


万字长文解析Kimi K2 技术报告!
- 2025-07-23 00:01:00
如您有工作需要分享,欢迎联系:aigc_to_future
转载自:机智流
如有侵权,联系删稿
刚刚,Kimi K2 技术报告重磅发布,万字长文解析来啦~
内容由 书生 Intern、Qwen、Kimi K2 等AI 生成,可能有误
Kimi K2 是一个拥有 1.04万亿总参数 的混合专家(MoE)开源大语言模型,其规模和性能在开源世界中堪称一骑绝尘。更重要的是,Kimi团队此次不仅开放了模型权重,还详细披露了其背后的技术报告,为整个AI社区的研究和应用点亮了一盏明灯。
从颠覆性的优化器 MuonClip 实现了15.5万亿Tokens的“零”损失尖峰稳定训练,到为“智能体”量身打造的大规模合成数据流水线,再到融合了可验证奖励与自我批判的强化学习框架,Kimi K2 的每一步都走得扎实而富有远见。
那么,这个万亿参数的开源巨兽究竟有多强?它将如何搅动AI江湖?它所指向的“智能体智能”又意味着怎样的未来?今天,就让我们一同深入这份技术报告,为您全方位解读Kimi K2的诞生之路与超凡实力。🚀
地址:https://github.com/MoonshotAI/Kimi-K2/blob/main/tech_report.pdf
🚀 Kimi K2:开启开源智能体新纪元
人工智能的发展正经历一场深刻的范式革命,从静态的模仿学习,转向能够自主感知、规划、推理并与复杂动态环境交互的**智能体智能 (Agentic Intelligence)**。这标志着AI不再仅仅是海量人类数据的复读机,而是开始通过与真实世界的互动来主动学习、获取新技能,并最终可能超越人类,实现通用人工智能的宏伟蓝天。
然而,通往智能体智能的道路充满挑战。预训练阶段,高质量数据日益稀缺,如何提升每一枚Token的学习效率成为关键;后训练阶段,如何教会模型进行多步推理、长期规划和工具使用这些在自然数据中极为罕见的复杂能力,更是难上加难。
在此背景下,Kimi K2 应运而生。它是一个拥有 1.04万亿 总参数、320亿 激活参数的混合专家(MoE)大语言模型,其设计的核心目标就是攻克智能体能力的核心挑战,推动AI能力的边界。
🔥 核心贡献与亮点速览
Kimi K2的突破性贡献贯穿了预训练与后训练的全过程:
创新的MuonClip优化器:Kimi团队提出了一个名为 MuonClip 的全新优化器。它巧妙地结合了高Token效率的Muon算法与一种名为 QK-Clip 的稳定性增强技术,成功解决了Muon算法在超大规模训练中容易出现的不稳定问题。基于此,Kimi K2在15.5万亿Tokens的庞大预训练过程中,实现了零损失尖峰的完美训练曲线,堪称工程奇迹。
大规模智能体数据合成流水线:为了教会模型如何使用工具,Kimi团队构建了一套强大的数据合成系统。该系统能够模拟真实世界环境,系统性地生成海量、多样化且高质量的工具使用轨迹数据。这套系统是Kimi K2强大智能体能力的基石。
通用的强化学习框架:Kimi K2的后训练采用了一种独特的联合强化学习(RL)框架。它不仅能从有明确答案的任务(如代码编译、数学计算)中学习,还能通过一种自我批判机制来评估和改进自己在开放式、主观性任务(如创意写作)上的表现,实现了模型能力的全面对齐与提升。
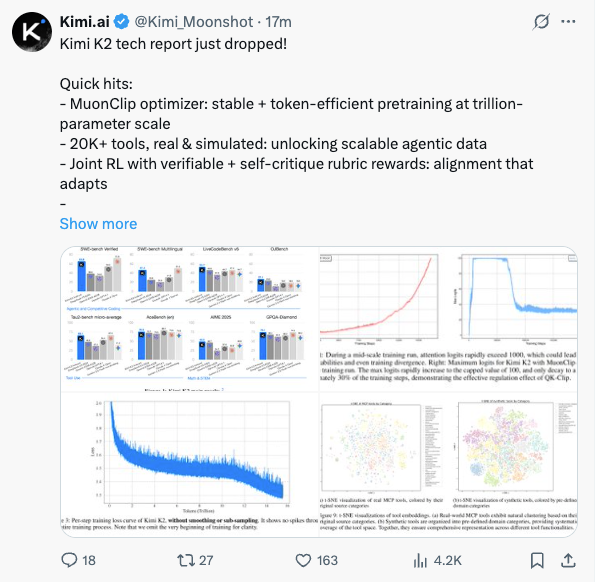
📊 一图看懂Kimi K2的超强实力
语言是苍白的,数据是雄辩的。在发布的技术报告中,一张性能对比图足以说明Kimi K2在众多基准测试中的王者地位。

图1: Kimi K2 主要成果展示。 在多个关键的智能体、代码和推理能力基准测试中,Kimi K2的性能不仅全面超越了现有的开源模型,甚至在许多非思维链(non-thinking)的评测设置下,其表现已经逼近甚至超越了如Claude 4 Sonnet等顶尖的闭源模型。
具体来看,Kimi K2在多个领域刷新了开源模型的记录:
智能体与工具使用:在评估多轮复杂工具调用的 Tau2-Bench和ACEBench上,分别取得了 66.1 和 76.5 的高分,大幅领先所有对手。软件工程与代码能力:在被誉为“代码界珠峰”的 SWE-Bench Verified上,Kimi K2取得了惊人的 65.8分,在多语言版的SWE-Bench Multilingual上也达到了 47.3分,显著缩小了与最强闭源模型 Claude 4 Opus 的差距。数学与推理:在 AIME 2025(49.5分) 和GPQA-Diamond(75.1分) 等高难度推理任务上,Kimi K2同样展现了顶级的实力。用户口碑:在LMSYS Arena这个由全球用户盲评的“模型武道场”上(截至2025年7月17日数据),Kimi K2凭借超过3000次的用户投票,高居开源模型榜首,总排名第五。
为了推动整个社区在智能体领域的共同进步,Kimi团队毅然决定开源Kimi K2的基座模型和指令微调后模型的所有权重,这无疑是为全球的AI开发者和研究者送上的一份厚礼。
🎯 第一章:基石——稳定高效的万亿参数模型预训练
要建成一座摩天大楼,必须有坚实的地基。对于大模型而言,预训练就是这个地基。Kimi K2的预训练过程充满了创新与智慧,完美解决了“数据效率”和“训练稳定”这两大世界性难题。
1.1 MuonClip:为万亿模型训练保驾护航
随着模型参数和数据量的爆炸式增长,如何让模型“吃”进去的每一个Token都物尽其用,变得至关重要。Kimi团队选择了在之前工作中已被证明效率极高的 Muon优化器。在同等算力下,Muon的性能远超传统的AdamW优化器。
然而,当模型规模扩大到Kimi K2这个级别时,Muon的“脾气”也变大了——它更容易引发注意力 logits 爆炸,导致训练过程出现损失尖峰,甚至彻底崩溃。
为了驯服这匹“烈马”,Kimi团队创造性地提出了 QK-Clip 技术。
什么是QK-Clip?
简单来说,它就像一个智能的“保险丝”。在训练的每一步,它都会监测注意力机制中Query和Key向量点积后的数值(即logits)。一旦这个数值超过了预设的安全阈值(比如100),QK-Clip就会自动、精准地对产生这个问题的注意力头的权重(Wq, Wk)进行缩放,把logits拉回到安全区内。
它的高明之处在于:
精准打击:它只对“出问题”的少数注意力头进行干预,而不是“一刀切”,最大限度减少了对模型训练的干扰。 自动启停:在训练初期,当logits容易爆炸时,它频繁启动;当训练稳定后,它就自动“隐身”,不再发挥作用。
Kimi团队将Muon优化器与QK-Clip等技术结合,形成了全新的 MuonClip 优化器。

图2: MuonClip的效果验证。 左图显示,在没有QK-Clip的情况下,注意力logits会迅速飙升到1000以上,极易导致训练崩溃。右图展示了Kimi K2在使用MuonClip(阈值τ=100)时的训练过程,最大logits被牢牢地限制在100,并在训练后期自然回落到稳定范围,证明了QK-Clip的有效调控能力。
最终,在MuonClip的保驾护航下,Kimi K2的整个预训练过程如丝般顺滑,下图是其未经任何平滑处理的原始训练损失曲线,没有任何一次损失尖峰。

图3: Kimi K2 的每步训练损失曲线。 这条平滑的曲线展示了整个训练过程惊人的稳定性,没有任何损失尖峰,这在万亿参数模型的训练中极为罕见。
1.2 数据扩增术:用“复述”榨干高质量数据价值
高质量的人类数据是有限的,如何将这些珍贵数据的价值最大化?简单地重复训练(multi-epoch)会导致模型过拟合,失去泛化能力。Kimi K2团队采用了一种更高明的方法——数据复述(Rephrasing)。
其核心思想是,利用一个强大的教师模型,将一份高质量的原始文本,从不同的风格、视角进行忠实地重写,生成多份内容一致但表达方式不同的新数据。这相当于让模型用不同的“姿势”反复学习同一个知识点,既加强了记忆,又避免了死记硬背。
知识数据复述:对于维基百科等知识密集型长文本,Kimi团队设计了一套分块自回归复述流程。它将长文切片,逐片复述,并确保上下文连贯,最后拼接成一篇全新的文章。

图4: 自回归分块复述流程示意图。 该流程能有效处理长文本,在保持全局连贯性的同时,生成语言风格多样化的复述版本。
实验证明,用10个不同复述版本的数据训练1遍,效果远好于用原始数据重复训练10遍。
数学数据复述:为了提升数学推理能力,团队将高质量的数学文档改写成类似“学习笔记”的风格,并翻译了其他语言的优质数学资料,极大地丰富了数学训练数据的多样性。
通过这种方式,Kimi K2的 15.5万亿 Tokens预训练数据,覆盖了网页文本、代码、数学和知识四大领域,每一枚Token的效用都得到了充分发挥。
1.3 模型架构:追求极致稀疏的艺术
Kimi K2的体量惊人,拥有1.04万亿总参数,但其在推理时每次只激活326亿参数,这得益于其混合专家(MoE)架构。
Kimi团队通过大量的实验发现了一条稀疏度缩放定律(Sparsity Scaling Law):在保持激活参数量(即计算量FLOPs)不变的情况下,总专家数越多(即模型越稀疏),模型的性能就越好。

图5: 稀疏度缩放定律。 实验表明,在激活专家数固定为8时,将总专家数从64(稀疏度8)提升到384(稀疏度48),模型的验证损失持续降低,性能显著提升。
基于这一发现,Kimi K2采用了384个专家的超高稀疏度设计,每次前向传播激活其中8个。这在性能和工程成本之间取得了绝佳的平衡。
| #Layers | |||
| TotalParameters | |||
| ActivatedParameters | |||
| Experts (total) | |||
| ExpertsActiveper Token | |||
| SharedExperts | |||
| AttentionHeads | |||
| Number of Dense Layers | |||
| Expert Grouping | |||
| 表2: Kimi K2 与 DeepSeek-V3 架构对比。 |
此外,为了在长文本场景下获得更高的推理效率,Kimi K2将注意力头的数量从DeepSeek-V3的128个减少到了64个。实验证明,这一改动对性能影响甚微,但却能显著降低长文本推理时的计算开销,这对于需要处理大量上下文的智能体应用至关重要。
1.4 训练设施:软硬件协同的极致优化
在强大的NVIDIA H800 GPU集群上,Kimi团队构建了一套高度灵活且高效的训练系统。
灵活的并行策略:通过流水线并行(PP)、专家并行(EP)和ZeRO数据并行(DP)的精妙组合,Kimi K2可以在任意32的倍数节点数量上进行训练,极大地提升了研发效率。 极致的显存优化:为了在有限的GPU显存中容纳下万亿模型的庞大激活值,团队采用了包括选择性重计算、FP8激活值存储和CPU内存卸载在内的多种先进技术。

图7: 训练中计算、通信和卸载的重叠。 Kimi K2的训练系统通过精密的流水线调度,将计算、通信和与CPU之间的数据传输(卸载/加载)完美重叠,最大限度地利用了硬件资源,提升了训练效率。
正是这些在模型、算法、数据和系统层面的全方位创新,共同铸就了Kimi K2强大而稳定的基座模型。
💡 第二章:飞跃——通往智能体的后训练之路
一个强大的基座模型好比一个天赋异禀但未经世事的少年,而后训练(Post-Training)的过程,就是将他的天赋激发出来,教会他如何在真实世界中解决复杂问题的过程。Kimi K2的后训练过程,完全是为“智能体”能力而设计的。
2.1 大规模智能体数据合成:让模型在模拟世界中学会使用工具
现代LLM智能体的一项核心能力是使用各种不熟悉的工具与外部世界交互。但如何获得海量的、高质量的工具使用训练数据呢?让模型在真实世界中随意尝试,成本高昂且充满风险。
Kimi团队的答案是:构建一个可以大规模生成高质量训练数据的模拟世界。

图8: 工具使用数据合成流水线。 整个流程分为三步:(a) 首先构建一个包含数万个真实和合成工具的庞大工具库,并从中生成各种智能体和任务;(b) 然后通过多智能体协作的方式,生成智能体调用工具完成任务的完整轨迹,并进行严格的质量过滤。
这个数据合成流水线有几个关键特点:
海量多样的工具库:Kimi团队收集了超过3000个来自GitHub的真实工具(MCP),并利用“领域进化”技术合成了超过20000个覆盖金融、软件、机器人等领域的虚拟工具。
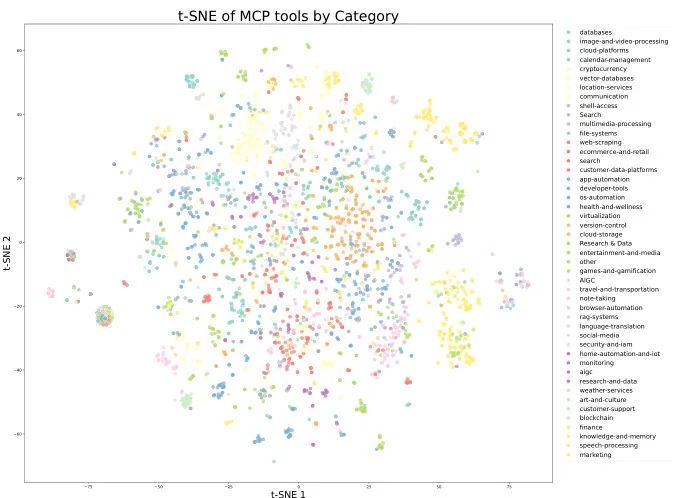
(a) 真实MCP工具的t-SNE可视化
(b) 合成工具的t-SNE可视化图9: 工具库多样性可视化。 从t-SNE降维图可以看出,真实工具和合成工具覆盖了互补的区域,共同构成了一个全面而多样的工具空间,确保模型能够学习到广泛的工具使用能力。
多样化的智能体和任务:通过为智能体设定不同的“人设”(系统提示)和分配不同的工具组合,生成了数千个能力各异的智能体。同时,为每个智能体生成了从简单到复杂的任务,并配有明确的成功标准(Rubric)。
高度仿真的轨迹生成:流水线中包含了用户模拟器(模拟真实用户的多轮对话)、工具执行环境(模拟工具调用的真实反馈,包括成功、失败和各种意外情况),以及一个LLM裁判(根据任务标准评估轨迹质量)。
真实与模拟的混合:对于代码和软件工程这类对真实性要求极高的任务,团队将模拟环境与真实的执行沙箱相结合。代码在真实的开发环境中运行,用单元测试通过率等客观指标来提供反馈。
通过这个强大的混合数据生成流水线,Kimi K2在SFT阶段就学习到了扎实的、可泛化的工具使用能力。
2.2 联合强化学习:在自我博弈中实现能力升华
如果说SFT是“老师教”,那么强化学习(RL)就是“自己练”。Kimi K2的RL框架将两类任务融合在一起,进行统一训练。
A. 可验证奖励任务(RLVR)
对于有明确对错之分的任务,Kimi K2可以在一个“可验证奖励健身房(Verifiable Rewards Gym)”里进行训练。这个“健身房”里有各种各样的“器材”:
数学、STEM和逻辑题:海量的数理竞赛题、逻辑谜题(数独、密码破译等),模型给出答案后,系统能自动判断对错并给予奖励。 复杂指令遵循:各种带有复杂约束条件的任务(比如“写一首五言绝句,其中必须包含‘月’和‘霜’,且不能出现‘悲伤’”),系统能自动检查模型是否满足所有约束。 代码与软件工程:在包含真实GitHub问题的软件开发环境中,模型生成的代码可以直接在沙箱中运行单元测试,通过率就是最直接的奖励信号。 安全性:通过一个自动化的攻击流水线,不断生成各种“越狱”提示词来攻击模型,模型如果能守住安全底线,就会得到奖励。
B. 自我批判奖励任务
对于没有标准答案的主观任务(如创意写作、开放式问答),如何进行RL?Kimi K2的答案是:让模型自己当裁判。
这个过程被称为**自批判奖励机制 (Self-Critique Rubric Reward)**。
K2演员生成答案:对于一个开放式问题,K2模型(作为“演员”)会生成多个不同的回答。 K2评委进行打分:K2模型(此时切换为“评委”角色)会根据一套内置的、复杂的评分标准(Rubric),对这些回答进行两两比较,选出更好的一个。这套标准不仅包含了“清晰度”、“相关性”等通用原则,还包含了一些由人类专家为特定场景设计的细则。 反馈给演员进行优化:被评委选出的“更优答案”会作为正向信号,用来优化“演员”模型。
更巧妙的是,这个“评委”模型的能力也不是一成不变的。它会将在可验证奖励任务中学习到的客观判断能力,迁移到主观任务的评判中,从而让其评判标准越来越可靠。
通过将这两类任务结合,并辅以预算控制(防止模型啰嗦)、PTX损失(防止遗忘高质量SFT数据)、温度衰减(从探索到利用的平滑过渡)等多种RL技巧,Kimi K2在保持开放域能力的同时,也极大地增强了在复杂、专业领域的解决问题的能力。
🚀 第三章:实力对决——Kimi K2 全方位性能评测
理论说尽,实战见真章。Kimi K2在发布的技术报告中,与当前最强的开源和闭源模型进行了一场全方位的“华山论剑”。所有评测都在非思维链(non-thinking)模式下进行,确保了公平性。
3.1 指令微调模型(Instruct Model)综合能力评估
这是与用户直接交互的模型版本,其性能表现最为关键。
表3: Kimi-K2-Instruct 与顶级模型的性能对比(加粗表示全场最佳,下划线加粗表示开源模型最佳)
| Kimi-K2- Instruct | |||||||
| Coding Tasks | |||||||
| 53.7 | |||||||
| 27.1 | |||||||
| 85.7 | 89.6 | ||||||
| 65.8 | 72.7* | ||||||
| 47.3 | 51.0 | ||||||
| Tool Use Tasks | |||||||
| 66.1 | 66.3 | ||||||
| 76.5 | 80.1 | ||||||
| Math & STEM Tasks | |||||||
| 69.6 | |||||||
| 49.5 | |||||||
| 75.1 | |||||||
| General Tasks | |||||||
| 89.5 | 92.9 | ||||||
| 92.7 | 94.2 | ||||||
| 89.8 | |||||||
从这张简化版的表格中,我们可以清晰地看到:
代码与智能体能力一骑绝尘:在所有代码和工具使用相关的测试中,Kimi K2不仅碾压了所有其他开源模型,而且在 SWE-bench等真实世界软件工程任务上,已经与最强的闭源模型Claude 4系列打得有来有回,展现了其作为“智能体”的巨大潜力。数学与推理能力登顶开源:在 AIME和GPQA-Diamond等极具挑战性的数学和科学推理任务上,Kimi K2同样取得了开源模型的最佳成绩,甚至超过了部分闭源模型。通用能力全面领先:在 MMLU、MMLU-Redux等衡量综合知识能力的测试中,Kimi K2稳居开源模型第一梯队。在评估指令遵循能力的IFEval上,更是取得了全场最高分。
3.2 基座模型(Base Model)潜力评估
基座模型的性能直接反映了预训练的质量。Kimi K2的基座模型同样展现出了惊人的“素颜”实力。
表4: Kimi-K2-Base 与主流开源基座模型性能对比
| Benchmark(Metric) | Kimi-K2-Base (32B/1043B) | |||
| English General | ||||
| 87.79 | ||||
| 69.17 | ||||
| 50.51 | ||||
| 35.25 | ||||
| Code | ||||
| 74.00 | ||||
| 26.29 | ||||
| 80.33 | ||||
| Math | ||||
| 70.22 | ||||
| 92.12 | ||||
| Chinese | ||||
| 92.50 | ||||
| 90.90 | ||||
结果非常清晰:Kimi-K2-Base在英文通用、代码、数学、中文四大领域的绝大多数基准测试中,都取得了SOTA(State-of-the-Art)的成绩,证明了其预训练的巨大成功,为下游的微调和智能体能力构建打下了无与伦比的坚实基础。
3.3 安全性评估
Kimi团队同样对模型进行了严格的红队测试,评估其在有害内容、隐私、安全等方面的鲁棒性。结果显示,Kimi K2在多数场景下表现出了良好的安全性,尤其是在基础攻击下通过率很高。当然,在面对一些复杂的、迭代式的“越狱”攻击时,仍有提升空间,这也是所有大模型共同面临的挑战。
坦诚与展望
技术报告也坦诚地指出了Kimi K2当前存在的一些局限性:
在处理非常困难的推理任务或工具定义不明确时,模型可能会生成过长的内容。 在不必要的情况下强行使用工具,有时反而会降低任务性能。 在构建完整软件项目时,单次提示(one-shot)的成功率不如在智能体框架下进行。
Kimi团队表示正在积极解决这些问题,并期待社区的反馈能帮助模型持续进步。
结语:洞见与未来——开源照亮智能体之路
Kimi K2的发布,无疑是2025年AI领域,尤其是开源社区的一座重要里程碑。它不仅仅是一个参数量惊人的模型,更是一套经过实战检验、通往“智能体智能”的完整技术路线图的开源展示。
从创新的MuonClip优化器解决了万亿模型稳定训练的难题,到大规模数据合成流水线为智能体能力提供了充足“养料”,再到融合客观与主观的强化学习框架实现了能力的全面对齐,Kimi K2的诞生过程,本身就是一篇关于如何构建下一代AI的精彩论文。
其在各大基准测试中全面领先的性能,特别是在软件工程、工具使用等核心智能体任务上的惊艳表现,雄辩地证明了这条技术路线的正确性和巨大潜力。它告诉我们,通过精巧的算法设计、大规模的工程实践和深刻的AI原理洞察,开源模型完全有能力在代表未来的“智能体”赛道上,与最顶尖的闭源模型一较高下。
更重要的是,Kimi团队选择将这一凝聚了无数心血的成果完全开源。这一举动,无疑将极大地激发全球开发者的创造力,加速智能体应用的落地。小到个人开发者,大到科技企业,都可以站在Kimi K2这个巨人的肩膀上,去探索、去创造、去构建属于自己的智能体应用,共同推动AGI时代的到来。
我们有理由相信,Kimi K2不是终点,而是一个全新的起点。一个由开源力量驱动,向着更高层次智能——Agentic Intelligence——全速前进的新时代的起点。未来已来,让我们拭目以待。
参考文献与链接
为方便读者查阅,以下列出报告中引用的部分重要文献的展开链接:
[1] Austin, J., et al. (2021). Program Synthesis with Large Language Models. https://arxiv.org/abs/2108.07732[6] Chen, C., et al. (2025). ACEBench: Who Wins the Match Point in Tool Learning? arXiv:2501[7] Chen, M., et al. (2021). Evaluating Large Language Models Trained on Code. https://arxiv.org/abs/2107.03374[10] DeepSeek-AI. (2024). DeepSeek-V3 Technical Report. https://arxiv.org/abs/2412.19437[32] Jimenez, C. E., et al. (2024). SWE-bench: Can Language Models Resolve Real-world Github Issues? https://openreview.net/forum?id=VTF8yNQM66[33] Jordan, K., et al. (2024). Muon: An optimizer for hidden layers in neural networks. https://kellerjordan.github.io/posts/muon/[35] Kimi Team. (2025). Kimi k1. 5: Scaling reinforcement learning with llms. arXiv:2501.12599[58] Qin, Y., et al. (2023). Toolllm: Facilitating large language models to master 16000+ real-world apis. https://arxiv.org/abs/2307.16789[72] Vaswani, A., et al. (2017). Attention is All you Need. https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
技术交流
加入「AI生成未来社区」群聊,一起交流讨论,涉及 图像生成、视频生成、3D生成、具身智能等多个不同方向,备注不同方向邀请入群!可添加小助手备注方向加群!

 扫码添加微信
扫码添加微信
- 点赞 (0)
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊





