


三篇顶刊炸场!清华团队晶圆级芯片取得重大进展
- 2025-07-21 16:08:53

中国AI芯片产业创新正与国际同步。
清华团队三连击:晶圆级芯片成果登顶 ISCA,为 AI 算力破局立标杆
2025 年国际计算机体系结构研讨会(ISCA)上,清华大学集成电路学院尹首一、胡杨团队的三篇论文同时亮相,将晶圆级芯片这一前沿技术推向国际学术聚光灯下。作为计算机体系结构领域的 “顶流盛会”,ISCA 自 1973 年创办以来便被誉为 “创新风向标”,其收录成果代表全球前沿突破 —— 此次清华团队的三连发,不仅标志着我国在晶圆级芯片领域的研究跻身国际第一梯队,更为 AI 算力突破 “卡脖子” 瓶颈提供了全新技术路径。
《PD Constraint-aware Physical/Logical Topology Co-Design for Network on Wafer》
聚焦晶圆级芯片计算架构,针对硅互连基板的物理约束(面积、互连长度、布线层数),提出 “Tick-Tock” 协同设计框架,融合 Mesh 与 Fat tree 特性构建 Mesh-Switch 物理拓扑,实现主流大模型训练吞吐较特斯拉 Dojo 提升 2.39 倍,确立物理与逻辑拓扑协同优化新范式。
《Cramming a Data Center into One Cabinet, a Co-Exploration of Computing and Hardware Architecture of Waferscale Chip》
面向晶圆级芯片集成架构,针对垂直堆叠的异构单元(算力芯粒、存储、散热等)设计难题,提出纵向面积约束引导的跨物理层协同优化方法,相同成本下系统算力提升 2.90 倍、通信带宽提升 2.11 倍、内存带宽提升 11.23 倍,实现单柜级 “片上数据中心” 集成。
《WSC-LLM: Efficient LLM Service and Architecture Co-exploration for Wafer-scale Chips》
解决大模型推理在晶圆级芯片上的映射问题,针对大模型 prefill 和 decode 阶段特性设计分离式调度方法,通过 KV cache 管理实现资源高效利用,在典型推理任务中性能较先进 GPU 集群提升 3.12 倍,建立架构探索与编译映射全流程优化方法。
基于可重构AI芯粒的晶圆级芯片验证样机
晶圆级芯片:AI 算力的 “明日之星” 与技术颠覆者
在 AI 大模型参数规模突破万亿、算力需求呈指数级增长的当下,传统芯片正遭遇 “双重天花板”:一方面,先进制程受限于海外技术封锁,国内难以获取最顶尖的工艺;另一方面,单芯片面积被光刻技术死死卡在 858 平方毫米,晶体管集成量难以突破,算力上限触手可及。更棘手的是,多芯片通过传统封装互连时,信号需经过中介层、PCB、交换机等多层链路,延迟高、密度低,严重制约系统性能。
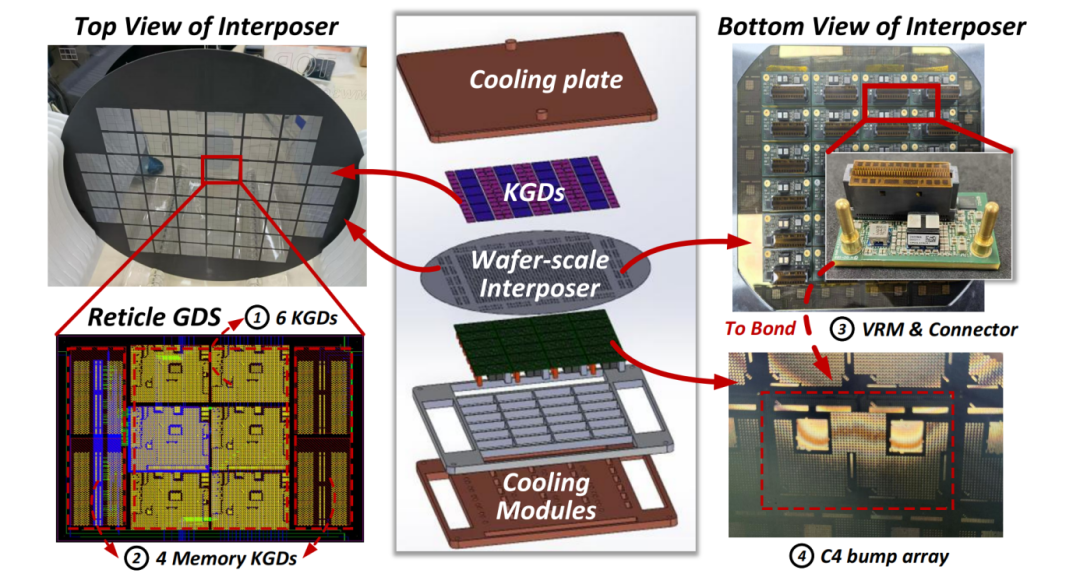
晶圆级芯片的横空出世,正是对这一困境的颠覆性回应。它打破 “单芯片” 思维,以 “One Wafer One Chip” 为核心 —— 将整片 12 寸晶圆(面积约 40000 平方毫米)作为基底,通过高密度硅互连集成数十颗算力芯粒,构建出 “片上数据中心”。相较于传统芯片,其面积是常规芯片的 46 倍,互连密度提升千倍以上,单机柜算力密度可达现有方案的 2 倍以上,堪称 “AI 算力的超级航母”。
这种技术不仅是 “做大芯片”,更是系统级的集成革命:它需统筹计算、存储、供电、散热等多维度协同设计,将整个智算系统压缩至晶圆尺度。正如尹首一团队所指出的,晶圆级芯片的本质是 “计算架构 - 集成架构 - 编译映射” 的深度耦合,而这正是其突破传统算力极限的核心密码。

以Chiplet技术为基础的晶圆级芯片制造流程
从理论到架构:尹首一团队的 “三维突破”
尹首一团队自 2020 年起瞄准晶圆级芯片,以 “计算架构” 与 “集成架构” 为双引擎,构建了一套完整的技术体系,此次三篇 ISCA 论文正是这一体系的集中体现。
在计算架构层面,团队博士杨启泽主导的研究直击 “全晶圆互连” 难题。受限于硅基板面积、布线层数(少于 3 层)和互连长度(不超过 50mm),传统拓扑结构难以适配超大规模集成。团队创新提出 “Tick-Tock” 协同框架,融合 Mesh 高集成度与 Fat tree 高效通信特性,设计出 Mesh-Switch 物理拓扑,并开发物理约束感知的搜索算法,使大模型训练吞吐较特斯拉 Dojo 提升 2.39 倍,确立了物理与逻辑拓扑协同优化的新范式。
集成架构研究则聚焦 “垂直空间利用”。硕士余幸懋团队发现,晶圆级芯片是算力芯粒、存储模组、散热层等异构单元的垂直堆叠体,各层参数耦合紧密,传统设计难以兼顾性能与密度。他们首创 “纵向面积约束” 方法,将功率、信号传递等指标转化为跨层优化目标,使同成本下系统算力提升 2.9 倍、内存带宽提升 11.23 倍,其设计密度超越特斯拉 Dojo 整机架构,为 “单柜即数据中心” 提供了工程蓝图。
针对大模型推理落地,博士徐铮团队提出的 WSC-LLM 方案解决了 “算力与任务不匹配” 痛点。该方案针对大模型 prefill(填充)与 decode(解码)阶段的差异化需求,设计分离式映射调度,通过 KV cache 智能管理实现资源高效利用,在典型任务中性能较 GPU 集群提升 3.12 倍,验证了晶圆级芯片在 AI 推理中的实用价值。
产学研闭环:从论文到样机的 “清华速度”
学术突破的背后,是 “从理论到产品” 的高效转化。依托三大核心技术,尹首一团队联合清华系企业研发出可重构算力网格芯粒,并与上海人工智能实验室合作,成功造出国内首台基于可重构 AI 芯粒的 12 寸晶圆级芯片验证样机。这台样机不仅验证了 “用次世代工艺集成赶超先进制程” 的可行性,更通过工程实践反哺理论研究,形成 “学术 - 技术 - 产业” 的闭环。
目前,团队成果已服务于多家头部企业,在智算中心、大模型训练等场景落地。这种 “产学研用” 模式,正是清华在芯片领域的独特优势 —— 以尹首一教授为代表的科研力量,既深耕学术前沿(其因 “高能效 AI 芯片架构” 贡献当选 IEEE Fellow,是 ISCA 名人堂成员),又锚定产业需求,让技术突破真正转化为破局 “卡脖子” 的实力。

全球竞逐下的中国路径:从跟跑到领跑
全球科技巨头早已嗅到晶圆级芯片的潜力:特斯拉 Dojo 集成 25 颗 D1 芯粒,算力达 9PFlops;Cerebras WSE-3 以 5nm 工艺集成 4 万亿晶体管,互连带宽是英伟达 H100 的 3715 倍;台积电则推进 System-on-Wafer(SoW)技术,计划 2027 年量产。
在这场竞赛中,尹首一团队的成果凸显 “中国特色”:不依赖最先进制程,而是通过架构创新与集成优化实现赶超。其提出的可重构芯粒方案,既规避了海外工艺封锁,又通过晶圆级集成突破算力上限,为国内芯片产业提供了 “换道超车” 的技术路线。正如尹首一在 ICDIA 大会上提出的 STCO(系统技术协同优化)理念,这种 “架构 - 工艺 - 系统” 的协同创新,正是破解 “卡脖子” 难题的关键。
从 ISCA 的学术突破到验证样机的工程落地,清华团队以晶圆级芯片为支点,不仅撑起了 AI 算力的 “中国脊梁”,更证明:在芯片领域,中国正从技术跟跑者,成长为规则制定者。这颗 “片上数据中心” 的崛起,或许正是 AI 算力革命的下一个起点。
END

 点击了解活动详情
点击了解活动详情往期精选:

请点下【♡】给小编加鸡腿


 扫码添加微信
扫码添加微信
- 点赞 0
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊







