


太疯狂了!PCIe 7.0 技术细节曝光:眼图已到极限!
- 2025-07-18 12:13:59
关注我们 设为星标


EETOP
百万芯片工程师专业技术论坛
官方微信号
6 月 11 日 PCI SIG官宣 PCI Express 7.0(PCIe 7.0)规范最终版已制定完毕,但几乎没有公开任何技术细节。不过,在 7 月 16 日,PCI-SIG 通过 BrightTalk 公开了一些更详细的技术信息,下面就为大家介绍这些内容。
PCI Express 7.0 的设计目标
首先是 PCI Express 7.0 的设计目标(图 1)。
图 1:关注延迟(Latency)和带宽效率低下(Bandwidth Inefficiency)
从根本上来说,PCI Express 7.0 的带宽是 PCI Express 6.0 的两倍,并且具有向后兼容性,这一点没什么问题。但需要注意的是,与 PCI Express 5.0(即采用 NRZ 编码)相比,其带宽效率下降了不到 2%,同时延迟也有所增加(虽不到 10ns)。
不过,这其中约一半原因是由于实现了 FLIT(帧单元),因此这并非 PCI Express 7.0 独有的问题,PCI Express 6.0 也存在类似情况(延迟方面还有其他因素,后文会提及)。
PCI Express 6.0 引入了 PAM4 编码,导致信号眼高(Eye Height)降至 NRZ 的约 1/3(图 2),PCI Express 7.0 也是如此。

图 2:后续会展示 PCI Express 7.0 的眼图,其情况看起来相当严峻,让人不禁担心是否可行
如图 1 所示,使用 PAM4 会导致眼高大幅降低,从而恶化误码率(BER)。为解决这一问题,若采用以太网中使用的强前向纠错(FEC)技术,会极大增加延迟(可达 100ns)。因此,PCI Express 7.0 仍沿用了 FLIT 技术,在将延迟开销降至最低的同时,将误码率控制在 1FIT 以下(图 3),这一点与 PCI Express 6.0 一致。

图 3:与 PCI Express 6.0 的指标对比后,差异便一目了然
PCI Express 7.0 新增了指标
值得注意的是,PCI Express 6.0 的指标仅包括重试概率(Retry Probability)和 FIT,而 PCI Express 7.0 新增了延迟(Latency)和带宽开销(Bandwidth Overhead),可见其设计已接近极限。
讲解中还提到了 FLIT 模式的实现,但这与之前介绍的 PCI Express 6.0 的 FLIT 模式完全相同,这里便不再赘述。
不过,PCI Express 7.0 的重试概率本身翻了一倍(图 4)。

图 4:这是理所当然的,因为单位时间内的数据量翻倍,即使单位数据量的错误率相同,表面上错误发生的频率也会翻倍
即便如此,PCI Express 7.0 的 FIT 为 4.6×10⁻¹⁰,足以满足低于 1FIT 的要求。
作为 PCI Express 6.1 特性新增的 UIO
接下来谈谈无序 I/O(Unordered IO,简称 UIO)。这是去年 10 月作为 PCI Express 6.1 的特性新增的功能。PCI Express 原本采用的是加载 - 存储访问(Load-Store Access)模式,或者说生产者 - 消费者(Producer-Consumer)模式。简单来说,当某个设备生成数据后,通过通知其他设备,使后者能够使用该数据。这里所说的设备不仅包括 PCI Express 设备,还包括根联合体(Root Complex)后端的 CPU。为保障这一机制,PCI Express 实现了 Posted(非应答)、Non-Posted(应答)、Completion(完成)等流控制(Flow Control)类别(图 05)。

图 5:这似乎与 PCI Express 原本作为 I/O 设备(因此应处于主机侧管理之下)的设计理念有关
通过信用(Credit,用于流控制的管理数据)来保障生产者 - 消费者的顺序(图 6)。

图 6:实际上,这种排序规则以层级结构为前提,因此也带来了一些问题,但这部分属于未来的工作,本次暂不讨论非层级结构
然而,这也导致了一个问题:即使多个传输同时进行,也必须按照顺序依次处理事务(图 7、8)。

