


IROS 2025 Oral|无界智慧推出3D-MoRe:助力空间理解,提升复杂三维环境中的推理能力
- 2025-07-20 00:00:00

点击下方卡片,关注“具身智能之心”公众号
作者丨Rongtao Xu等
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
本文一作:许镕涛 无界智慧联合创始人兼CTO,Rongtao-Xu.github.io。中科院自动化所博士, 在学期间曾获得中科院院长奖、两次IEEE旗舰会议最佳论文提名奖、国奖、北京市和中科院优秀毕业生。华中科技大学数学与计算机双学位。研究方向聚焦具身智能与机器人,提出首个基于空间可供性操作大模型A0,曾在银河通用王鹤老师指导下提出首个基于视频的具身导航大模型NaVid。在相关领域学术期刊和会议上共发表论文60余篇,其中以一作或通讯发表论文29篇,ESI高被引论文3篇。曾在NeurIPS、AAAI、ICRA、IROS等会议上发表多篇Oral论文。
由无界智慧(Spatialtemporal AI),北京邮电大学、中科院自动化所、山东省计算中心及中山大学联合推出的 3D-MoRe 模型,是一款专注于 3D 场景理解与多模态推理的创新框架。该模型通过整合多模态嵌入、跨模态交互与语言模型解码器,能高效处理自然语言指令与 3D 场景数据,助力提升复杂三维环境中的推理能力与响应生成质量。依托 ScanNet 三维场景数据,结合 ScanQA 的问答标注与 ScanRefer 的物体描述,它生成了 62,000 组问答对和 73,000 条物体描述,覆盖 1513 个室内场景;同时,通过同义词替换等数据增强技术与语义过滤策略,确保了数据的多样性与高质量。在实际性能上,该模型在 ScanQA 的 CIDEr 评分提升 2.15%,在 ScanRefer 的 CIDEr@0.5 指标提升 1.84%,其代码已公开于https://3D-MoRe.github.io,为相关领域研究提供了实用的资源支持。
项目主页:https://3D-MoRe.github.io
引言:3D场景理解面临的核心瓶颈
在3D问答和密集字幕任务中,模型必须在3D环境中处理复杂的多模态推理。3D问答任务需要深度场景理解和空间推理来回答基于文本的问题,而密集字幕需要详细描述对象及其在3D空间中的关系。现有方法通常依赖于语义级数据增强、空间注意和跨模态编码等多模态融合技术来增强对象定位和场景理解。3D-MoRe 所设计的“生成-融合-推理”一体化范式,突破数据与模型的双重瓶颈。与专注于小型数据集的Gen3DQA不同,3D-MoRe方法利用多种数据增强策略来拓宽数据集多样性。与严重依赖空间特征的Vote2Cap-DETR++相比,我们的方法集成了空间和语言信息,以实现跨各种环境的稳健性能。高级语义过滤确保高质量数据,显着提高上下文准确率。
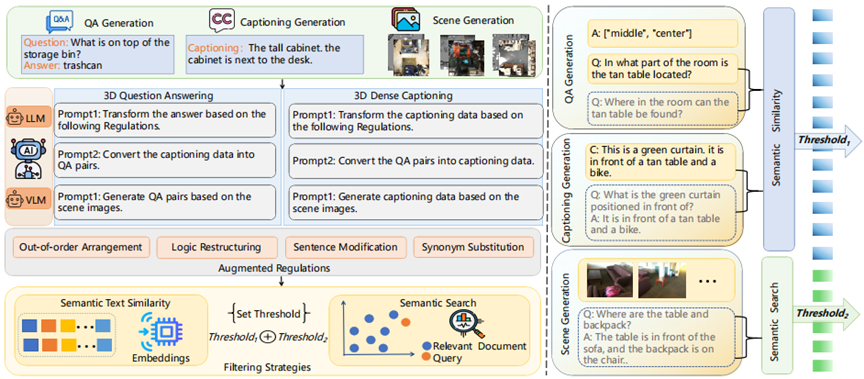
生成大规模数据集会出现挑战,包括提示构建、准确的注释提取功能和数据质量过滤。为了解决这些问题,我们提出了自适应多模态融合范式,它包含三种生成方法:问答对生成、字幕生成和场景生成。此外,我们引入了两种数据筛选技术:语义相似度和搜索。通过上述方法为3D问答任务生成62,000个三元组,为字幕任务生成73,000个三元组,如图1所示。我们微调训练一个3D大语言模型,该模型进行多模态编码,通过交互对齐模式,使用LLM解码响应,实现显着的性能改进,接近人类水平的熟练程度。
我们的主要贡献如下:
设计3D-MoRe框架:利用基础模型生成大规模3D语言数据集,集成多模态嵌入、跨模态交互和语言模型解码器,以增强复杂3D环境中的推理。
数据集构建:3D-MoRe从ScanNet数据集中合成了62,000个问答对和73,000个对象描述,显着增加了数据多样性并提高了3D问答和3D密集字幕任务的性能。
提出数据增强技术:通过先进的数据增强技术,包括同义置换、语句重排和语义过滤,3D-MoRe在ScanQA上实现了2.15%的CIDER提升,在ScanRefer上实现了1.84%的CIDEr@0.5提升,有效提升了模型回答理解准确率。
3D-MoRe模型的核心突破
自适应多模态数据融合范式
如图2所示,3D-MoRe框架通过度量引导的转换实现质量控制的数据增强。通过集成来自ScanNet、ScanQA和ScanRefer的多源输入 ,增强管道应用特定于任务的转换 ,然后是基于度量的过滤 ,产生最终数据集 。
语义质量控制
为了确保高质量的数据生成,我们依赖两个关键指标。首先,语义相似度衡量为其中 BERT 嵌入量化原始问题和生成问题之间的对齐。其次,我们通过语义搜索方法评估语义一致性,定义为该方法利用 RoBERTa 推断来评估字幕派生问答对的正确性。根据人工注释的统计数据确定的任务特定阈值为问答任务设置为 ,字幕设置为 。
增强架构
对于 QA 生成,应用同义词替换、逻辑反转和顺序重排等转换,相关评分计算为其中 表示 Sigmoid 函数。
密集字幕形式文本到问答对转换采用 T5 模型,其中生成的问题使用多个手工模板 生成,答案通过投射。
多模态集成
对于场景到 QA 的生成,我们采用CogVLM,其中问答对似然通过 3D 文本交叉关注计算为。最终数据集 集成了 62,000 多个问答对和 73,000 个标题注释,超过原始ScanQA和ScanRefer数据集。
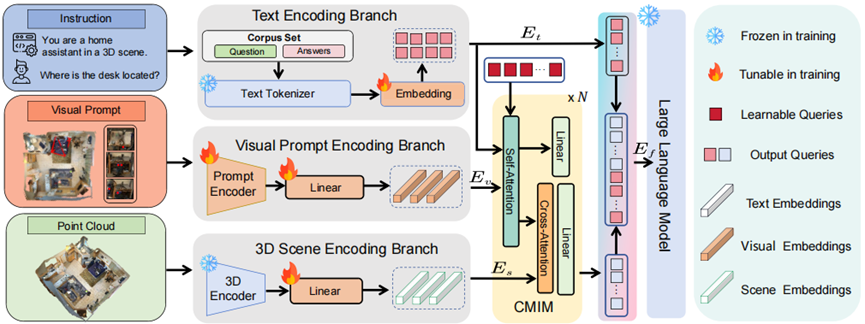
分层跨模态交互推理架构 (CMIM)
3D-MoRe 所提出的架构为具身推理建立了一个分层融合框架,包括三个核心组件:
多模态嵌入模块, 交叉注意力融合模块和 LLM 解码器。
如图 3 所示,处理管道通过张量连接集成文本 、视觉提示 和 3D 场景 。
多模态嵌入模块
文本编码:输入标记序列 的标准 Transformer 编码:其中 为位置编码。
视觉提示编码:空间制导信号 (3D 边界框 )通过以下方式获得:
(1)用户注释
(2)Mask3D 检测器输出
通过
3D 场景编码:
点云 由Vote2Cap-DETR++处理:
跨注意力融合模块
融合模块实现三阶段特征集成:
跨模态对齐:
上下文保持:
自我注意过程 通过 Transformer 层保持语言一致性,同时启用自适应融合控制。
残差融合:
通过残差连接保留引导细节。
LLM解码器
解码器通过动态前缀投影实现基于视觉的生成:
其中视觉空间上下文通过嵌入条件令牌概率的投影前缀流动:
实验结果:性能显著超越现有方法
与领先方法的比较
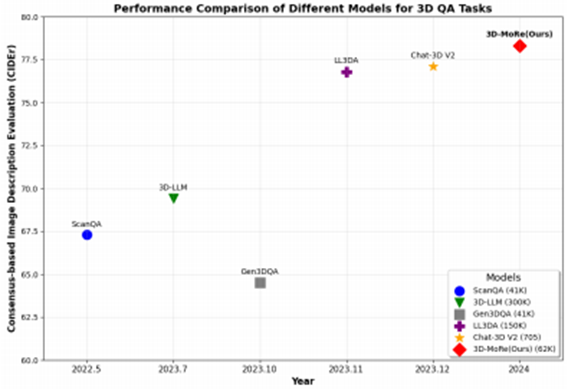
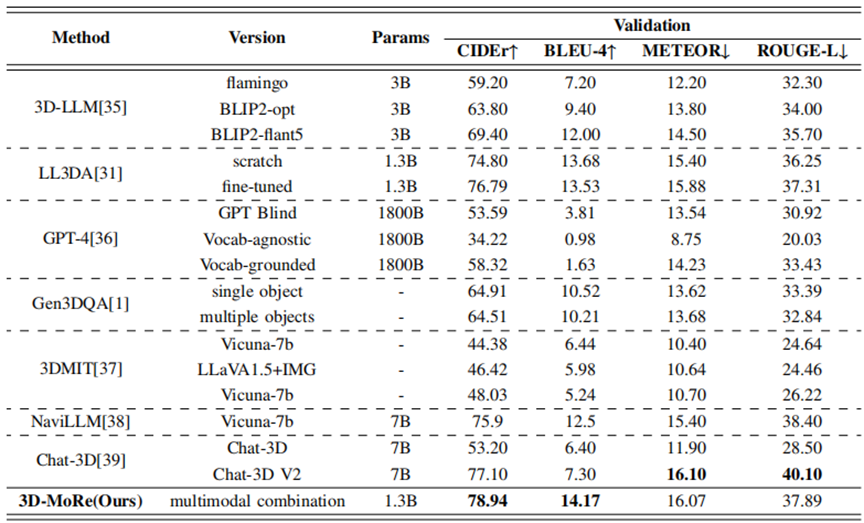
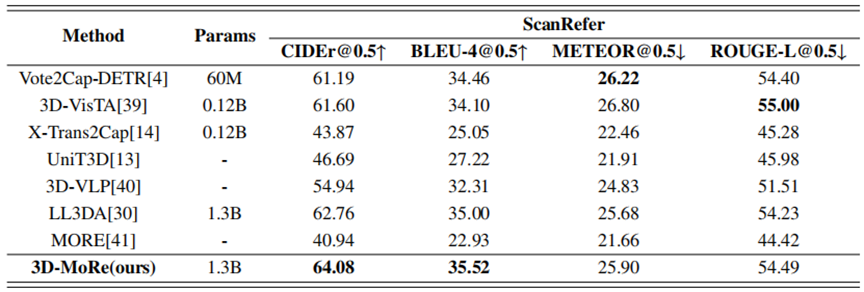
在权威基准 ScanQA 和 ScanRefer 上进行严格评测,使用 BLEU, ROUGE, METEOR, CIDEr 指标。表1和表2展示了我们的方法与现有方法的性能。在这里,“版本”指的是不同的模型架构或实验技术。我们的模型始终优于以前的方法,尤其是在验证集上,使用CIDER指标作为主要指标。值得注意的是,我们的方法超过了基于生成的Chat-3D V2模型,将CIDEr@0.5分数提高了1.84%。此外,在ScanRefer数据集的比较中,我们的模型优于其他先前的方法,显示在低参数LLM上CIDER性能提高了2.15%。
消融实验
在这项研究中,我们采用自适应多模态融合范式来扩展我们的3D问答和3D密集字幕任务数据集。为了确保不同数据生成方法之间的公平比较,我们通过句子转换器框架实现了三种类型:问答对生成、字幕生成和场景生成,对于其中的每一种,统一采样了3,000个实例。对于3D问答,生成额外的问答对并随后使用语义搜索进行过滤,以根据它们与原始对的对齐情况删除低质量数据,而对于3D密集字幕,采用语义相似度度量来选择高质量的字幕。
如表3所示,我们的组合数据增强和过滤方法在3D问答和密集字幕方面分别获得了最高的CIDER分数78.43%和63.21%,同时持续提高所有增强数据的性能。

应用前景与未来方向
赋能研究:生成的大规模高质量数据集 (62K问答对 + 73K 描述) 解决了 3D-语言领域的数据瓶颈,为模型训练与评测提供坚实基础。
即插即用:3D-MoRe提供完整训练、推理与数据生成流程,显著降低领域研究门槛。
通用框架:其统一模态交互推理架构 (CMIM) 可扩展至其他 3D 多模态任务(如视觉定位、具身导航)。
无界智慧(Spatialtemporal AI)介绍
无界智慧(Spatialtemporal AI)是一家专注于基于时空智能的跨场景具身Agent的AI公司,致力于打造具备自主感知、理解、决策与执行能力的服务机器人系统。我们当前面向“康养场景”构建具备真实任务执行能力的智能陪护机器人,部署于养老院、康养社区、家庭养老、示范样板间等场景。
无界智慧团队成员由来自CMU、MBZUAI、中山大学、南方科技大学以及中科院的研究人员组成。团队在机器人和人工智能领域具有深厚的学术造诣,已在T-PAMI、CVPR、ICCV、ICML、NeurIPS、ICLR、ICRA、RSS等国际顶级会议和期刊上发表数百篇高水平学术论文。
团队表示,目前正在持续迭代基于时空智能的通用具身大模型和通用具身Agent,推动具身智能和人形机器人领域的技术突破。

 扫码添加微信
扫码添加微信
- 点赞 0
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊





