像为随机噪声的时刻,来比较不同概念的 IMBA 距离。本文将 IMBA 距离和扩散损失都归一化到区间 ,红色区域表示比蓝色区域更大的值。
如下图 6 所示,本文发现尾部概念普遍具有比头部概念更大的 IMBA 距离,这表明 IMBA 距离可以度量数据分布。此外,尾部概念的扩散损失更大,表明它们相比头部概念存在欠拟合问题。

IMBA Loss
本文在下面算法 1 中展示了 IMBA loss 的计算过程。在训练过程中,在图像 上添加噪声 得到 之后,本文使用扩散模型 来预测条件分数 和无条件分数 。无条件分数和真实噪声用于根据公式 10(停止梯度)计算 IMBA 距离 。然后 IMBA 距离对来自条件分数与真实值的条件损失进行加权,得到最终的 IMBA loss 。

由于模型还需要训练无条件分布,本文使用之前得到的无条件分数计算损失,并应用一个权重系数 来替代原始的随机丢弃条件。在具体实现中,本文设置 来避免颜色偏移, 与原始扩散训练中条件的掩码比例一致。
IMBA 距离通常具有形状 ,本文发现对通道维度进行平均有助于提升训练稳定性。
与基于离线概念频率的损失权重方法相比,IMBA loss 更加准确和高效。
首先,由于文本提示是多个概念的联合分布,而每个概念的频率不同,因此很难像分类任务那样直观且快速地为样本设置损失权重。
其次,尽管可以构建一个概念图,将概念表示为节点,概念对的共现频率作为边的值来推导损失权重,但模型学习的数据分布会随着训练过程不断变化。这种演化导致离线损失权重与模型认知之间的不一致。
相较之下,IMBA 距离天然地与训练过程耦合,提供了更一致的数据分布表示。
第三,由于图像的不同区域可能包含不同的概念,因此数据平衡应在概念区域级别进行。IMBA loss 支持为不同区域设置不同的损失权重,相比为所有区域设置一个统一权重
Inert-CompBench
根据前文中的分析,本文进一步发现数据集中一些低频概念难以与其他概念成功组合,本文将其称为惰性概念(inert concepts)。本文首先计算数据集中所有名词概念的频率,并在取对数后从每个频率区间中均匀采样6个概念。然后将它们两两组合,得到15个组合,并为每个组合生成5个标题,共75个标题。本文在基线模型上评估失败率,如下图7所示。

本文发现,概念组合的成功率随着概念频率的增加而增加,这表明尾部概念相比头部概念更容易出现失败案例。因此,在构建基准测试时应更加关注尾部概念。
由于现有基准测试中对这些概念关注不足,本文从开放世界数据集中提取惰性概念,构建了一个新的基准测试集 Inert-CompBench 作为补充。如下面算法2所示,本文的框架包含五个阶段:
基于大规模数据集统计,提取候选集合,其中头部概念的出现频率至少是尾部概念的100倍; 通过语义典型性分析,从每个池中选择 个领域代表性实体概念; 构建 的笛卡尔积组合空间; 构建概念共现图,筛选结构关联性最小的 Top-K 概念对,以确保测试用例反映非平凡的组合关系; 利用 GPT-4 为每个选中组合生成5个语言多样性提示,最终形成包含1000个细粒度测试样本的基准测试集。
该设计迫使模型处理统计上较弱的概念组合,有效暴露其组合推理能力的局限性。

实验
设置 为了保持数据集一致并提高训练效率,本文对开源数据进行重新标注和筛选,得到一个高质量的训练集,共包含3100万个样本。本文采用一个参数量为10亿的基于 DiT 的扩散模型作为训练管道,未做任何特殊设计。文本提示通过 T5 模型注入扩散模型,图像大小为 ,并通过 Stable Diffusion 的 VAE 编码到隐空间。
基线 本文在新数据集上用原始扩散损失从头训练扩散模型4轮,以建立基线。为了展示本文方法的有效性,本文使用提出的 IMBA loss 在相同数据集上以相同轮数训练同一模型。此外,本文在基线模型上实现了无需训练的方法进行对比。另外,本文还从第3轮开始微调基线模型1轮,引入 IMBA loss,展示本文方法在微调阶段同样具有显著优势。
基准测试 本文在 T2I-CompBench、LC-Mis 和 Inert-CompBench 上评估模型的概念组合能力。在 LC-Mis 和 Inert-CompBench 的评估中,本文采用基于 VLM 的 VQA 方法,如第3节实验设置所述。
定量对比
如下表3所示,本文在 LC-Mis、T2I-CompBench 和本文提出的 Inert-CompBench 上比较了基线、A&E、微调和从头训练的 IMBA loss 方法。

与基线中的扩散损失相比,本文的 IMBA loss 无论是在从头训练还是从预训练模型微调的情况下,都能显著提升概念组合能力。此外,从头训练的效果优于微调。
另外,在物体缺失方面本文的方法取得了类似的提升,而 A&E 在 CLIP 分数上略优,但在属性泄漏(形状、颜色、纹理、VQA)方面表现远差。这是因为 A&E 受限于基础生成模型,无法生成其不理解的概念。
同时,在 Inert-CompBench 上,微调带来的提升有限,说明惰性概念需要更长的训练过程来增强其组合能力。
定性对比
在下图8中,本文分别在三个基准测试集上可视化对比结果,展示了本文方法的优势。本文不仅在现有基准测试集上有效解决了物体缺失和属性泄漏问题,还在 Inert-CompBench 上表现出显著优势,大幅提升了惰性概念的成功率。

消融实验 本文进一步在样本级损失权重、超参数和 IMBA 距离上进行了全面实验。
结论
本文提出了一种基于概念均衡的损失函数IMBA loss,用于提升生成模型的概念组合能力。首先通过精心设计的实验分析了因果因素,弥合了合成实验与大规模文本-图像生成之间的差距。证明了当模型达到一定规模时,数据分布成为关键因素。
随后,提出 IMBA 距离来估计数据分布,并通过合成实验和文本-图像实验验证其有效性。接着,本文引入了在线的概念级均衡方法 IMBA loss 来平衡概念。
进一步地,从大规模文本-图像数据集中识别出惰性概念,并构建了新的基准测试集 Inert-CompBench,作为对现有基准的补充。最后,本文通过全面实验验证了本文方法的优越性。
参考文献
[1] Imbalance in Balance: Online Concept Balancing in Generation Models
致谢
如果您觉得这篇文章对你有帮助或启发,请不吝点赞、在看、转发,让更多人受益。同时,欢迎给个星标⭐,以便第一时间收到我的最新推送。每一个互动都是对我最大的鼓励。让我们携手并进,共同探索未知,见证一个充满希望和伟大的未来!
技术交流
加入「AI生成未来社区」群聊,一起交流讨论,涉及 图像生成、视频生成、3D生成、具身智能等多个不同方向,备注不同方向邀请入群!可添加小助手备注方向加群!


 扫码添加微信
扫码添加微信
- 点赞 0
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