图 7:在 PCI Express 设备向 CPU 传输时,CPU 向内存写入数据后,必须 “随后” 写入 Write flag f。但实际上,由于缓存的存在,顺序可能会颠倒,而这属于违规行为

图 8:同样,在 PCI Express 设备向 CPU 传输时,CPU 向内存的写入可能会乱序执行,因此事务未必会按顺序处理。但如果按照内存写入顺序发送完成事务,可能会与 PCI Express 的原始顺序不一致,因此完成事务必须符合 PCI Express 的顺序
如图 8 所示,PCI Express 虽实现了放宽排序(Relaxed Ordering,简称 RO)功能,可在一定程度上缓解上述限制,但仅靠 RO 无法解决的情况正逐渐增多。
为此,新引入了无序 I/O(UIO)机制(图 09)。

图 9:与 PCI 的延迟事务类似,简单来说,就是可以乱序发送多个事务
简言之,这是一种去除上述限制、允许事务乱序完成的机制。利用这一机制,例如在双插槽(2 Socket)系统中,可提高传输效率(图 10)。
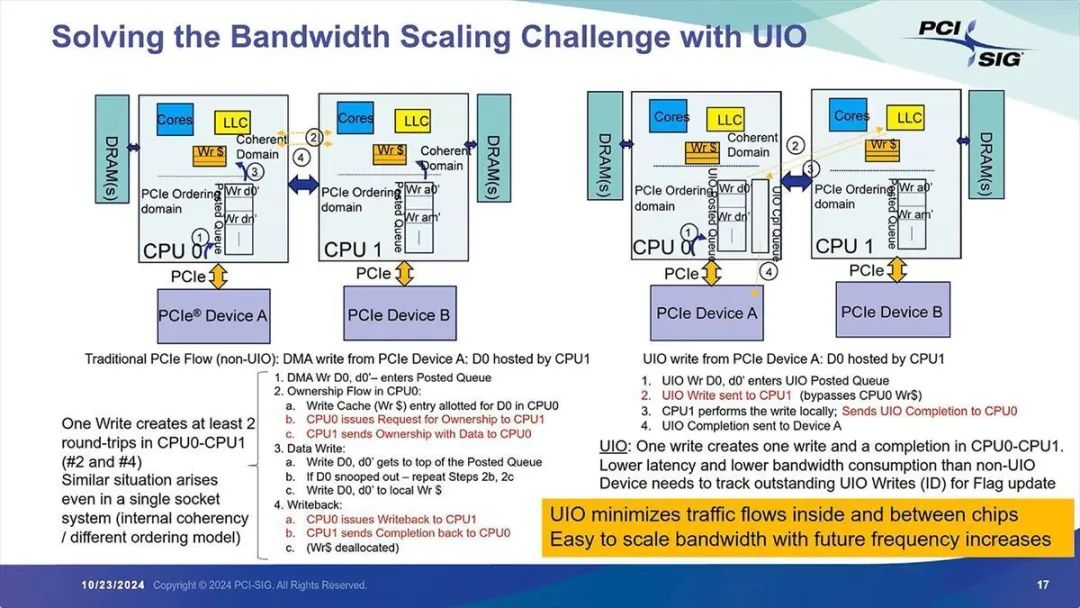
图 10:在这个例子中,CPU 0 后端的 PCIe 设备 A 向 CPU 1 传输数据。不支持 UIO 时需要执行 10 个处理步骤,而使用 UIO 只需 4 个
据 PCI-SIG 介绍,UIO 的优势包括:即使在大规模系统中也易于扩展(图 11)等(图 12)。
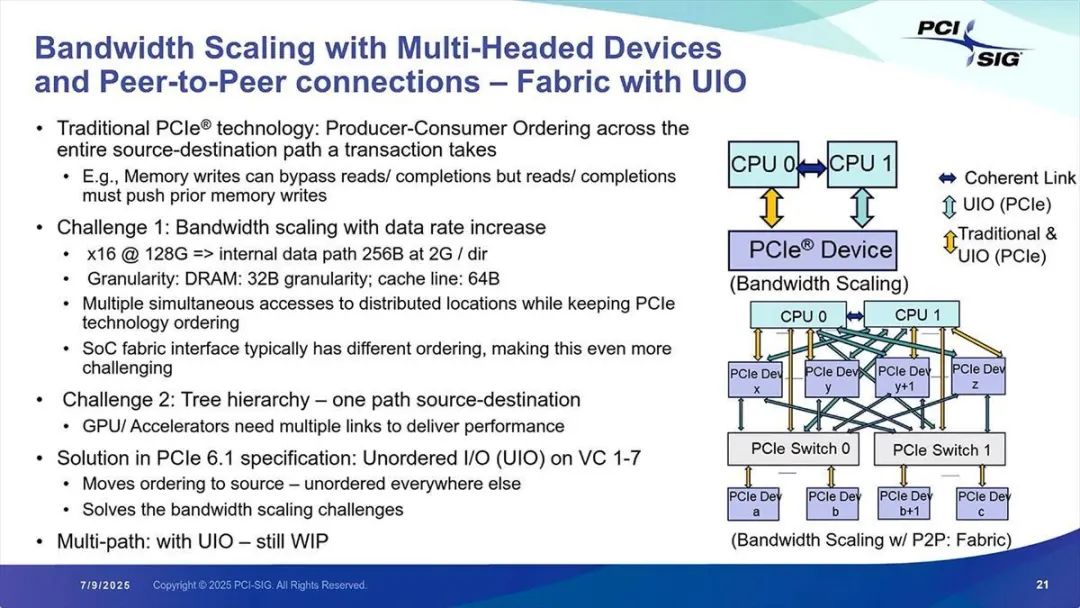
图 11:从下图可以看出,即便是 CPU×2 + 多个 PCIe 设备 + PCIe 交换机这样的场景,访问开销也会大幅降低,可在与上图中简单场景(CPU×2 + PCIe 设备)相近的开销下使用

