


动脑就能P图!LoongX重磅突破:首个「脑波+AI」图像编辑系统诞生,意念修图不是梦!
- 2025-07-21 00:01:00
如您有工作需要分享,欢迎联系:aigc_to_future
作者:Pengfei Zhou等


论文链接:https://arxiv.org/pdf/2507.05397
主页链接:https://loongx1.github.io/
亮点直击
L-Mind:一个多模态数据集,包含 23,928 对图像编辑样本,配套采集了在自然环境下的脑电(EEG)、功能性近红外光谱(fNIRS)、脉搏波(PPG)、动作和语音信号。 LoongX:一种新颖的神经驱动图像编辑方法,结合了 CS3 和 DGF 模块,用于高效的特征提取和多模态信息融合(效果见下图 1)。 大量实验证实多模态神经信号的有效性,并深入分析了各模态的特定贡献及其与语音输入之间的协同作用。

总结速览
解决的问题
传统图像编辑依赖手动提示,存在以下问题:
操作复杂、劳动强度大; 对于运动能力或语言能力受限的人群不友好; 缺乏自然直观的人机交互方式。
提出的方案
LoongX:一种基于多模态神经生理信号的免手图像编辑方法,主要特点包括:
利用脑机接口(BCI)获取用户意图; 通过多模态信号(EEG、fNIRS、PPG、头部动作、语音)驱动图像编辑; 结合跨尺度状态空间(CS3)和动态门控融合(DGF)模块,实现高效特征提取与信息融合; 在扩散模型(DiT)基础上微调以对齐图像编辑语义。
应用的技术
多模态神经信号采集:包括脑电(EEG)、功能性近红外光谱(fNIRS)、脉搏波(PPG)、头部动作和语音信号; CS3 模块:提取不同模态中具有区分性的特征; DGF 模块:实现多模态特征的动态融合; 扩散Transformer(DiT):作为图像生成的核心模型,通过微调实现语义对齐; 对比学习:预训练编码器,将认知状态与自然语言语义对齐; 大规模数据集 L-Mind:包含 23,928 对图像编辑样本及其对应的多模态神经信号。
达到的效果
LoongX 在图像编辑任务中表现优异,性能可与文本驱动方法媲美,甚至在与语音结合时超过现有方法: CLIP-I:LoongX 0.6605 vs. 文本基线 0.6558; DINO:LoongX 0.4812 vs. 文本基线 0.4636; CLIP-T(结合语音):LoongX 0.2588 vs. 文本基线 0.2549; 实验验证了多模态神经信号在图像编辑中的有效性; 分析了各模态信号的贡献及其与语音输入的协同作用; 展示了神经驱动生成模型在提升图像编辑可达性和自然交互方面的潜力; 为认知驱动的创意技术打开了新的研究方向。
数据集
数据采集
从 12 位参与者处收集了 23,928 个编辑样本(22,728 个用于训练,1,200 个用于测试),使用的设置如下图 2 所示。参与者佩戴我们的多模态传感器,在 25 英寸显示器上(分辨率:1980 × 1080)查看来自 SEED-Data-Edit 的图文对。所测得的 EEG、fNIRS 和 PPG 生理信号通过蓝牙 5.3 实时传输,并通过专有 Lab Recorder 软件中的 lab streaming layer 进行同步和对齐。参与者同时朗读所显示的编辑指令,以提供语音信号。
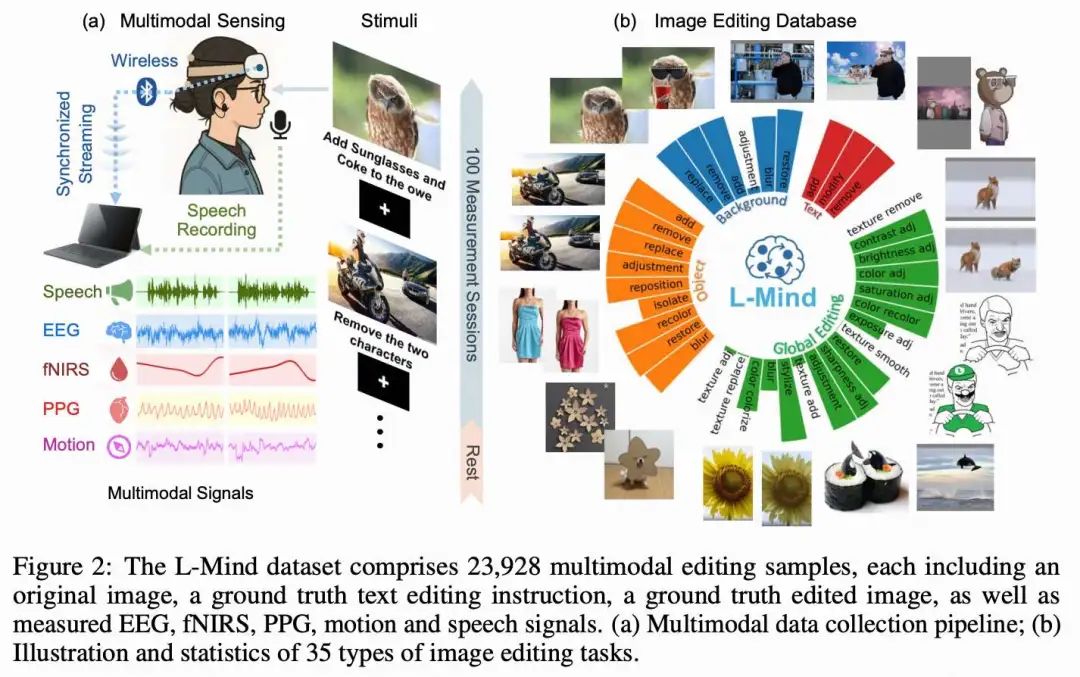
实验在一个安静、温度控制的房间内进行(24°C,湿度恒定),每天上午 9 点开始。EEG 信号通过非侵入式水凝胶电极采集,每五小时更换一次电极以保持信号质量。实验室遮光以防止阳光干扰 fNIRS 和 PPG 信号。每次实验由参与者自主控制音频录制的开始和结束,并以图像名称标记。非活动时间段的数据被排除。
每次实验(上图 2)由用户启动的音频录制开始和结束,并以图像配对标记。每对图像后有 1 秒的交叉注视,每 100 张图像后安排一次休息。共有 12 名健康的大学生参与(6 名女性,6 名男性;平均年龄:24.5 ± 2.5 岁),视力正常或矫正正常。所有参与者均签署了知情同意书,并获得了经济补偿。本研究已获得相应机构伦理委员会的正式批准。
数据预处理
EEG:四个 EEG 通道(Pz、Fp2、Fpz、Oz;采样率为 250 Hz)经过带通滤波(1–80 Hz)和陷波滤波(48–52 Hz),以去除漂移、噪声和电源干扰。Fp2 和 Fpz 中的眼动伪迹被保留,以捕捉眼动信息。
fNIRS:六通道 fNIRS 信号(波长为 735 nm 和 850 nm)根据修正的 Beer–Lambert 定律转换为相对血红蛋白浓度变化(HbO、HbR、HbT)。光密度变化计算公式为:
浓度变化计算如下:
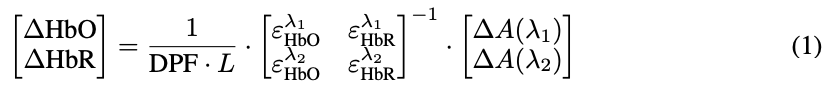
血流动力学信号(HbO、HbR 和 HbT,其中 HbT = HbO + HbR)经过带通滤波(0.01–0.5 Hz)以提取相关的神经反应,并在每个半球内取平均,以反映任务相关的大脑活动。
PPG 和运动:四通道 PPG 信号(735 nm,850 nm)通过自适应平均池化在每个半球内取平均,并经过滤波(0.5–4 Hz)以提取反映心率变异性的心脏相关血流动力学信号。来自六轴传感器(12.5 Hz)的运动数据捕捉三轴线性加速度和角速度,用于表征头部运动。
方法
如下图 3 所示,LoongX 从多种神经信号中提取多模态特征,并以成对方式将其融合到共享隐空间中。使用扩散Transformer(Diffusion Transformer,DiT),原始图像在融合特征的条件下被转换为编辑后的图像。围绕三个研究问题,我们进行了一个多标签分类实验,结果显示 EEG 比噪声高出 20%,而融合所有信号可获得最高的 F1 分数。将神经信号与文本结合可实现最佳的 mAP,验证了模态间的互补性。输入长度为 8,192 时性能最佳,但计算成本更高,这推动了我们框架的设计:用于长序列的跨尺度状态空间编码器和用于特征整合的动态门控融合模块。
跨尺度状态空间编码
CS3 编码器使用自适应特征金字塔从多种信号中提取多尺度特征。为了进一步捕捉超越固定金字塔的动态时空模式,CS3 使用结构化状态空间模型(S3M)以线性复杂度高效地编码长序列。为控制成本,它采用跨特征机制分别编码时间和通道信息。
金字塔编码:将单一模态输入信号 输入到一个 N 层(例如 EEG 设置为 )的自适应平均池化(AAP)模块中(我们为 EEG 设置 ):
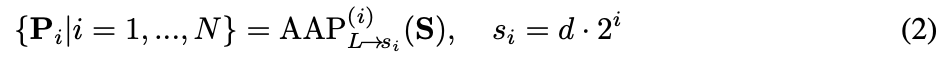 提取的嵌入表示通过特征金字塔的拼接计算得到,。
提取的嵌入表示通过特征金字塔的拼接计算得到,。
状态空间编码:为了充分利用神经信号中的时间和通道依赖关系,我们设计了一种交叉形状的时空编码方案,其中一个轴专注于时间模式,另一个轴专注于通道动态。
具体来说,输入信号 从长度 填充到 ,填充后的信号为 ,其信号强度被归一化到 。填充后的信号及其转置版本 被分别输入到两个并行的 S3M 模块中,分别为 和 :
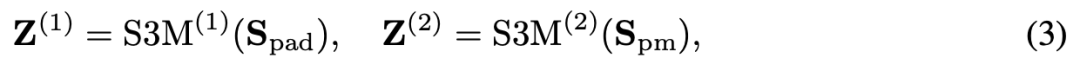 其中每个 S3M 模块使用连续时间对角状态空间模型:
其中每个 S3M 模块使用连续时间对角状态空间模型:
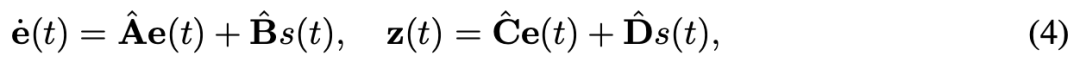
其中 表示时间 的潜在状态,、、、 是参数化状态转移、输入注入、状态到输出映射以及输入到输出直接映射的对角矩阵。由于采用了对角参数化,S3M 模块支持具有线性复杂度 的高效计算。通过 S3M 模块, 从长度 下采样到 ,得到 ; 经过进一步置换并通过 AAP 下采样到长度 ,得到 ,其中 设置为 。
交叉金字塔聚合:编码器沿通道维度融合多尺度和时间流,结果为:
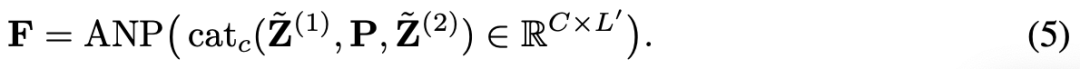
其中 。拼接后的特征通过自适应非线性投影(Adaptive Nonlinear Projection,ANP)进行投影,ANP 由两个全连接层、LayerNorm、ReLU 和 dropout 组成。最终获得嵌入特征 。
动态门控多模态融合
提出了动态门控融合(Dynamic Gated Fusion,DGF)模块,用于将一对内容嵌入和条件嵌入动态绑定到统一的隐空间中,并进一步与文本嵌入对齐。DGF 包括门控混合、自适应仿射调制以及动态掩码模块。
门控混合:从输入的内容嵌入(例如 EEG) 和条件嵌入(例如 PPG) 中计算实例级和层级的均值 和方差 ,以进一步融合为 ,同时强调信息通道并抑制噪声:
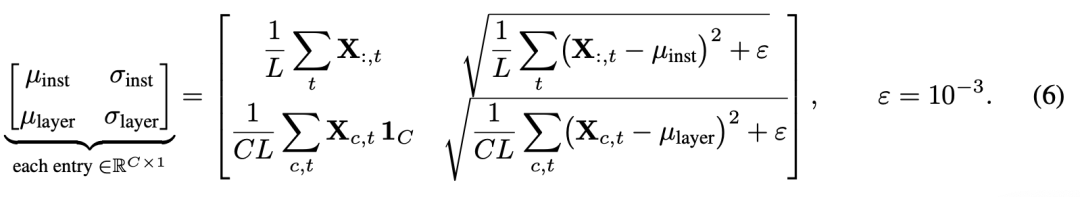
其中 是用于数值稳定性的正则项, 是单位向量。一个一维门控网络 被用来从 中计算每个通道的权重 ,用于自适应地混合统计信息。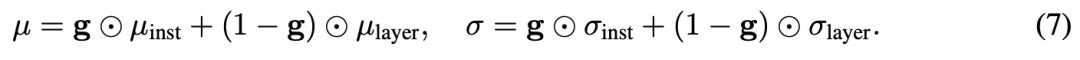 然后,内容特征通过自适应门控的均值 和标准差 进行归一化:
然后,内容特征通过自适应门控的均值 和标准差 进行归一化:
自适应仿射调制。 条件特征通过全局平均池化(GAP)进行平均,表示为 。该平均特征随后被送入仿射网络 ,该网络由一个多层感知机(MLP)组成。输出被分成两个仿射系数 和 。
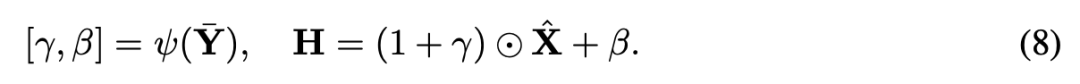 动态 masking。 通道重要性得分 被计算用于从调制特征中选择前 个通道(,)。此外,应用一个二值 mask 。
动态 masking。 通道重要性得分 被计算用于从调制特征中选择前 个通道(,)。此外,应用一个二值 mask 。

最后,融合后的潜在特征 与原始的提示/文本嵌入进行残差融合,然后被输入到 DiT 解码器中。由于 DGF 可作用于任意的 张量,因此它在 LoongX 中处理四种模态融合类型:EEG-PPG、fNIRS-Motion、neural-prompt 和 neural-pooled-prompt。
条件扩散
融合后的隐空间表示用于对 DiT 主干进行条件控制以进行图像编辑。DiT 模型接收编码后的输入图像 和融合后的潜在特征 ,并通过微调输出与语义意图一致的编辑图像。
具体而言,DiT 预测一个速度 ,该速度用于在 个均匀步骤中迭代地优化潜在图像。
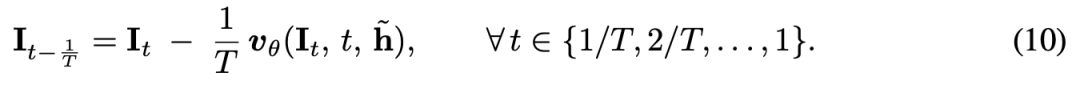
在推理阶段,应用公式 (10) 直到 ,得到编辑后的图像 。
预训练与微调
采用一个两阶段的过程:
1)神经信号编码器(EEG 是最重要的)在神经-文本语料库上进行预训练,压缩公共数据和 L-Mind;
2)整个系统可选地使用原始图像与真实编辑图像对进行微调。
预训练。信号编码器通过使用大规模认知数据集和 L-Mind 进行预训练,以与语义嵌入对齐。CS3 编码器(分别为 EEG + PPG 和 fNIRS + Motion)通过对称的 NT-Xent 损失与冻结的文本嵌入对齐:
