多模态大模型细分方向太多不知道从哪入手?这份 ICCV 2025 接收的相关工作汇总也许能帮到你~
- 2025-07-17 09:30:00
点击下方卡片,关注“大模型之心Tech”公众号
>>点击进入→大模型技术交流群
写在前面
自多模态大模型崭露头角以来,凭借其融合文本、图像、音频、视频等多种信息模态的强大能力,已迅速成为人工智能领域的焦点,不仅在学术研究中不断突破认知边界,更在工业应用中催生了如智能交互、内容创作、自动驾驶等一系列变革性的发展,深刻改变着我们与技术交互的方式。
2025 年已然过半,在前不久放榜的 ICCV 2025 中,多模态大模型相关工作成果丰硕,诸多全球顶尖高校团队与工业界研究团队纷纷展示其前沿探索,进一步印证了该领域的旺盛生命力与巨大潜力。
然而,在这股蓬勃发展的浪潮背后,多模态大模型的细分领域繁多且交叉性强,对于刚刚踏入这个领域的初学者而言,往往会陷入 “不知从何入手” 的困境。视觉语言模型、多模态大语言模型、多模态推理模型,每一个细分领域都有着独特的技术难点和研究价值。初学者常常会困惑:这些方向各自的核心挑战是什么?当前的技术瓶颈在哪里?未来的发展趋势又指向何方?究竟哪一个细分方向更适合自己深入挖掘,既能结合自身优势,又能顺应行业需求?
为了帮助大家厘清这些思路,破除信息壁垒,我们从知识星球里的 ICCV 2025多模态大模型 论文汇总中,精心挑选了 一部分领域内热门或值得探索的子方向的相关论文,为大家做简要介绍,让大家一窥当下多模态大模型的研究风向,为初入门的朋友们找准方向提供一些参考。
更多关于多模态大模型的讨论、技术分享和求职交流,欢迎加入『大模型之心 Tech 知识星球』。


多模态统一表征预训练
标题:EgoM2P: Egocentric Multimodal Multitask Pretraining
链接:https://www.arxiv.org/pdf/2506.07886
主页:https://egom2p.github.io/
单位:苏黎世联邦理工学院、浙江大学、微软
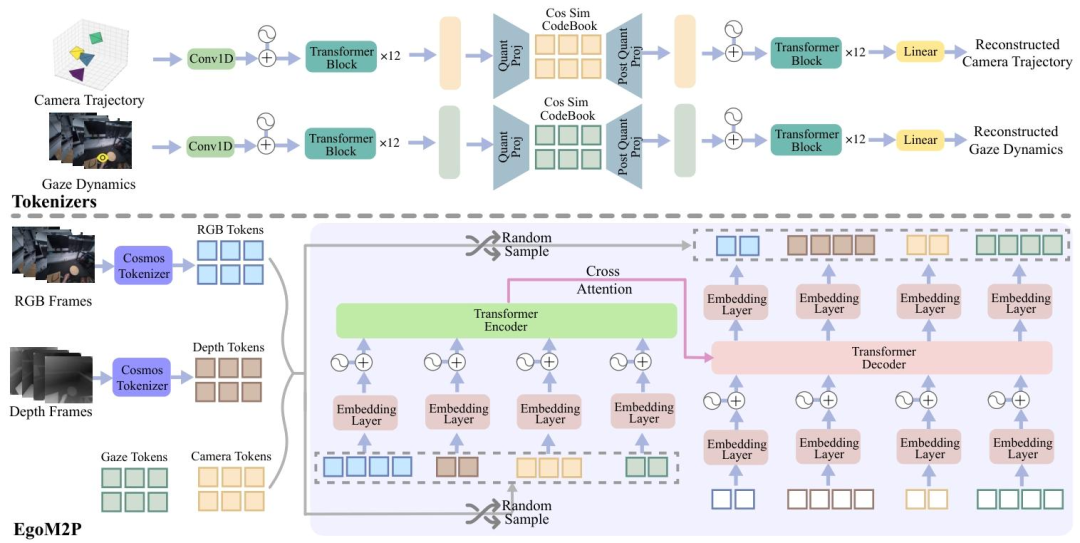
摘要:理解第一人称视觉中的多模态信号(如RGB视频、深度、相机位姿和注视点)对于增强现实、机器人技术和人机交互等应用至关重要,这些信号使系统能够更好地解读佩戴相机者的行为、意图和周围环境。然而,构建大规模的第一人称多模态多任务模型面临着独特的挑战。第一人称数据本质上具有异质性,不同设备和场景下的模态覆盖范围存在很大差异。为缺失的模态(如注视点或头戴式相机轨迹)生成伪标签通常是不可行的,这使得标准的监督学习方法难以扩展。此外,动态的相机运动和第一人称视频复杂的时空结构,为现有多模态基础模型的直接应用带来了额外的挑战。为应对这些挑战,我们引入了一组高效的时间tokenizer,并提出了EgoM2P——一种掩码建模框架。该框架从具有时间感知能力的多模态token中学习,以训练一个用于第一人称4D理解的大规模通用模型。这种统一设计支持跨多种第一人称感知与合成任务的多任务处理,包括注视点预测、第一人称相机跟踪、从第一人称视频中进行单目深度估计,同时还可作为条件第一人称视频合成的生成模型。在这些任务中,EgoM2P的表现与专业模型相当甚至更优,而速度快了一个数量级。我们将全面开源EgoM2P,以支持社区并推动第一人称视觉研究的发展。
一句话总结:提出了首个面向自我中心视觉的多模态多任务预训练模型 EgoM2P,旨在解决第一人称视角下多模态信号理解的挑战。

主要贡献如下:
设计统一时间tokenizer:构建基于 Transformer 的 VQ-VAE 架构,将 RGB / 深度视频、注视动态和相机轨迹等多模态数据压缩为含时间信息的离散标记,实现跨模态时空特征表示。 扩展多模态掩码预训练:将图像领域的掩码建模扩展至视频领域,通过可变掩码率处理缺失模态和数据不平衡问题,支持并行推理以提升效率。 构建大规模多模态数据库:整合 8 个真实与合成数据集,形成 40 亿训练标记的数据库,覆盖 RGB、深度、注视点和相机轨迹四大模态,支持多任务学习。 实现高效多任务与生成能力:支持任意模态间的预测(如相机跟踪、深度估计)和条件视频合成,性能超越或匹配专业模型,推理速度提升 10-2000 倍。
视觉提示开放词汇目标检测
标题:Visual Textualization for Image Prompted Object Detection
链接:https://arxiv.org/pdf/2506.23785
主页:https://github.com/WitGotFlg/VisTex-OVLM
单位:北航、字节
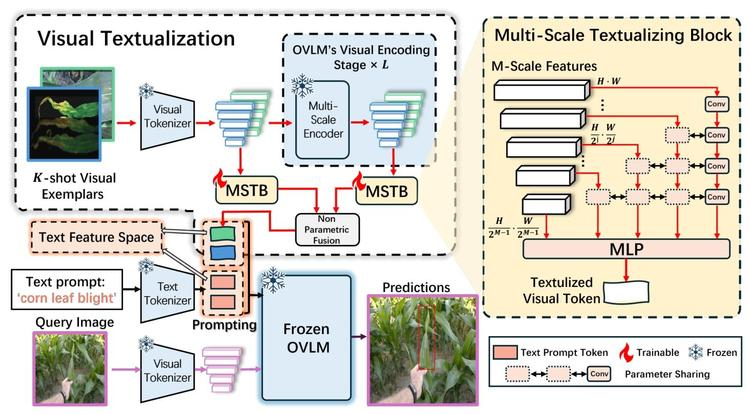
摘要:我们提出了VisTex-OVLM,这是一种新颖的图像提示目标检测方法。该方法引入了视觉文本化技术——即将少量视觉样例投影到文本特征空间,以增强对象级视觉-语言模型(OVLMs)检测罕见类别的能力。这些罕见类别难以用文本描述,且在预训练数据中几乎不存在,同时该技术还能保留模型预训练的对象-文本对齐能力。具体而言,VisTex-OVLM利用多尺度文本化模块和多阶段融合策略来整合视觉样例的视觉信息,生成文本化的视觉token,这些标记可与文本提示一起有效引导OVLMs。与以往方法不同,我们的方法保留了OVLM的原始架构,在增强少样本场景下性能的同时,维持了其泛化能力。VisTex-OVLM在与OVLM预训练数据重叠极少的开放集数据集上表现出优异性能,并在少样本基准数据集PASCAL VOC和MSCOCO上取得了最先进的结果。
一句话总结:提出了 VisTex-OVLM 方法,通过视觉文本化将视觉样本投影到文本特征空间,以增强对象级视觉语言模型(OVLMs)检测罕见类别的能力,同时保留预训练的对象 - 文本对齐。
主要贡献如下:
视觉文本化技术:首次提出将视觉样例投影到文本特征空间的 “视觉文本化” 方法,使 OVLMs 能直接利用图像提示检测预训练未覆盖的罕见类别,同时保留模型原有的对象 - 文本对齐能力。
多尺度文本化块(MSTB):设计参数共享的多尺度文本化模块,提取视觉样例的多尺度特征并映射至文本空间,兼顾细粒度细节与全局语义,避免引入复杂结构破坏 OVLM 预训练架构。
非参数化多阶段融合(MSF):采用非参数化策略融合视觉编码器各阶段的文本化特征,借助 OVLM 预训练的多阶段对象 - 文本对齐机制,生成语义丰富的视觉标记,无需额外参数即可增强检测引导能力。
无损提示集成:无需修改 OVLM 原始架构或微调预训练权重,通过文本化视觉标记与文本提示的直接串联,在少样本场景下提升检测性能的同时,完全维持模型的泛化能力。
开放集与少样本场景的双重突破:在 LVIS、16 个未见数据集等开放集场景中超越现有方法,且在 PASCAL VOC、MSCOCO 等少样本基准上取得 SOTA 结果,验证了视觉 - 文本互补策略对零样本检测局限性的有效性。
LoRA微调
标题:Generalized Tensor-based Parameter-Efficient Fine-Tuning via Lie Group Transformations
链接:https://arxiv.org/pdf/2407.05417
主页:https://github.com/Chongjie-Si/Subspace-Tuning
单位:上交、哈佛、东南
摘要:将预训练基础模型适配到各种下游任务是人工智能领域的核心实践。然而,任务的广泛性和高昂的计算成本使得全量微调变得不切实际。为了克服这一问题,诸如LoRA等参数高效微调(PEFT)方法应运而生,并成为日益增长的研究焦点。尽管这些方法取得了成功,但它们主要是为线性层设计的,侧重于二维矩阵,而在很大程度上忽略了卷积核等高维参数空间。此外,将这些方法直接应用于高维参数空间通常会破坏其结构关系。鉴于基于矩阵的PEFT方法的快速发展,我们提出了一种泛化方法,无需设计专门策略,即可将基于矩阵的PEFT方法扩展到高维参数空间,同时不损害其结构特性,而非设计专门的策略。具体而言,我们将参数视为李群的元素,将更新建模为相应李代数中的扰动。这些扰动通过指数映射映射回李群,确保了平滑、一致的更新,从而保留了参数空间的固有结构。在计算机视觉和自然语言处理上的大量实验验证了我们方法的有效性和通用性,表明其相比现有方法有明显改进。
一句话总结:提出了一种基于李群变换的广义张量参数高效微调方法(LieRA),旨在将基于矩阵的参数高效微调(PEFT)方法扩展到高维参数空间,同时保留其结构特性。

主要贡献如下:
提出基于李群变换的高维参数扩展框架:将高维参数视为李群元素,通过李代数扰动和指数映射实现结构保留的更新,解决传统方法破坏高维参数空间结构的问题。 设计乘法更新机制保持空间局部性:采用李群乘法更新规则(\mathcal{W} \to \mathcal{W} \odot \exp(\Delta\mathcal{W})),通过泰勒近似简化计算,确保卷积核等参数的空间相关性不被破坏。 理论证明全秩容量提升表示能力:LieRA 在线性层中具有全秩容量(R(W \odot AB) = \min(n, m)),相比 LoRA 的固定秩r,能更灵活捕捉任务特征。 通用化扩展兼容现有 PEFT 方法:无需为不同高维结构定制策略,可直接与 LoRA 等矩阵 - based 方法结合,通过李群框架统一处理线性层和卷积层等参数。
多模态推理模型
标题:Visual-RFT: Visual Reinforcement Fine-Tuning
链接:https://arxiv.org/pdf/2503.01785
单位:上交、上海AI Lab、港中文
主页:https://github.com/Liuziyu77/Visual-RFT
摘要:大型推理模型(如OpenAI o1)中的强化微调(RFT)通过从答案反馈中学习,这在微调数据稀缺的应用中特别有用。最近的开源工作(如DeepSeek R1)表明,使用可验证奖励的强化学习是复现o1的关键方向之一。尽管R1风格的模型已在语言模型中证明了成功,但其在多模态领域的应用仍有待探索。这项工作引入了视觉强化微调(Visual-RFT),进一步将RFT的应用领域扩展到视觉任务。具体而言,Visual-RFT首先使用大型视觉语言模型(LVLMs)为每个输入生成包含推理标记和最终答案的多个响应,然后使用我们提出的视觉感知可验证奖励函数,通过群体相对策略优化(GRPO)等策略优化算法更新模型。我们为不同的感知任务设计了不同的可验证奖励函数,例如用于目标检测的交并比(IoU)奖励。在细粒度图像分类、少样本目标检测、推理接地以及开放词汇目标检测基准上的实验结果表明,与监督微调(SFT)相比,Visual-RFT具有竞争力的性能和先进的泛化能力。例如,在约100个样本的单样本细粒度图像分类中,Visual-RFT比基线提高了24.3%的准确率。在少样本目标检测中,Visual-RFT在COCO的两样本设置下比基线高出21.9,在LVIS上高出15.4。我们的Visual-RFT代表了LVLMs微调的范式转变,提供了一种数据高效、奖励驱动的方法,增强了特定领域任务的推理和适应能力。
一句话总结:提出视觉强化微调(Visual-RFT),将强化微调(RFT)技术拓展至视觉任务领域,通过大型视觉语言模型(LVLMs)生成含推理过程和答案的多组响应,并设计针对不同视觉任务的可验证奖励函数(如目标检测的 IoU 奖励),结合GRPO算法更新模型。

主要贡献如下:
提出 Visual-RFT 框架:首次将强化微调(RFT)技术拓展至视觉任务领域,让大视觉语言模型(LVLMs)能在少样本条件下实现高效学习。 设计任务特定可验证奖励函数:针对不同视觉任务(像目标检测、分类等),制定基于规则的奖励函数(例如 IoU 奖励、准确率奖励),以此替代传统奖励模型。 采用 GRPO 算法优化策略:通过生成多组响应并对比奖励的方式更新模型,有效提升了模型在视觉任务中的推理与泛化能力。
高分辨率视觉大模型
标题:Griffon v2: Advancing Multimodal Perception with High-Resolution Scaling and Visual-Language Co-Referring
链接:https://arxiv.org/pdf/2403.09333
主页:https://github.com/jefferyZhan/Griffon
单位:中科院自动化所、鹏城实验室、武汉人工智能研究院
摘要:大型视觉语言模型已实现细粒度的对象感知,但图像分辨率的限制仍是其在复杂密集场景中超越任务特定专家模型性能的重要障碍。这一限制还进一步制约了模型在GUI智能体、计数等领域实现精细视觉与语言指称的潜力。为解决该问题,我们引入了统一的高分辨率通用模型Griffon v2,其支持通过视觉和文本提示实现灵活的对象指称。为高效提升图像分辨率,我们设计了一种简单轻量的下采样投影器,以克服大型语言模型中输入令牌的约束。该设计从本质上保留了完整的上下文和精细细节,并显著提升了多模态感知能力,尤其是对小物体的感知。在此基础上,我们进一步通过即插即用的视觉tokenizer为模型配备了视觉-语言共指能力,使其能够与灵活的目标图像、自由形式文本甚至坐标进行友好的用户交互。实验表明,Griffon v2能够通过视觉和文本指称定位任何感兴趣的对象,在指称表达理解(REC)、短语定位和指称表达生成(REG)任务上取得了最先进的性能,并且在目标检测和目标计数任务中超越了专家模型。
一句话总结:Griffon v2 模型,一个统一的高分辨率通用模型,能够通过视觉和文本提示实现灵活的目标描述,在多模态感知任务上表现出色。

主要贡献如下:
设计高分辨率结构:采用高分辨率视觉编码器直接提取特征,搭配轻量级下采样投影器压缩视觉token,支持 1K 分辨率输入且无需分块,有效保留图像细节与上下文。 引入视觉 - 语言共指机制:通过视觉tokenizer实现视觉与文本提示的融合,支持坐标、文本描述、截图等多形式交互,能输出对象坐标或文本描述,提升细粒度感知与交互灵活性。 三阶段训练策略:结合 12M 多任务数据与 900K 指令数据,通过高分辨率对齐、共指多任务预训练及意图增强微调,使模型在检测、计数等任务超越专家模型。
3D视觉大模型
标题:Detect Anything 3D in the Wild
链接:https://arxiv.org/pdf/2504.07958
主页:https://github.com/OpenDriveLab/DetAny3D
单位:上交、上海AI Lab等
摘要:尽管深度学习在封闭集 3D 目标检测中取得了成功,但现有方法在对新物体和相机配置的零样本泛化方面存在困难。我们引入了 DetectAny3D,这是一种可提示的 3D 检测基础模型,能够仅使用单目输入在任意相机配置下检测任何新物体。训练 3D 检测基础模型从根本上受到标注 3D 数据可用性有限的制约,这促使 DetectAny3D 利用广泛预训练的 2D 基础模型中嵌入的丰富先验知识来弥补这一不足。为了有效地将 2D 知识迁移到 3D,DetectAny3D 包含两个核心模块:2D 聚合器(对齐来自不同 2D 基础模型的特征)和带零嵌入映射的 3D 解释器(缓解 2D 到 3D 知识迁移中的灾难性遗忘)。实验结果验证了 DetectAny3D 的强泛化能力,它不仅在未见类别和新相机配置上取得了最先进的性能,而且在域内数据上也超越了大多数竞争对手。DetectAny3D 为 3D 基础模型在自动驾驶中的稀有物体检测等真实场景中的各种应用提供了思路,并展示了在开放世界环境中进一步探索以 3D 为中心的任务的潜力。更多可视化结果可在我们的代码仓库中找到。
一句话总结:DetectAny3D 模型,可提示的 3D 检测基础模型,能够仅使用单目输入在任意相机配置下检测任何新物体。

主要贡献如下:
提出可提示的 3D 检测基础模型:DetectAny3D 能利用单目图像检测任意 3D 物体,支持 box、点、文本等多提示交互,实现开放世界的 3D 检测。 设计 2D Aggregator 融合模块:该模块通过分层交叉注意力机制,动态融合 SAM 和深度预训练 DINO 的特征,充分发挥两模型在物体理解和几何先验上的优势。 引入 Zero-Embedding Mapping 机制:其嵌入在 3D Interpreter 中,通过零初始化层渐进注入 3D 几何特征,解决 2D 到 3D 知识迁移中的灾难性遗忘问题。 构建 DA3D 统一数据集:整合 16 个数据集,含 0.4 百万帧和 20 种相机配置,为模型训练提供丰富多样的 3D 相关数据,提升模型泛化能力。
大模型安全
标题:Heuristic-Induced Multimodal Risk Distribution Jailbreak Attack for Multimodal Large Language Models
链接:https://arxiv.org/pdf/2412.05934
单位:中山大学、南洋理工大学、阿里巴巴、浙江大学
摘要:随着多模态大语言模型(MLLMs)的快速发展,其安全性问题日益受到学术界和工业界的关注。尽管MLLMs易受越狱攻击,但设计有效的多模态越狱攻击面临独特挑战,尤其是商业模型中各模态实施的防护措施各不相同。以往研究将风险集中于单一模态,导致越狱性能有限。本文提出一种启发式诱导多模态风险分布越狱攻击方法(HIMRD),该方法包含两个核心要素:多模态风险分布策略和启发式诱导搜索策略。多模态风险分布策略将有害指令分割到多个模态,有效规避MLLMs的安全防护;启发式诱导搜索策略识别两种提示:帮助MLLM重构恶意提示的理解增强提示,以及提高肯定输出概率(相对于拒绝输出)的诱导提示,从而实现成功越狱攻击。大量实验表明,该方法能有效发现MLLMs的漏洞,在7个主流开源MLLMs上平均攻击成功率达90%,在3个主流闭源MLLMs上平均成功率约68%。
一句话总结:一种针对多模态大语言模型的启发式诱导多模态风险分布越狱攻击方法(HIMRD),该方法通过将恶意提示分布到多个模态并结合启发式搜索策略,有效绕过模型的安全防护机制,实现对 MLLMs 的越狱攻击。

主要贡献如下:
多模态风险分布策略:将恶意提示拆分为无害的文本和图像部分,分别嵌入不同模态,避免单一模态含完整恶意语义,有效绕过模型安全防护。 启发式诱导搜索策略:通过寻找理解增强提示和诱导提示,前者助模型重构恶意提示,后者提升模型肯定输出倾向,实现成功越狱。 黑盒攻击有效性:在 10 个 MLLMs(7 开源 + 3 闭源)上实现高攻击成功率,开源模型平均 90%、闭源约 68%,优于现有方法。
本文提及的相关论文第一时间已经汇总至『大模型之心Tech知识星球』,星球内包含更多汇总。我们目标是未来3年内打造一个万人聚集的大模型技术交流社区,这里也非常欢迎优秀的同学加入我们。社区里面既能看到最新的行业技术动态、技术分享,也有非常多的技术讨论、入门问答,以及必不可少的行业动态及求职分享~
大模型之心Tech知识星球交流社区
我们创建了一个全新的学习社区 —— “大模型之心Tech”知识星球,希望能够帮你把复杂的东西拆开,揉碎,整合,帮你快速打通从0到1的技术路径。
星球内容包含:每日大模型相关论文/技术报告更新、分类汇总(开源repo、大模型预训练、后训练、知识蒸馏、量化、推理模型、MoE、强化学习、RAG、提示工程等多个版块)、科研/办公助手、AI创作工具/产品测评、升学&求职&岗位推荐,等等。
星球成员平均每天花费不到0.3元,加入后3天内不满意可随时退款,欢迎扫码加入一起学习一起卷!


 扫码添加微信
扫码添加微信
- 点赞 0
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