图 12:如前所述,非树形拓扑预计未来将支持
需要说明的是,UIO 仅能在 FLIT 模式下使用,不支持非 FLIT 模式。目前,UIO 仍属于可选功能,还存在一些问题,例如空闲时延迟增加、编程环境尚未完善、支持 UIO 的原子指令尚未定义等。因此,未来或许会逐渐向 UIO 过渡,但初期的 PCI Express 7.0 控制器 / 设备是否支持 UIO,还存在不确定性。
PCI Express 7.0 的物理层
接下来谈谈物理层。如前次报道所述,配合 PCI Express 7.0,已发布了 Optical Aware Retimer(光感知重定时器)的 ECN(工程变更通知),而 ReDriver(重驱动器)的规范正在制定中,预计 2025 年末发布 ECN(图 13)。
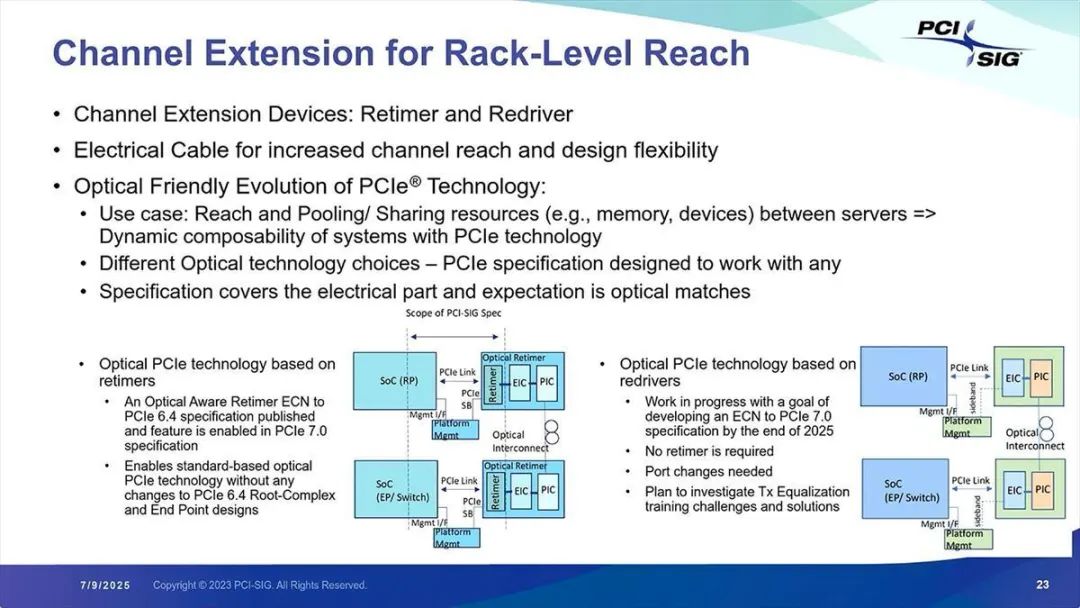
图 13:从这张图来看,Optical Aware Retimer 或许是指可集成到光互联(OCI)中的重定时器
此外,关于 CopperLink(铜缆连接),预计 2026 年末发布线缆规范(图 14)。

图 14:这里的 “PCIe 7.0 CopperLink cable solution demonstrated”,想必是在 2025 年 PCI-SIG 开发者大会(DevCon 2025)的展示环节中演示的
下面总结一下电气层的情况(图 15)。

图 15:误码率(BER)需控制在 1×10⁻⁶以下,因为结合 FLIT 可实现低于 1FIT 的目标
PCB 损耗在 32GHz 时需控制在 1dB / 英寸以下,这一要求相当严格。而接收端采用 FFE(前馈均衡器)+DFE(判决反馈均衡器)的结构,也在预料之中。由于信号频率翻倍,所有损耗都会增加,这是不可避免的。但为了平衡损耗而控制 PCB 损耗,或许需要采用玻璃基板(图 16)。
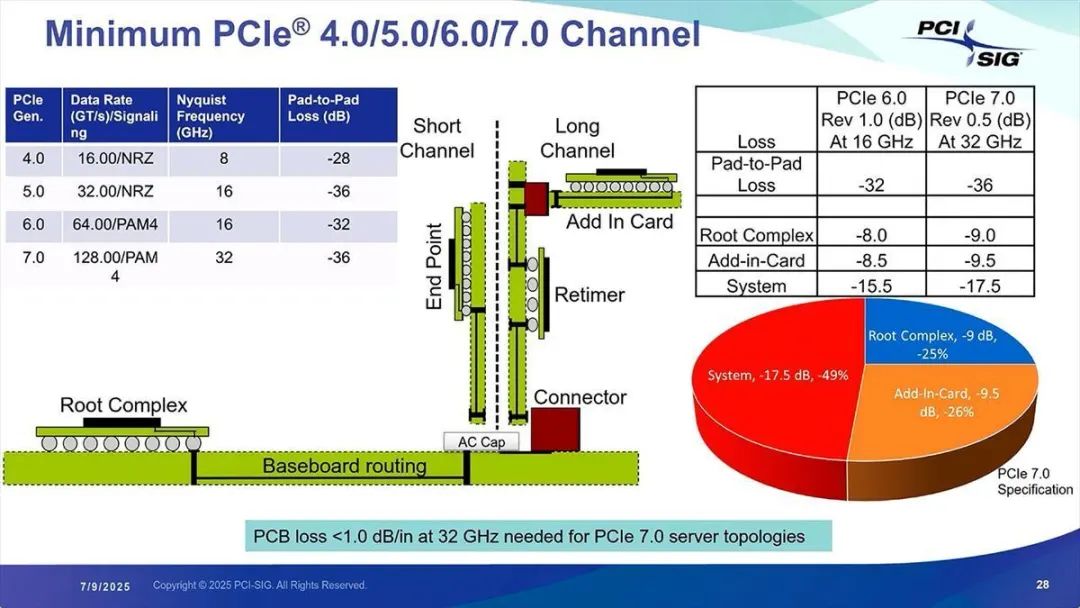
图 16:通道长度其实与 PCI Express 6.0 相同。若不做任何改进、使用相同材料构建通道,损耗会增加,因此转向在 PCB 侧控制损耗的方针
此外,各种组件的要求也更加严苛。参考时钟的抖动需控制在 0.067ps(图 17),而数据眼图若不使用二阶前导(2nd Pre-cursor),情况会相当严峻(图 18)。
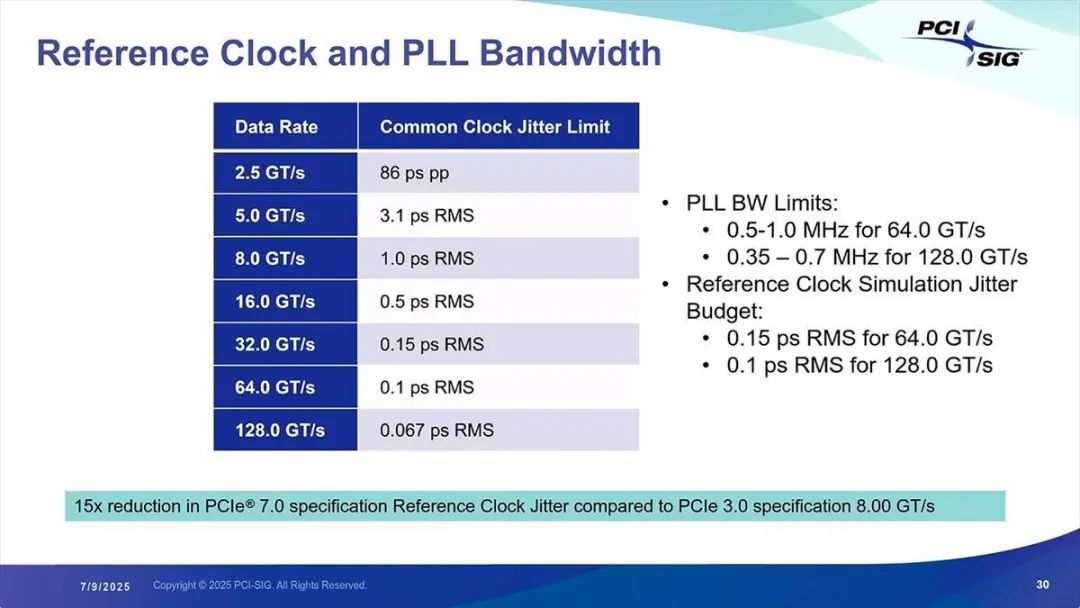
图 17:不过,例如瑞萨电子(Renesas Electronics)已推出抖动低至 55fs 的锁相环(PLL)产品,因此虽严苛但并非不可能实现

图 18:与图 2 对比,便能看出 PCI Express 7.0 的严苛程度
发送端参数如图 19 所示,接收端参数如图 20 所示。

图 19:从这些数值可以看出,整体要求相当严苛。发射端均衡(Tx Equalization)仍保持 4 抽头,可能是因为转向由接收端解决问题

图 20:眼高从 6mV 提升至 10mV,这想必是以使用发射端二阶前导(TX 2nd Pre-cursor)为前提。若不使用发射端二阶前导,能否达到 10mV,让人有些怀疑
合规眼宽(Compliance Eye Width)仅为 1.5625ps,这一数值十分惊人。而 PCI Express 6.0 仅需 16 抽头 DFE,PCI Express 7.0 则强化为 29 抽头 FFE+1 抽头 DFE,其升级幅度相当大。前文提到延迟最多增加约 10ns,这大半或许是由强化后的 FFE+DFE 导致的。
以上就是目前公开的 PCI Express 7.0 相关信息。不得不说,其已接近电信号的极限。但正如之前的文章所述,PCI Express 7.0 预计 2028-2029 年左右投入市场。到那时,组件质量能否提升到足以轻松实现这一标准的水平,还是仍会处于勉强达标的状态,笔者目前也难以判断。
欢迎加入EETOP AI/GPU 等微信群
芯片测试线下技术研讨会
(8月5日 苏州)

 扫码添加微信
扫码添加微信
- 点赞 0
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊





