加利福尼亚大学!EgoVLA:从第一视角人类视频中学习VLA模型
- 2025-07-21 08:00:00
点击下方卡片,关注“具身智能之心”公众号
作者丨Ruihan Yang等
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。

研究背景与核心思路
传统机器人模仿学习依赖于大规模真实机器人数据,但受限于硬件和操作成本,数据规模和任务多样性难以突破。相比之下,人类在各类环境中的操作行为构成了海量潜在训练数据——全球数十亿人在机器人期望工作的场景中持续活动,其第一视角视频涵盖了机器人难以进入的空间或远程操作困难的任务。
核心突破在于:人类与机器人的动作空间差异可通过几何变换近似。无需直接基于机器人数据训练视觉-语言-动作(VLA)模型,而是先在人类第一视角视频上训练模型,再通过少量机器人演示微调,即可实现技能迁移。这种思路既能利用人类数据的规模和多样性,又能通过微调适配机器人本体(figure 5)。

模型架构与动作空间设计
整体框架
以NVILA-2B为基础框架,借助其视觉-语言理解能力和紧凑性,实现高效的意图推理与微调。输入包括:当前及历史第一视角视觉观测(3 FPS采样,覆盖1秒内5帧历史)、语言指令(描述即时目标)、动作查询token(词汇表最后30个ID)和人类本体感觉(手腕位姿、手部姿势参数)。这些输入经VLM backbone编码后,由动作头(含6个编码器层,隐藏层大小1536)预测未来1秒内(30 Hz采样,30步)的动作序列(figure 2)。

动作空间与转换
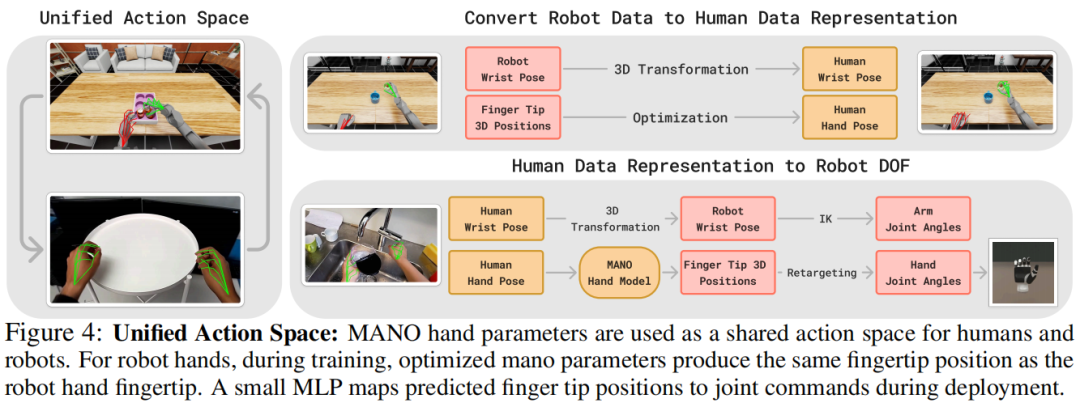
动作空间采用人类手腕位姿(3D平移和rot6D旋转)和MANO手模型的前15个PCA主成分,兼顾紧凑性与表达力。通过统一动作空间实现人类到机器人的动作迁移:
手腕位姿:通过3D变换对齐坐标系,结合逆运动学转换为机器人末端执行器位置。 手部姿势:通过最小化指尖位置差异,用MANO参数近似机器人手部动作,再通过一个四层MLP(隐藏层大小[64,128,64])将指尖位置转换为机器人关节指令(figure 4)。
训练损失函数为:
其中,和为L2损失(分别针对手腕平移和手部关节角回归),为rot6D旋转损失。
数据集构建
整合四个来源的第一视角视频,形成大规模人类操作数据集:
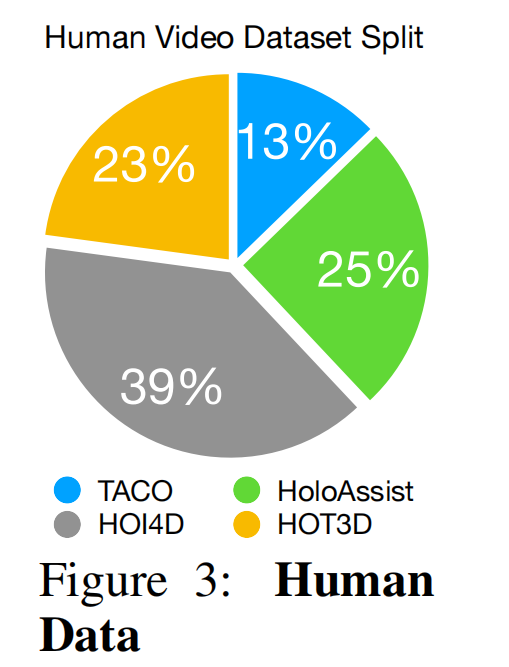
数据组成:包含约50万图像-动作对,涵盖TACO(23%)、HOI4D(25%)、HoloAssist(39%)、HOT3D(13%),涉及33种刚性物体,标注有RGB观测、手腕位姿、手部姿势和相机位姿(figure 3)。
处理策略:通过世界坐标系相机位姿,将未来手腕位置投影到当前相机帧,解决相机运动带来的标注不一致;按3 FPS采样平衡计算效率与时间连续性。 数据平衡:因HoloAssist标签噪声较大,仅采样其1/10数据以平衡任务分布。
评估基准:Ego Humanoid Manipulation Benchmark
为统一评估类人机器人操作能力,基于NVIDIA IsaacSim构建仿真基准,包含12个任务:
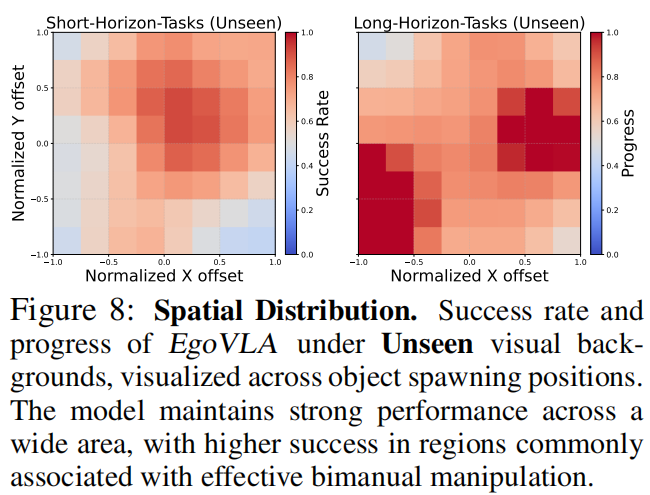
任务类型:涵盖短视距原子动作(如推箱子、翻转杯子、倒球等)和长视距多阶段动作(如分类罐子、插入并取出罐子等)(figure 5)。 机器人与环境:采用Unitree H1类人机器人(配备Inspire灵巧手),提供5种房间纹理和5种桌子纹理,形成25种视觉背景组合以测试泛化能力。 评估方式:每个任务提供100条演示数据,通过成功率(SR)和进度率(PSR,子任务完成比例)评估,支持对视觉多样性和物体位置随机性的鲁棒性测试(figure 8)。
实验结果与关键发现
人类预训练提升核心性能
在seen视觉背景下,经人类数据预训练的EgoVLA在短视距和长视距任务中均显著优于无预训练的基线(EgoVLA-NoPretrain)。尤其在精细操作(如堆叠罐子)和长视距任务中,成功率提升约20%,证明人类数据能学习通用操作技能(table 1、table 2)。


增强泛化能力
在unseen视觉背景下,EgoVLA短视距任务成功率仅小幅下降,而无预训练模型下降23%;长视距任务虽成功率降低,但进度率保持稳定,说明失败多发生在任务末期而非早期子目标,体现对新环境的适应力(table 1、table 2)。
数据规模与多样性的影响
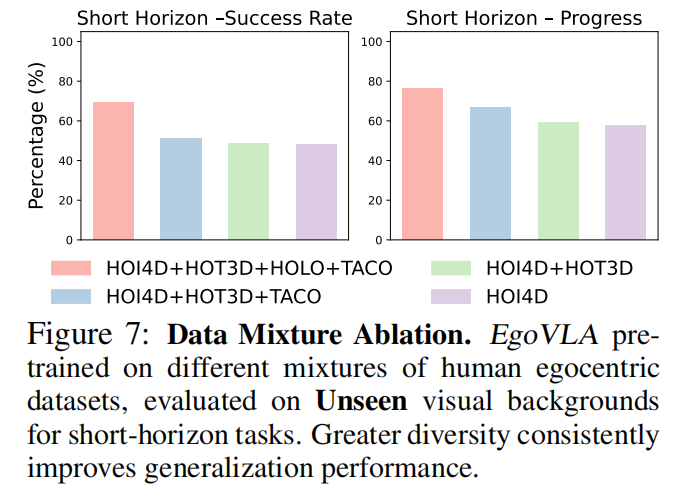
人类数据多样性越高,模型泛化越好:整合TACO+HOI4D+HoloAssist+HOT3D的模型,在短视距任务上的成功率和进度率显著高于单一数据集训练的模型(figure 7)。
机器人数据规模影响最终性能:仅用50%机器人演示数据的EgoVLA(50%)性能明显下降,尤其长视距任务,说明人类预训练需结合一定量机器人数据才能达到最佳效果(table 1、table 2)。
局限
依赖带手腕和手部姿势标注的人类数据,虽AR/VR设备普及可能缓解此问题,但当前数据获取仍有局限。 需少量机器人数据微调才能部署,零样本迁移能力不足,未来可探索更具本体无关性的预训练方法以提升迁移效率。
参考
[1]EgoVLA: Learning Vision-Language-Action Models from Egocentric Human Videos

 扫码添加微信
扫码添加微信
- 点赞 0
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