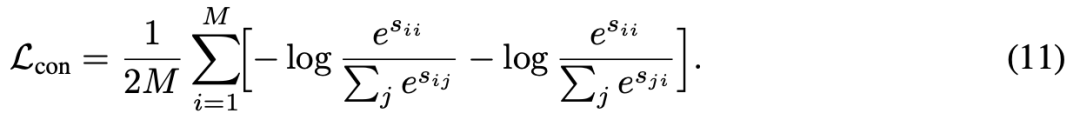
其中 , 和 分别是神经和文本嵌入, 是神经模态的数量。在预训练期间,信号编码器是可学习的,而文本编码器保持冻结。
微调。编码器和 DiT 在 L-Mind 上联合微调,将用户的神经模式映射到编辑目标,遵循一个标准的扩散目标函数,最小化均方速度误差。
对于输入图像 和高斯噪声 ,其中 是累积的噪声调度:
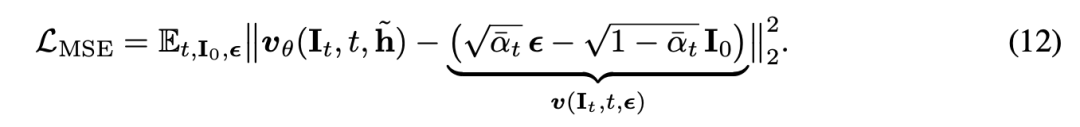
实验
为回答第 1 节中提出的每个研究问题(RQ),在 L-Mind 的测试集上全面评估了 LoongX 在神经驱动图像编辑方面的能力。实验设置、指标来自于 [51]。选择 OminiControl 作为基线方法,因为它支持基于 DiTs 的文本条件图像编辑。
神经信号的可靠性
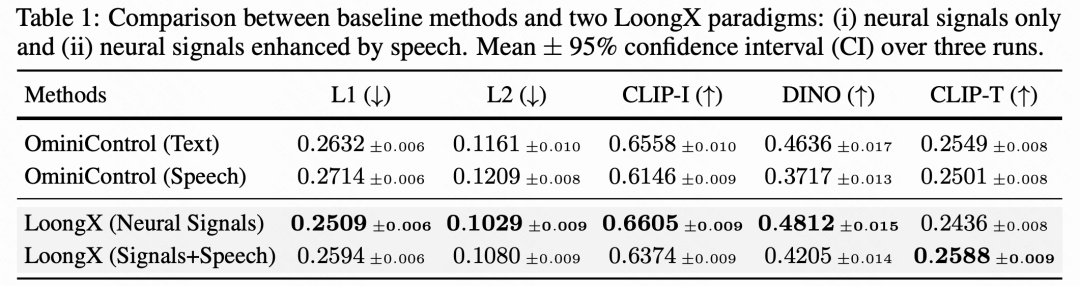
回答 RQ1:如下表 1 所示,神经信号可以作为可靠的指示器来驱动语义和结构图像编辑,在关键感知指标上优于仅使用语言的基线。值得注意的是,仅使用神经信号的 LoongX 在可辨识性(CLIP-I: vs. )和鲁棒性(DINO: vs. )方面超过了基于文本的 OminiControl 基线。这表明神经信号在图像编辑中具有传递可靠语义信息的内在能力。尽管像素级指标(L1/L2)略有上升,但这一权衡凸显了语义保真度优先于像素级粘附性的策略。引入与神经信号融合的语音提示进一步增强了语义对齐(CLIP-T 达到最高 ),强调了它们在捕捉细致用户意图方面的联合优势,适用于免手图像编辑。
模态贡献的消融研究
回答 RQ2:不同的神经信号模态具有互补优势,分别增强了可辨识性、鲁棒性和语义精度。我们详细分析了模态贡献,如下图 4 所示。仅使用 EEG 信号即可实现基本的高级语义编辑,这得益于其提取特征的语义可辨识性(CLIP-I:)。加入 fNIRS 显著提升了特征的鲁棒性(DINO:从 提升至 ),突显了血流动力学响应在增强信号完整性和结构保真度方面的互补特性。加入 PPG 和 Motion 提升了整体生理感知能力,并体现出对细微参与模式(如心跳和用户动作)的敏感性,这些模式表达了编辑意图。它们共同提升了特征的鲁棒性和完整性,从而确保 CLIP-T 得分的稳定提升。

