


多模态大模型的主流架构vit+connector+llm介绍
- 2025-07-18 08:00:00
作者 | 冯泇铖 编辑 | 大模型之心Tech
原文链接:https://zhuanlan.zhihu.com/p/1893000772007985898
点击下方卡片,关注“大模型之心Tech”公众号
>>点击进入→大模型没那么大Tech技术交流群
本文只做学术分享,如有侵权,联系删文,自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
多模态系统是通过几个功能不同的算法模块协同运行的,分别负责不同层面的信息获取、统一化、融合、认知结果输出几个过程。多模态大模型的主流架构确实常采用 ViT(Vision Transformer) + Connector(适配器) + LLM(Large Language Model) 的组合模式,这种设计旨在将视觉模态与语言模态高效对齐,并利用预训练大模型的强大能力完成多模态理解和生成任务。
1、ViT(Vision Transformer)
负责提取图像特征,将输入图像编码为视觉表征,其核心思想—— 用注意力重新定义视觉信息的表达, 仅处理图像输入,不参与语言理解或生成。Vision Transformer(ViT)是Transformer架构从自然语言处理(NLP)领域向计算机视觉(CV)领域拓展的里程碑式创新。它摒弃了传统卷积神经网络(CNN)依赖局部卷积核的设计, 将图像视为“序列化的文本” ,通过全局注意力机制直接捕捉图像中远距离像素间的依赖关系。核心技术与实现方式:
输入图像被划分为多个 Patch(如 3x3的块),通过线性投影得到 Patch Embedding。 加入位置编码(Positional Encoding)后,输入到多层 Transformer Encoder 中,提取全局上下文特征。 输出为图像的特征序列(如 [CLS] token+ Patch Embeddings)。
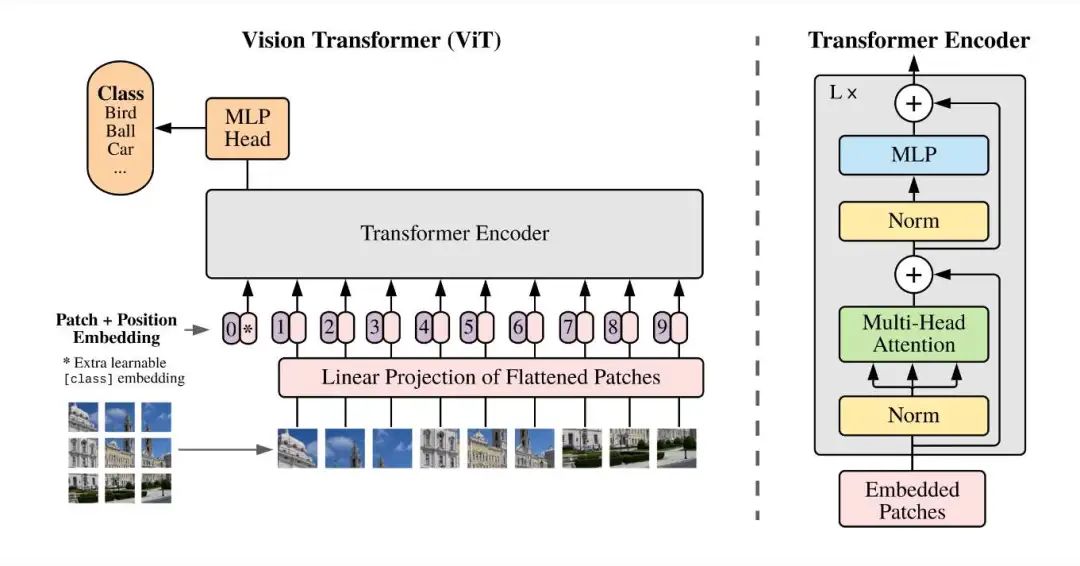
优势是:相比 CNN,ViT 能捕捉长距离依赖关系,适合处理复杂视觉场景。可复用 ImageNet 等大规模数据集上的预训练权重,提升泛化能力。ViT的诞生标志着CV领域从“局部卷积”到“全局注意力”的范式转变,后续衍生出DeiT(数据高效)、Swin Transformer(窗口化注意力)、BEiT(掩码预训练)等变体,推动视觉任务(分类、检测、分割)迈向更高效、灵活的模型架构。
代码介绍:
(1)图像分块与嵌入(Patch Embedding)
将图像分割为固定大小的块(如4x4),并通过卷积层将每个块映射到嵌入向量(embed_dim维)。包括:
卷积嵌入 :通过 nn.Conv2d将每个块映射到embed_dim维向量(4x4块 →768维)。展平操作 : rearrange(x, 'b e h w -> b (h w) e')将二维特征图展平为一维序列。
class PatchEmbedding(nn.Module):
def __init__(self, img_size=32, patch_size=4, in_channels=3, embed_dim=128):
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
self.n_patches = (img_size // patch_size) ** 2 # 总块数
# 使用卷积进行嵌入
self.proj = nn.Conv2d(
in_channels, embed_dim,
kernel_size=patch_size,
stride=patch_size
)
def forward(self, x):
# 输入形状:(B, C, H, W)
# 输出形状:(B, n_patches, embed_dim)
x = self.proj(x) # 卷积后形状:(B, embed_dim, H/patch_size, W/patch_size)
x = rearrange(x, 'b e h w -> b (h w) e') # 展平为序列
return x
(2) 位置编码(Position Embedding)
为每个块添加可学习的位置编码,确保模型感知空间位置。
class token :通过可学习参数 class_token补充到序列前端,用于分类。位置编码 :通过可学习参数 pos_embed为每个块添加位置信息,解决 Transformer 的空间感知问题。
class PositionalEncoding(nn.Module):
def __init__(self, embed_dim, n_patches):
super().__init__()
self.pos_embed = nn.Parameter(torch.zeros(1, n_patches + 1, embed_dim)) # 包含class token
def forward(self, x):
# x形状:(B, n_patches, embed_dim)
return x + self.pos_embed[:, 1:] # 剔除class token的位置编码
(3) Transformer 编码器层
通过多头自注意力(MHSA)捕获全局依赖,通过前馈网络(FFN)进行非线性变换。
多头注意力 :通过 nn.MultiheadAttention捕捉全局依赖关系。前馈网络 :使用两层全连接( mlp_dim通常为embed_dim的 4 倍)。
pclass TransformerEncoderLayer(nn.Module):
def __init__(self, embed_dim=128, num_heads=4, mlp_dim=256, dropout=0.1):
super().__init__()
self.norm1 = nn.LayerNorm(embed_dim)
self.attn = nn.MultiheadAttention(embed_dim, num_heads, dropout=dropout)
self.norm2 = nn.LayerNorm(embed_dim)
self.mlp = nn.Sequential(
nn.Linear(embed_dim, mlp_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(mlp_dim, embed_dim),
nn.Dropout(dropout)
)
def forward(self, x):
# 多头自注意力
residual = x
x = self.norm1(x)
x, _ = self.attn(x, x, x) # QKV同源
x = residual + x
# 前馈网络
residual = x
x = self.norm2(x)
x = self.mlp(x)
x = residual + x
return x
(4)训练与推理流程
a. 数据准备(CIFAR-10):
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
train_dataset = CIFAR10(root='./data', train=True, download=True, transform=transform)
test_dataset = CIFAR10(root='./data', train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
b. 模型实例化与训练
model = ViT(
img_size=32, patch_size=4, in_channels=3,
num_classes=10, embed_dim=128, depth=4,
num_heads=4, mlp_dim=256, dropout=0.1
).to('cuda')
optimizer = Adam(model.parameters(), lr=1e-3)
criterion = nn.CrossEntropyLoss()
for epoch in range(10):
model.train()
for images, labels in train_loader:
images, labels = images.to('cuda'), labels.to('cuda')
logits = model(images)
loss = criterion(logits, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
c. 推理示例
model.eval()
with torch.no_grad():
for images, labels in test_loader:
images = images.to('cuda')
logits = model(images)
preds = torch.argmax(logits, dim=1)
# 计算准确率等指标
2、Connector(适配器/连接器)
Connector(模态适配器) 将 ViT 输出的视觉特征映射到语言模型能理解的语义空间,是多模态模型中用于弥合视觉与语言模态间“鸿沟”的关键组件,其核心作用是将视觉特征(如CNN或ViT提取的图像向量)转换为与语言模型(如BERT、GPT)输入空间兼容的语义表示。通过全连接层、Transformer编码器或可学习的非线性映射,Connector对齐跨模态的语义和统计分布(如维度、分布均值方差),使视觉信息能与文本 token 直接交互(如在语言模型中作为额外输入或注意力键值)。例如,在视觉问答(VQA)任务中,Connector将图像特征编码为“语言可理解”的向量序列,与问题文本共同参与解码,从而解决因模态异构性导致的语义对齐难题,提升跨模态理解与生成任务的性能。
(1)线性投影层(Linear Projection Layer) (如 LLaVA)
通过简单 MLP 将图像特征映射到文本特征空间。将视觉特征(如CNN或ViT的输出)映射到与语言模型(如BERT、LLaMA)文本特征空间兼容的维度。通过全连接层(MLP)或深度可分离卷积。

(2)Q-Former (如 BLIP-2)
通过可学习的 Query 向量从视觉特征中提取与文本任务相关的高阶语义信息,即:通过一系列可学习的查询向量提取视觉特征中的关键信息。使用Transformer的Query-Value-Attention机制,其中Query是可学习参数,Value是视觉特征。输出是经过注意力加权的视觉特征,用于后续与文本交互。 Query中的可学习参数 通常指的是用于从视觉特征中提取与文本相关的关键信息的查询向量(Queries)。这些查询向量是在训练过程中通过反向传播算法自动学习得到的,它们的作用是帮助模型聚焦于图像中最相关的部分,以便更好地完成下游任务,这些查询向量被初始化为随机值,并且在整个模型训练过程中不断调整。

(3)交叉注意力机制 (如 Flamingo)
最后, 交叉注意力机制 被用来动态地融合来自视觉和文本模态的信息。在此步骤中,文本特征作为查询(Query),而视觉特征则作为键(Key)和值(Value)。这种方法允许模型根据文本上下文动态地关注图像的不同部分,从而实现视觉和语言信息的深度融合。使用交叉注意力层(Cross-Attention)动态融合视觉与文本特征。
具体代码及流程介绍,实现一个简单的 视觉-语言对齐Connector ,包含上述三个组件:
a. 线性投影层(Linear Projection)
import torch
import torch.nn as nn
class LinearProjection(nn.Module):
def __init__(self, input_dim, output_dim):
super(LinearProjection, self).__init__()
self.linear = nn.Linear(input_dim, output_dim)
self.ln = nn.LayerNorm(output_dim) # 可选:层归一化
def forward(self, x):
return self.ln(self.linear(x))
b. Q-Former(可学习Query提取器)
class QFormer(nn.Module):
def __init__(self, visual_dim, q_dim, num_queries=10):
super(QFormer, self).__init__()
self.queries = nn.Parameter(torch.randn(num_queries, q_dim)) # 可学习的查询向量
self.attention = nn.MultiheadAttention(
embed_dim=q_dim,
num_heads=4,
batch_first=True
)
self.linear = nn.Linear(visual_dim, q_dim) # 将视觉特征映射到Query空间
def forward(self, visual_features):
# 将视觉特征映射到Query空间
visual_proj = self.linear(visual_features)
# 计算注意力权重,提取关键视觉信息
q = self.queries.unsqueeze(0).repeat(visual_features.size(0), 1, 1) # 扩展到batch维度
attn_output, _ = self.attention(
query=q,
key=visual_proj,
value=visual_proj
)
return attn_output
c. 交叉注意力机制(Cross-Attention)
class VisualLanguageConnector(nn.Module):
def __init__(self, visual_dim=768, text_dim=768, q_dim=256, num_queries=10):
super(VisualLanguageConnector, self).__init__()
# 1. 线性投影层:将原始视觉特征映射到中间空间
self.linear_proj = LinearProjection(input_dim=visual_dim, output_dim=q_dim)
# 2. Q-Former:提取关键视觉信息
self.qformer = QFormer(visual_dim=q_dim, q_dim=q_dim, num_queries=num_queries)
# 3. 交叉注意力:融合文本与视觉信息
self.cross_attn = CrossAttentionLayer(text_dim=text_dim, visual_dim=q_dim)
def forward(self, visual_features, text_hidden):
# 步骤1:线性投影
projected_visual = self.linear_proj(visual_features)
# 步骤2:Q-Former提取关键特征
qformer_output = self.qformer(projected_visual)
# 步骤3:与文本特征进行交叉注意力融合
fused_features = self.cross_attn(text_hidden, qformer_output)
return fused_features
3、 LLM(大语言模型)
上面输出的数据最后要给到LLM,然后输出认知结果。多模态大模型中, LLM(大语言模型) 的核心任务是将对齐后的多模态特征(如视觉特征)与文本输入结合,通过自回归生成(Autoregressive Generation)输出目标文本(如答案、描述)。以下是其具体工作流程的分步详解:
(1) 输入准备阶段
对齐后的多模态特征:ViT + Connector 输出的视觉特征(如 [batch_size, num_patches, hidden_dim])。视觉特征需映射到与 LLM 的文本嵌入空间维度一致(例如 LLaMA 的 4096 维)。
文本输入处理问题/指令:用户输入的文本(如 "What is in the image?")通过分词器转换为 Token ID 序列。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
input_text = "What is in the image?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids # [batch=1, seq_len]
(2) 特征融合与输入构造
视觉特征与文本嵌入拼接:将视觉特征作为上下文前缀(Prefix)拼接到文本 Token 前。
视觉特征投影:通过 Connector(如 MLP)将视觉特征映射到 LLM 的嵌入空间。 文本嵌入获取:将文本 Token ID 转换为嵌入向量。 拼接:形成 [视觉特征][文本问题] 的联合输入。
# 已通过 Connector 处理视觉特征
visual_embeddings = connector(visual_features) # [batch=1, num_patches=256, hidden_dim=4096]
# 获取文本嵌入
text_embeddings = llm.get_input_embeddings()(input_ids) # [1, text_seq_len, 4096]
# 拼接视觉与文本嵌入
inputs_embeds = torch.cat([visual_embeddings, text_embeddings], dim=1) # [1, 256+text_seq_len, 4096]
位置编码与注意力掩码:
位置编码:LLM 自动为拼接后的输入添加位置编码,无需手动处理。
注意力掩码:需构造掩码矩阵,标记有效输入位置(通常全为 1)。
(3) 自回归生成阶段
a. 生成启动:直接传入 inputs_embeds(而非 input_ids),跳过 Token 到嵌入的转换。设置生成长度、解码策略(如束搜索)、温度(Temperature)等参数。
b. 生成循环(以束搜索为例)
初始化:将 inputs_embeds 输入 LLM,获取首个预测 Token 的概率分布。 候选序列扩展:保留 Top-K(束宽)个候选序列及其概率得分。 迭代生成:对每个候选序列,追加新 Token 并输入 LLM,更新概率得分。保留全局 Top-K 候选,直到生成终止符(如 )或达到最大长度。
c. 终止条件
最大长度限制:例如 max_length=100。 终止符检测:当生成 Token 时停止。
from transformers import GenerationConfig
# 配置生成参数
generation_config = GenerationConfig(
max_length=100,
num_beams=5, # 束搜索束宽
early_stopping=True, # 遇到 EOS 提前停止
temperature=0.7, # 控制随机性(低温度更确定)
)
# 启动生成
outputs = llm.generate(
inputs_embeds=inputs_embeds,
generation_config=generation_config,
)
# 解码生成的 Token
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"Generated Answer: {generated_text}")

4、信息与数据流转
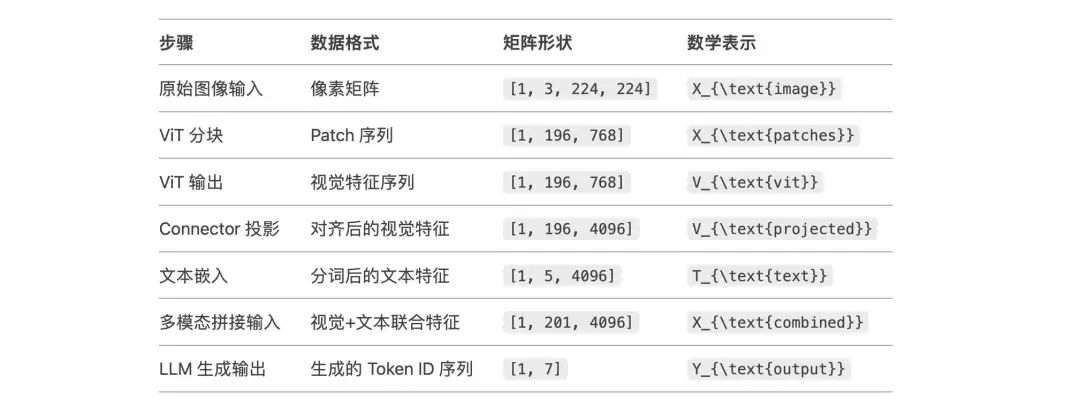
以下是一个从图像输入到文本输出的数据格式变化全流程的数学示例,展示每个环节的矩阵维度变化和运算过程。我们以224x224 RGB图像输入为例,逐步说明各模块的处理。矩阵表达如下:

(1)图像输入
原始输入:一张 RGB 图像,形状为 [3, 224, 224](通道数 × 高度 × 宽度)。
批量输入:假设批量大小为 1,即 batch_size = 1,输入张量形状为 [1, 3, 224, 224] 。
(2) ViT(Vision Transformer)处理
a. 图像分块(Patchify)
分块尺寸:将图像划分为 16x16 的块,每个块的像素数为 16×16×3=768。
块数量:(224/16) × (224/16) = 14×14 = 196 个块。
图像被划分为 14×14 的网格,每个网格对应一个块。输入张量变形为 [1, 196, 768] ,表示 1 个样本、196 个块、每个块 768 维。
b. 线性投影(Patch Embedding)
投影矩阵:通过可学习矩阵 W_p ∈ R^{768×D},将每个块映射到隐藏维度 D=768(ViT-Base 为例)。
输出:形状保持 [1, 196, 768] 。
c. 位置编码(Positional Encoding)
位置向量:为每个块添加位置编码 P ∈ R^{196×768},与 Patch Embedding 相加。
输出:形状仍为 [1, 196, 768] 。
d. Transformer Encoder
自注意力计算:经过多层 Transformer Encoder,输出特征矩阵形状不变,仍为 [1, 196, 768] 。
CLS Token(可选):若使用 [CLS] Token 作为全局特征,输出形状为 [1, 1, 768]。
此处假设不使用 [CLS],保留全部 Patch 特征。在Transformer模型中, CLS Token (Classification Token)是一个特殊的人工添加的标记(Token),主要用于 聚合整个输入序列的全局信息 ,尤其在分类任务(如文本分类、图像分类)中起到关键作用。CLS Token 是一个额外的可学习向量,通常被插入到输入序列的最前面(位置0),作为整个序列的“代表”。通过自注意力机制,CLS Token 会与输入序列中的所有其他元素交互,最终其隐藏状态(Hidden State)可表示整个序列的全局特征。假设输入序列为[Token1, Token2, ..., TokenN],插入 CLS Token 后变为:
输入序列=[CLS,Token1,Token2,...,TokenN]
(3)Connector(适配器)处理
将 ViT 输出的视觉特征[1, 196, 768]映射到 LLM 的嵌入空间(假设 LLM 隐藏维度为4096)。
a. 线性投影(MLP):
投影矩阵:W_c ∈ R^{768×4096},将每个 Patch 特征从 768 维映射到 4096 维,Transformer Encoder([1, 196, 768])之后的输出形状变为 [1, 196, 4096], 即:1个batch,196块,每块对应4096个数据.
b. 特征压缩(可选)
池化操作 :若需减少序列长度,可对196个 Patch 特征取均值池化:

此处假设保留全部 Patch,输出仍为 [1, 196, 4096] 。
直接对 所有块的全局特征取均值 (如mean pooling),理论上会混合不同目标的特征,但在实际任务中,ViT 仍然可以区分多目标。经过自注意力机制处理后,不同目标的块特征在向量空间中可能已被 分离到不同方向 。池化后的全局特征可能是这些子空间的 混合投影 ,但分类器(如全连接层)可以学习解耦这些信息。在公开数据集(如 COCO)上,ViT 在多目标分类任务中表现良好,证明其池化策略对多目标场景具有一定鲁棒性。
(4)LLM(大语言模型)输入构造
a. 文本输入处理
问题文本:"What is in the image?"
分词与嵌入:分词后 Token 序列长度假设为 5(如 ["What", "is", "in", "the", "image?"])。通过 LLM 的嵌入层,将每个 Token 映射为 4096 维向量:
b. 多模态特征拼接
拼接视觉与文本特征 :将视觉特征 [1, 196, 4096] 与文本嵌入[1, 5, 4096]沿序列维度拼接:
X combined = [ V_ visual, T_ text] ⇒ 形状为 [1,201,4096]
(5) LLM 自回归生成
[1,201,4096]的信息输入 LLM,LLM 内部自动添加位置编码,生成最终的输入表示。假设生成答案"A cat sitting on a sofa.",分词后长度为7,生成过程如下:
a. 生成:
LLM 输出预测 Token 的概率分布 P_1 ∈ R^{V}(V 为词表大小)。 选择概率最高的 Token(如 "A"),追加到输入序列,新序列长度为 202。
b. 迭代生成 :重复预测并追加 Token,直到生成终止符或达到最大长度。
c. 最终输出: 生成序列 [A, cat, sitting, on, a, sofa, .],形状为 [1, 7] 。
全流程是:原始图像 → 分块 → ViT 编码 → 位置编码 + 自注意力 → 特征矩阵 → 均值池化 → 全局向量
5、综合案例: 实际模型示例(LLaVA)
核心步骤设计:
1、输入阶段:
图像输入 ViT,被编码为视觉特征序列(如 [CLS] + Patch Embeddings)。文本输入(如问题)通过 LLM 的 Tokenizer 转换为 Token 序列。
2、模态对齐:
Connector 将视觉特征转换为与文本 Token 同维度的向量(例如映射到 LLM 的嵌入空间)。模态对齐包括通过标签化实现不同模态的人工标记,这一点有一定向汽车行业的CAN总线格式。
构建统一的输入序列 (The 1D Sequence):
投影后的图像 Token 和文本 Token 被 拼接 成一个单一的、一维的长序列。 关键点:为了告诉模型哪些 Token 来自图像,哪些来自文本,会添加特殊的“模态标记” (Modality Tokens)。 一个非常常见的模式是:
在 所有图像 Token 之前 添加一个特殊的 [IMG] Token(或类似 <image>)。在 图像 Token 序列之后、文本 Token 序列之前 添加一个特殊的 [SEP] Token(或类似 </image>)来分隔模态。文本 Token 序列本身可能以 [BOS] (Beginning of Sequence) 开始,以 [EOS] (End of Sequence) 结束,或者包含其他任务特定的标记。
最终输入序列示例:[BOS][IMG]proj_img_token_1proj_img_token_2 ... proj_img_token_N[SEP]txt_token_1txt_token_2 ... txt_token_M[EOS]
位置编码: 这个统一序列会被赋予标准的 位置编码 。位置编码是连续的,覆盖整个序列(图像 Token + 分隔符 + 文本 Token)。这告诉模型每个 Token 在序列中的绝对位置和相对顺序。
示例:LLaVA 中,ViT 的 [CLS] token 经 MLP 投影后,与文本 Token 拼接为 [视觉特征][文本问题]。
3、联合推理:
对齐后的多模态特征作为 LLM 的输入前缀(Prefix),语言模型基于此生成答案。
示例:在 VQA 任务中,LLM 将视觉特征视为“看到的内容”,结合问题生成答案。
4、输出阶段:
LLM 自回归生成文本结果(如答案、描述),完成多模态任务。
代码:
1、视觉编码
# 使用 CLIP 提取图像特征
image_encoder = CLIPVisionModel.from_pretrained("openai/clip-vit-large-patch14")
visual_features = image_encoder(pixel_values).last_hidden_state # [1, 256, 1024]
2、 Connector 投影
# 将视觉特征映射到 LLaMA 的嵌入空间
connector = nn.Linear(1024, 4096) # 输出维度匹配 LLaMA
visual_embeddings = connector(visual_features) # [1, 256, 4096]
3、 文本拼接与生成 :
# 拼接视觉特征与问题文本
input_ids = tokenizer("What is in the image?", return_tensors="pt").input_ids
text_embeddings = llama_model.get_input_embeddings()(input_ids) # [1, text_len, 4096]
inputs_embeds = torch.cat([visual_embeddings, text_embeddings], dim=1) # [1, 256+text_len, 4096]
# 生成答案
outputs = llama_model.generate(inputs_embeds=inputs_embeds, max_length=100)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
建议的架构图:

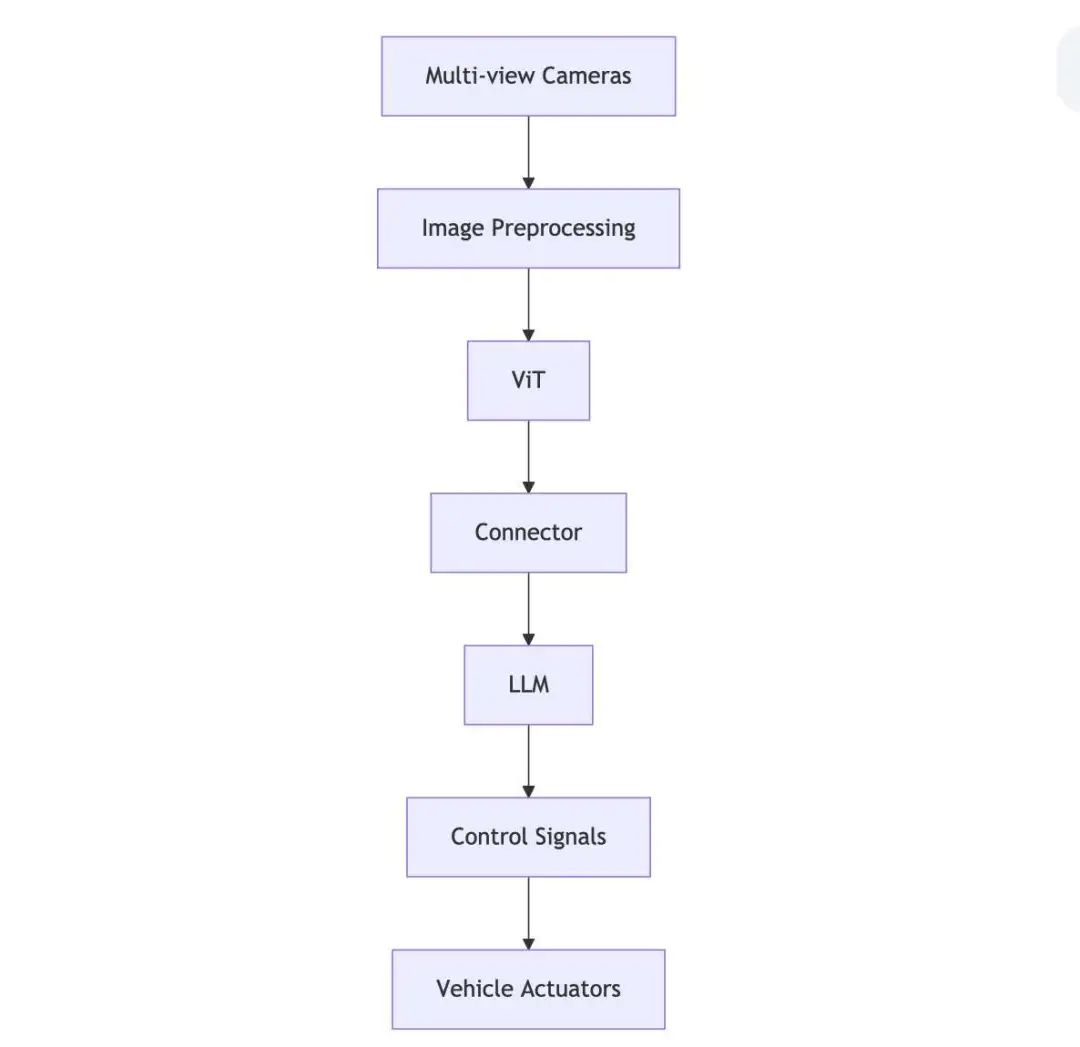
输入层 :
多视角摄像头阵列实时采集道路环境数据 图像预处理模块进行归一化/去噪/畸变校正
ViT核心处理 :
将图像分割为16x16的patch序列 通过线性投影生成patch embedding 加入可学习的位置编码 经过12层Transformer Encoder提取全局特征
Connector适配器 :
特征投影层对齐ViT与LLM的维度 残差连接保留原始视觉特征 时序上下文聚合模块处理连续帧信息
LLM决策系统 :
多模态输入嵌入层处理视觉特征向量 基于GPT-4架构的24层Transformer Decoder 驾驶策略头输出可解释的决策指令
控制信号生成 :
结合高精度地图和定位信息 分层输出转向/加速/制动指令 安全监控模块实现fail-safe机制
信息如何对应?自注意力是关键!
自注意力的魔力: Transformer 的自注意力机制允许序列中的 任何 Token 关注序列中的任何其他 Token (包括它之前的 Token)。这是建立跨模态联系的核心。
建立关联: 当 LLM 处理一个 文本 Token (例如,描述中的“猫”)时,它的自注意力层可以去“看”序列中 所有的图像 Token (proj_img_token_1 ... proj_img_token_N)。它学习到某些图像 Token(比如代表猫头、猫身的那些)的激活模式与“猫”这个词的激活模式高度相关。同样,当 LLM 需要基于图像内容 生成一个词 (比如回答“图片里有什么动物?”)时,它生成的下一个文本 Token 的自注意力会强烈地关注那些与“动物”概念相关的图像 Token。

学习对齐: 这种“对应”关系 不是预先硬编码的 。它是模型在 海量图文对数据 上进行预训练时 学习到的 。训练目标通常是 基于图像和文本联合输入,预测下一个文本 Token (自回归语言建模),或者对比学习(让匹配的图文对特征靠近,不匹配的远离)。通过反复看到“猫”这个词和猫的各种图片同时出现,模型内部的权重(特别是自注意力权重和投影层权重)逐渐调整,使得代表“猫”的文本 Token 和代表猫的视觉特征的投影图像 Token 在模型的表示空间中产生强烈的关联。
分隔符的作用:[IMG] 和 [SEP] 等分隔符为模型提供了重要的 模态边界信号 。模型学习到 [IMG]和 [SEP] 之间的 Token 代表图像信息,之后的 Token 代表文本信息。这有助于模型快速定位信息来源。
举个具体例子:
用户输入: “Describe the cat in the image.” + 一张猫趴在沙发上的图片。
处理流程:
图像: ViT 将猫沙发图分割成 256 个块 (16x16),输出 256 个图像特征向量。 文本: Tokenizer 将文本转换为: ["Describe", "the", "cat", "in", "the", "image", "."](假设 M=7)。Connector: 将 256 个图像特征投影到与文本 Embedding 相同维度。 构建序列 (假设标记):
[BOS]- 开始标记[IMG]- 图像开始标记proj_img_1...proj_img_256- 投影后的 256 个图像 Token[SEP]- 图像结束/文本开始标记"Describe","the","cat","in","the","image","."- 文本 Token[EOS]- 结束标记 (可选,或用于后续生成)LLM 处理与生成: LLM 接收这个长序列 (1 + 1 + 256 + 1 + 7 [+1] = 267 Token)。 当 LLM 处理到文本部分的 "cat"这个 Token 时,它的自注意力机制会计算"cat"与序列中所有其他 Token 的相关性。它 学会 了"cat"与[IMG]后面某些特定的图像 Token(比如代表黄色毛发的、尖耳朵的、胡须的投影 Token)有很高的相关性。当 LLM 开始生成回答时(例如,生成 "The"),它的自注意力会关注整个输入序列(包括所有图像 Token)。为了生成"cat"这个词,模型强烈关注那些代表猫的图像 Token。为了生成"sofa",模型会关注代表沙发纹理和形状的图像 Token。同时,它也会关注文本输入中的"cat"和"image"等词,理解任务要求。最终输出可能像: "The","cat","is","lying","on","a","red","sofa","."。其中生成"red"依赖于模型关注到代表沙发颜色的图像 Token。
所以:
物理形式: 图像和文本信息在输入 LLM 时,确实是通过 Connector 投影后,与模态分隔符一起拼接成一个一维 Token 序列的。 对应机制: 图像和文本信息的“对应”关系,是通过:
添加 模态分隔符 ( [IMG],[SEP]) 标明来源。投影层 将视觉特征映射到语言空间。 位置编码 提供序列顺序。 Transformer 的自注意力机制 动态地、基于上下文计算序列中任意 Token 之间的相关性。 在海量图文对上预训练 ,让模型内部的参数(自注意力权重、投影层权重)学习到视觉概念(由投影图像 Token 表示)和语言概念(由文本 Token 表示)之间的统计关联。
这种架构的精妙之处在于,它利用强大的 LLM 作为统一的理解和生成引擎,通过 Connector 和自注意力机制,让 LLM 能够“看到”并“理解”视觉信息,从而实现多模态对话、描述、问答等任务。对齐是模型自己从数据中学出来的,而不是靠外部强制的结构。

大模型之心Tech知识星球交流社区
我们创建了一个全新的学习社区 —— “大模型之心Tech”知识星球,希望能够帮你把复杂的东西拆开,揉碎,整合,帮你快速打通从0到1的技术路径。
星球内容包含:每日大模型相关论文/技术报告更新、分类汇总(开源repo、大模型预训练、后训练、知识蒸馏、量化、推理模型、MoE、强化学习、RAG、提示工程等多个版块)、科研/办公助手、AI创作工具/产品测评、升学&求职&岗位推荐,等等。
星球成员平均每天花费不到0.3元,加入后3天内不满意可随时退款,欢迎扫码加入一起学习一起卷!

 扫码添加微信
扫码添加微信
- 点赞 0
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊





