微妙情绪精准拿捏!DiT新框架FantasyPortrait首破多角色动画难题,开源数据集引爆行业!
- 2025-07-23 00:01:00
如您有工作需要分享,欢迎联系:aigc_to_future
作者:Qiang Wang等

文章链接:https://arxiv.org/abs/2507.12956
Git链接:https://fantasy-amap.github.io/fantasy-portrait/

亮点直击
提出了一种基于表情增强的隐式面部表情控制方法,通过分解的隐式表示和表情感知学习模块,增强对细微表情动态和复杂情感的捕捉能力。 设计了一种掩码注意力机制,能够在保持严格身份分离的同时实现多角色同步动画,有效防止跨角色特征干扰。 构建了ExprBench——一个专门针对表情驱动动画的评估基准,以及多角色表情数据集Multi-Expr。大量实验表明,本文的方法在细粒度可控性和表现力质量上均优于现有方法。
总结速览
解决的问题
跨身份重演(Cross Reenactment)的挑战:传统基于几何先验(如面部关键点、3DMM)的方法在源图像与驱动视频面部几何差异较大时(如不同种族、年龄、性别),容易产生面部伪影、运动扭曲和背景闪烁。 难以捕捉细微情感: 显式几何表示无法充分捕捉复杂的情感变化和细微表情差异,依赖源与目标面部的精确对齐。 多角色动画的干扰问题: 现有方法缺乏对多角色动画的支持,不同角色的驱动特征会相互干扰,导致表情泄露(expression leakage),难以保持角色间的独立性与协调性。 缺乏数据集与评估标准: 缺少专门针对多角色肖像动画的公开数据集和标准化评估基准。
提出的方案
FantasyPortrait 框架: 基于扩散Transformer(DiT),支持生成高保真、情感丰富的单角色和多角色动画。 关键技术改进: Expression-Augmented Learning(表情增强学习):利用隐式表示捕捉身份无关的面部动态,增强模型对细微情感的渲染能力。 Masked Cross-Attention(掩码交叉注意力): 确保多角色表情生成的独立性与协调性,避免特征干扰。 新数据集与基准: Multi-Expr 数据集:专为多角色肖像动画训练设计。 ExprBench 基准:提供标准化评估,涵盖单角色和多角色的表情、情感及头部运动。
应用的技术
生成模型: 采用 Diffusion Transformer(DiT) 作为核心生成框架。 隐式表情表示: 从驱动视频中提取身份无关的面部动态特征,替代传统显式几何先验。 注意力机制优化: 引入 Masked Cross-Attention,防止多角色特征混淆。
达到的效果
高保真动画生成: 在 ExprBench 上定量与定性评估均优于现有方法(如 GANs、NeRF、传统 Diffusion Models)。 优异的跨身份重演能力: 显著减少面部伪影和运动失真,适应不同种族、年龄、性别的面部差异。 多角色独立控制: 成功实现多角色表情的独立生成与协调,避免特征干扰。 情感表达增强: 能捕捉更丰富的情感细节,生成更具表现力的动画。
方法
FantasyPortrait的整体架构如下图2所示。给定参考肖像图像和包含面部运动的驱动视频片段,从视频序列中提取隐式面部表情特征,并将其迁移并融合到目标肖像中以生成最终视频输出。本文提出了一种新颖的表情增强隐式控制方法,旨在从隐式面部表示中学习细粒度表情特征,同时显著增强对具有挑战性的面部动态(尤其是嘴部运动和情感表达)的建模能力。此外,我们提出了一种多肖像掩码交叉注意力机制,以实现跨多个角色的精确协调的面部表情控制。
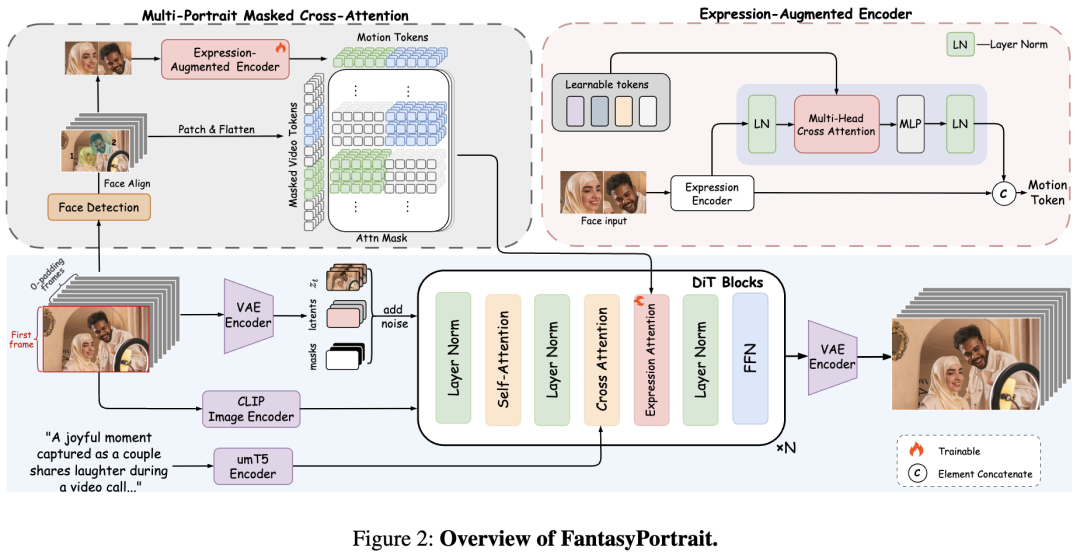
表情增强隐式控制
隐式表情表示。本文通过隐式特征提取流程从驱动视频中提取与身份无关的表情表示。与依赖显式面部关键点的传统肖像动画方法不同,本文的方法利用隐式编码更好地将表情相关特征与相机运动和主体特定属性等混杂因素解耦,从而实现更自然和适应性更强的动画效果。本文在每帧中检测并对齐面部区域。随后使用预训练的隐式表情提取器将驱动视频编码为表达性隐空间特征。这些特征包括唇部运动、视线和眨眼、头部姿态以及情感表达。
表情增强学习。面部表情生成涉及一个复杂的多层次系统,包含相对简单的刚性运动特征(例如头部旋转和眼部运动)和高度动态的非刚性形变(例如与情感相关的肌肉活动和唇部运动)。简单运动由于其更规律的模式和明确的物理约束,相对容易建模。相比之下,复杂运动涉及更丰富的语义信息和细微的肌肉协同作用,表现出更强的非线性特征。这种特征复杂性的显著差异为同时学习两种运动类型带来了相当大的挑战。
为了解决这一问题,本文提出了一种表情增强编码器,以增强对细微和具有挑战性特征的学习。对于和,本文使用可学习的标记进行细粒度分解和增强,其中每个子特征对应更精细的肌肉群或情感维度。每个细粒度子特征随后通过多头交叉注意力与语义对齐的视频标记交互,有效捕获特定区域的语义关系。随后将表情增强特征与和拼接,得到运动嵌入,如下所示:

多角色动画
多角色嵌入。利用隐式表情增强表示,本文为每个角色提取细粒度的肖像运动嵌入。对于多角色动画,使用人脸识别模型检测并裁剪面部区域,然后为每个角色提取特定身份的运动嵌入,其中表示帧数,表示通道数,表示空间嵌入长度。最终的多角色运动特征通过将所有个独立嵌入沿长度轴拼接得到

掩码交叉注意力。为了防止不同个体的表情驱动信号之间出现身份混淆和交叉干扰,我们设计了一种掩码交叉注意力机制,用于在所有交叉注意力层中对多肖像嵌入进行加权。本文从视频中提取面部掩码,然后应用三线性插值将其映射到隐空间,得到隐空间掩码。多肖像运动嵌入通过专用的交叉注意力层与预训练DiT的每个块交互。每个DiT块的隐藏状态被重新表示为

实验
Multi-Expr数据集
为解决当前多角色面部表情视频数据集的稀缺问题,本文提出了专门为此设计的Multi-Expr数据集。该数据集从OpenVid-1M和OpenHumanVid中筛选,并通过多角色过滤、质量控制和表情选择等数据处理流程确保视频质量。首先使用YOLOv8检测视频片段中的人物数量,仅保留包含两个及以上角色的片段。接着,通过美学评分和拉普拉斯算子过滤低质量、模糊或伪影严重的片段。最后,基于MediaPipe检测的面部关键点,计算角度和运动变化以筛选具有清晰表情的片段。数据集包含约30,000个高质量视频片段,每个片段均附带CogVLM2生成的描述性标注。
ExprBench
由于缺乏公开的多角色表情驱动视频生成评估基准,本文提出ExprBench以客观比较不同方法在生成丰富表情的面部动画上的性能。ExprBench包含单角色评估基准ExprBench-Single和多角色基准ExprBench-Multi。具体地,我们从Pexels¹的无版权资源中精心收集了200张单角色肖像和100段驱动视频构建ExprBench-Single,每段驱动视频裁剪为5秒(约125帧)。肖像图像涵盖真实人类风格、拟人化风格(如动物、卡通角色)及多样场景(如录音棚、表演舞台、直播间)。驱动视频包含多样表情(如眼皮下垂、眉毛抽动)、情感(如快乐、悲伤、愤怒)和头部运动。
为评估多角色表情驱动生成性能,本文还收集了100张肖像图像和50段驱动视频构建多中心基准ExprBench-Multi,用于测试多角色表情与运动的生成任务。下图3展示了ExprBench的肖像图像和驱动视频示例。

实现细节
本文采用Wan2.1-I2V-14B作为预训练模型,在单角色数据集Hallo3和Multi-Expr数据集上训练。整个训练过程使用24块A100 GPU运行约3天,学习率设为。为增强生成多样性,本文对参考图像、表情特征和提示词独立应用概率为0.2的dropout。推理阶段采用30步采样,表情的无分类器引导尺度设为4.5,文本提示保持为空。
基线对比
基线方法与指标。在单角色设定下,本文选取以下公开的肖像动画方法进行比较评估:LivePortrait、Skyreels-A1、HunyuanPortrait、X-Portrait和FollowYE。多角色基线采用LivePortrait的多脸版本。
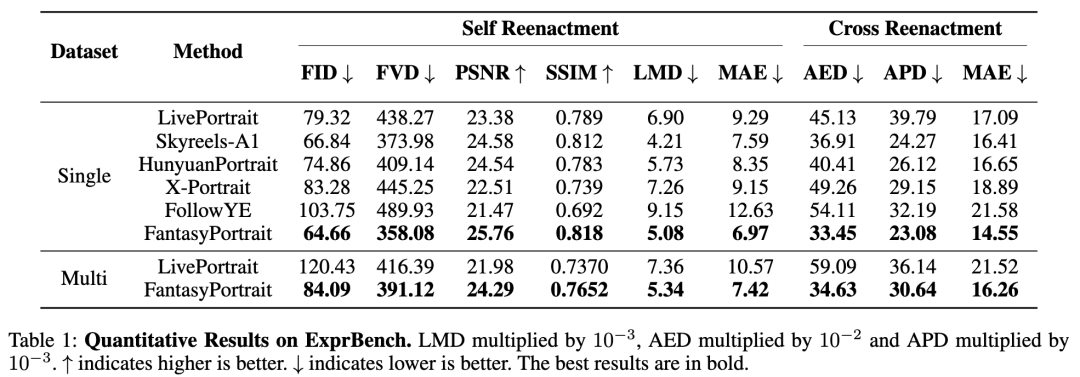
本文在ExprBench上评估所有方法。对于自驱动重演评估,使用第一帧作为源输入图像,驱动视频作为真实标签。为评估生成肖像动画的泛化质量和运动准确性,本文采用Fréchet Inception Distance (FID)、Fréchet Video Distance (FVD)、峰值信噪比(PSNR) 和 结构相似性指数(SSIM) 。此外,为测量表情运动准确性,使用Landmark Mean Distance (LMD),而Mean Angular Error (MAE) 用于评估眼部运动精度。对于跨身份重演评估,采用Average Expression Distance (AED)、Average Pose Distance (APD) 和MAE,其中AED和APD分别评估表情和头部姿态运动的准确性。
定量结果。下表1展示了定量对比结果。基于形变的LivePortrait方法在全局头部运动控制上精度有限,其APD得分在对比方法中最低。FollowYE和Skyreels-A1等方法依赖显式面部关键点控制头部或面部运动,但该方法在跨身份重演中不可避免地引入身份泄漏,导致AED、APD和MAE指标下降。HunyuanPortrait使用隐式信号生成表情,同时采用显式DWPose条件驱动头部运动,性能仍受限。基于GAN的LivePortrait与基于UNet的HunyuanPortrait、X-Portrait和FollowYE在FID和FVD上表现较差,表明其在视频质量(尤其是面部细节保留)上逊于基于DiT的Skyreels-A1和FantasyPortrait。本文的方法在LMD、MAE、AED和APD等表情与头部运动相似性指标上达到SOTA,跨身份重演提升尤为显著。这些结果验证了细粒度隐式表情表示与表情增强学习能有效捕捉细微表情和情感动态,同时保持优异的跨身份迁移能力。多角色实验中,本文的方法同样取得最佳定量结果,证实掩码交叉注意力机制能实现对多肖像的鲁棒精确控制。
定性结果。下图4显示,本文的方法实现了更准确的面部运动迁移和更逼真的视觉效果。单角色场景下,尽管驱动视频存在相机运动和身体姿态干扰,本文的方法在视觉质量上仍优于所有基线(基线方法在此类干扰下出现伪影和错误表情)。这一优势源于表情增强的隐式面部控制方法,实现了更鲁棒和细腻的表情操控。多角色场景中,LivePortrait因依赖像素空间的面部分割与重组,驱动区域与静态背景间存在明显不连续;而本文的方法通过掩码交叉注意力在潜在空间无缝整合不同身份的表情特征,避免了相互干扰或表情泄漏,生成结果更自然。

用户研究。由于跨身份重演缺乏真实标签,邀请32名参与者从视频质量(VQ)、表情相似性(ES)、运动自然度(MN)和表情丰富度(ER)四个维度(0-10分)进行主观评估。如下表2所示,FantasyPortrait在所有维度上均优于基线,尤其在表情相似性和丰富度上提升显著,表明隐式条件控制机制与表情增强学习框架能更好地跨身份捕捉与迁移细粒度表情,凸显了方法的强泛化能力。

更多可视化结果。补充材料包含扩展视频,展示多样化肖像风格(如动物、动漫角色)、复杂现实场景(如眼镜遮挡、头部饰品、面部遮挡)、身份交换动画及多肖像组合生成的多角色动画。
消融实验与讨论
表情增强学习(EAL)消融实验。为验证EAL模块的有效性,本文对比了三种配置:(1) 直接拼接所有隐式特征(Ours(w/o EAL));(2) 对所有隐式特征应用表情增强学习(Ours(all EAL));(3) 仅对唇部运动和情感特征选择性增强(本文的方法)。如图5和表3所示,未使用EAL时AED显著下降,表明细粒度表情学习能力受损。有趣的是,APD和MAE在所有配置中保持稳定,说明头部姿态和眼部运动遵循更刚性且易学习的模式,增强学习对其收益有限。然而,对于唇部运动和情感动态等复杂非刚性运动,未使用EAL时性能下降明显。这验证了我们选择性增强和的设计合理性,因为全增强对刚性运动收益微乎其微,却会增加计算复杂度。
掩码交叉注意力(MCA)消融实验。下表3与图5结果表明MCA在多角色应用中的关键作用。未使用MCA时,多角色的驱动特征相互干扰,导致所有评估指标显著下降。如图5所示,缺乏MCA会导致角色间表情冲突,生成结果几乎无法跟随驱动视频。相比之下,掩码交叉注意力机制使模型能独立控制不同角色。


Multi-Expr数据集(MED)消融实验。实验结果证明多表情数据集在肖像动画任务中的必要性。如表3和图5所示,仅使用单角色数据集训练时,单角色动画性能相当,但多角色场景会出现性能下降甚至视觉伪影。这表明多表情数据集对单角色动画非必需,但对高质量多角色动画不可或缺,可帮助模型学习跨角色的细粒度表情表示。
局限性与未来工作。尽管本文的方法在跨身份重演动画中取得显著进展,仍存在两个关键局限:(1) 扩散模型的迭代采样导致生成速度较慢,可能阻碍实时应用,未来将探索加速策略;(2) 高保真动画可能引发滥用风险,建议开发鲁棒的检测与防御机制以降低伦理风险。
结论
本文提出FantasyPortrait——一种基于DiT的框架,用于生成富有表现力且对齐准确的多角色肖像动画。本文的方法利用隐式表情表示实现身份无关的运动迁移,同时保留细粒度情感细节;引入掩码交叉注意力机制实现多角色的同步独立控制,有效解决表情泄漏问题。为支持该领域研究,贡献了评估基准ExprBench和多角色表情数据集Multi-Expr。大量实验表明,FantasyPortrait在单/多角色动画场景(尤其是跨身份重演和复杂情感表达)中均优于现有方法。
参考文献
[1] FantasyPortrait: Enhancing Multi-Character Portrait Animation with Expression-Augmented Diffusion Transformers
致谢
如果您觉得这篇文章对你有帮助或启发,请不吝点赞、在看、转发,让更多人受益。同时,欢迎给个星标⭐,以便第一时间收到我的最新推送。每一个互动都是对我最大的鼓励。让我们携手并进,共同探索未知,见证一个充满希望和伟大的未来!
技术交流
加入「AI生成未来社区」群聊,一起交流讨论,涉及 图像生成、视频生成、3D生成、具身智能等多个不同方向,备注不同方向邀请入群!可添加小助手备注方向加群!

 扫码添加微信
扫码添加微信