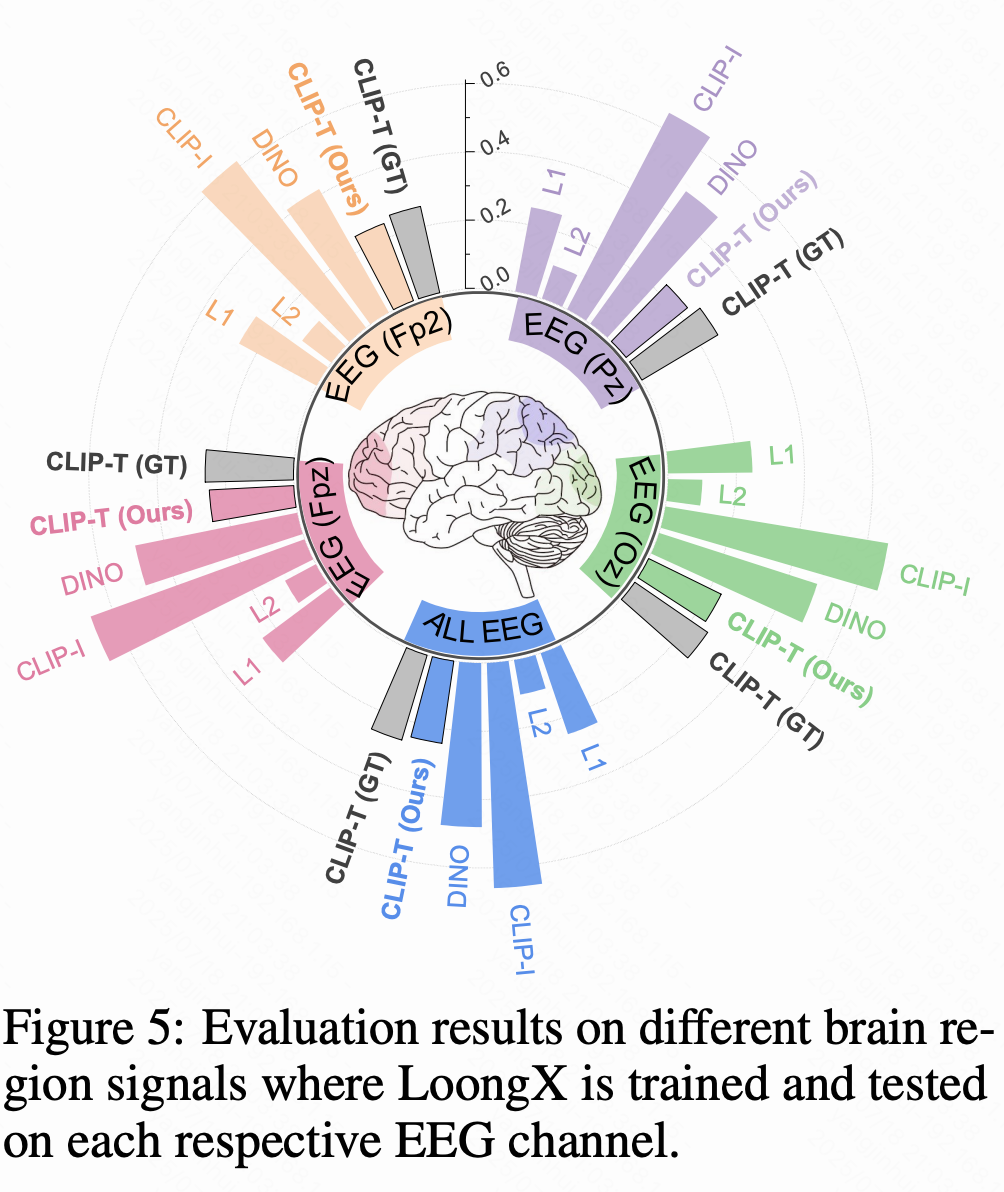
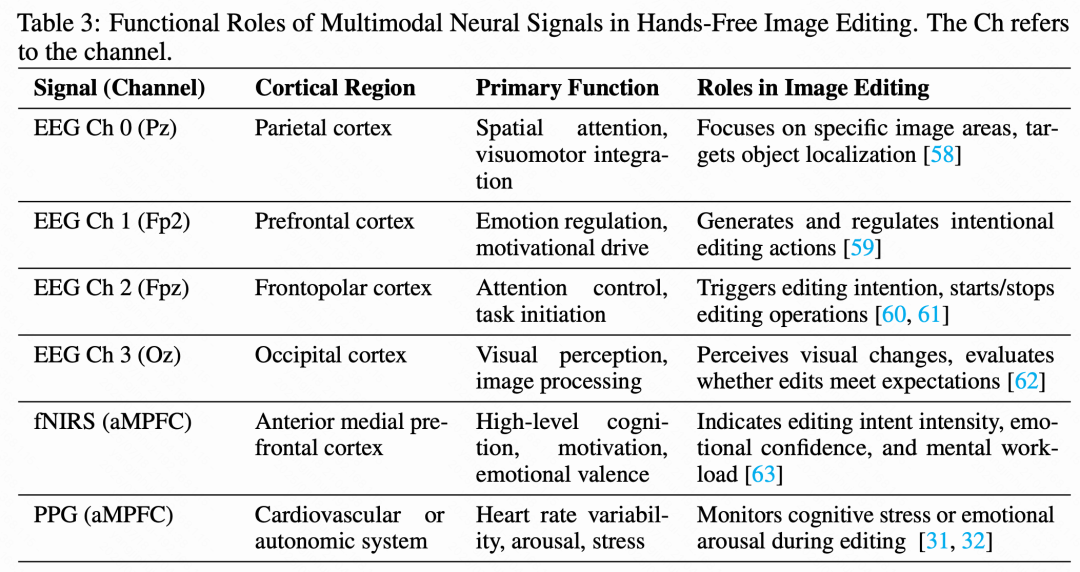
下图 5 进一步探讨了 EEG 各通道的个体贡献,每个通道对应于下表 3 中详述的特定头皮区域。负责视觉处理的枕叶皮层通道(Oz)在整体编辑效果(CLIP-I:)和鲁棒性(DINO:)方面表现突出,确认了其在基本视觉感知与处理任务中的关键作用。相反,前额极皮层(Fpz)在语义对齐方面表现更优(CLIP-T:),这与其在复杂认知过程中的作用一致。具体而言,Fpz 提供决策控制与注意力调节,而 Oz 提供基本的视觉感知,这一发现与医学解剖学中的认知模式完全吻合。该通道级别的分析为面向目标应用或受限硬件设置提供了有价值的见解。
细分分析:神经条件 vs. 语言条件
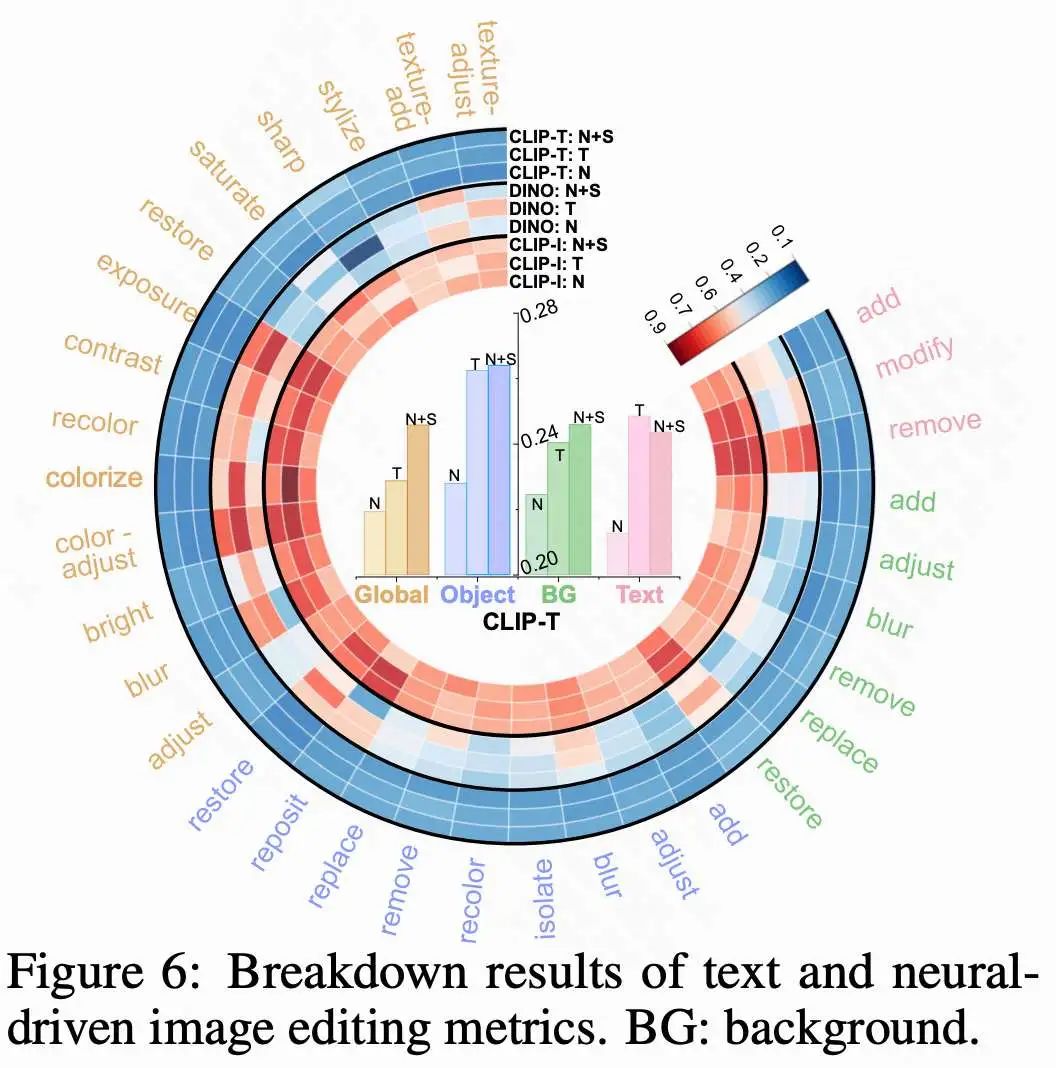
回答 RQ3:神经信号在低层次视觉编辑中表现出色,而语言在高层次语义方面更具优势;两者结合可实现最有效的混合控制。如下图 6 所示,神经信号(N)在更直观的任务中尤为有效,如全局纹理编辑(更高的 CLIP-I),反映出较强的视觉可辨识性和结构一致性。在对象编辑中,神经信号在对象移除方面比其他方法更具能力,展示了其在传达直观意图方面的优势,尽管在处理复杂语义方面仍有局限。相比之下,文本指令(T)在高层语义任务中(例如“恢复”)本质上更强,突显其在语义对齐方面的优势。当两者结合时,神经信号和语音(N+S)输入实现了最佳语义对齐(CLIP-T: ),展示了混合条件在捕捉复杂用户意图方面的卓越效果。
模型架构的消融研究
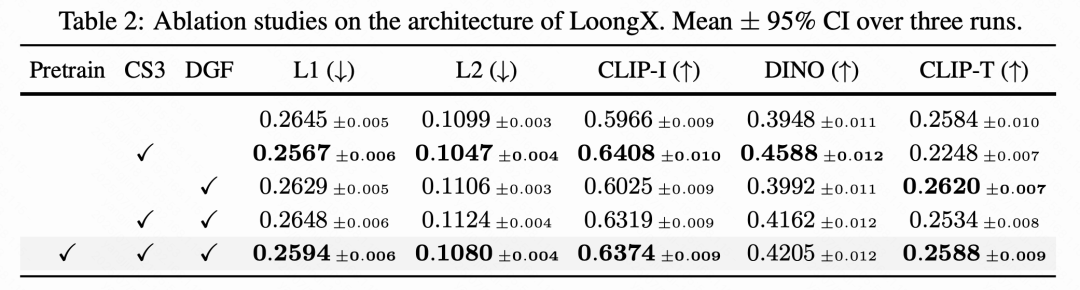
LoongX 的每个架构组件都有其独特贡献,尤其是在预训练的辅助下,其组合释放了全面的性能潜力。下表 2 中的消融研究在融合所有信号和语音的设置下进行,探索每个提出模块的影响。CS3 编码器通过提取的特征增强了特征的完整性和平滑性,减少了像素级误差(L2 降低了 5%),而 DGF 主要增强了与文本指令的语义对齐(CLIP-T 提升:)。在预训练的辅助下,LoongX 达到最优性能,表明鲁棒的多模态对齐和结构化表示学习在最大化编辑性能中的重要作用。
定性分析与局限性
定性示例证实了 LoongX 的直观编辑能力,其局限性主要出现在抽象或模糊的复杂意图中。下图 7 中的定性结果表明,神经信号驱动的编辑能够有效处理视觉和结构修改,如背景替换和全局调整。然而,融合神经与语言的方法更能捕捉涉及抽象语义的细致指令(例如“修改文本信息”)。尽管取得了显著进展,实体一致性(例如下图 7(b) 中小女孩的风格)仍是当前编辑模型的局限。此外,高度抽象或模糊的指令有时仍构成挑战(例如“下图 11 中的带翅膀的白色动物”以及下图 14 中展示的多个失败案例),这表明在神经数据中对实体解释和消歧的进一步优化仍有必要。



结论
LoongX,这是一个通过多模态神经信号调控扩散模型实现免手图像编辑的新颖框架,其性能与传统的文本驱动基线相当或更优。展望未来,无线设置的可移植性为沉浸式环境中的真实应用打开了激动人心的可能性。未来的工作可以探索将 LoongX 集成到 VR/XR 平台中,以实现直观的认知交互,并进一步将神经表示与世界模型对齐,从而将人类意图投射到交互式虚拟世界中,为在完全合成现实中的意念控制铺平道路。
参考文献
[1] Neural-Driven Image Editing
致谢
如果您觉得这篇文章对你有帮助或启发,请不吝点赞、在看、转发,让更多人受益。同时,欢迎给个星标⭐,以便第一时间收到我的最新推送。每一个互动都是对我最大的鼓励。让我们携手并进,共同探索未知,见证一个充满希望和伟大的未来!
技术交流
加入「AI生成未来社区」群聊,一起交流讨论,涉及 图像生成、视频生成、3D生成、具身智能等多个不同方向,备注不同方向邀请入群!可添加小助手备注方向加群!


 扫码添加微信
扫码添加微信
- 点赞 0
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊






