500块GPU烧了4天,谷歌Deepmind的AI学会了自己设计AI,新架构NASNet横空出世
- 2025-07-06 12:16:38
揭秘谷歌大脑如何动用 500 个 GPU,发现深度学习领域最迷人的架构之一
作者: SREEDATH PANAT 与 VIZUARA AI 实验室
日期: 2025 年 7 月 4 日
曾几何时,设计神经网络是一门匠心独运的艺术。
研究人员们围坐于白板前,勾勒着层层叠叠的网络结构,热烈地讨论着是该用 3x3 还是 5x5 的卷积,是该堆叠还是分岔,如何才能抑制过拟合,又如何确保梯度顺畅地传播。岁月流转,我们见证了 VGG、Inception、ResNet、MobileNet 等经典架构的诞生——它们无一不是精心设计、手工打磨的杰作,每一次都将性能的极限向前推进一小步。
但随后,一件意想不到的事情发生了。 谷歌大脑提出了一个石破天惊的问题。
一个神经网络,能否设计出另一个更卓越的神经网络?
这个问题,直接催生了 NASNet 的诞生。它的全称是 神经网络架构搜索网络——一个被发现,而非被设计出来的模型。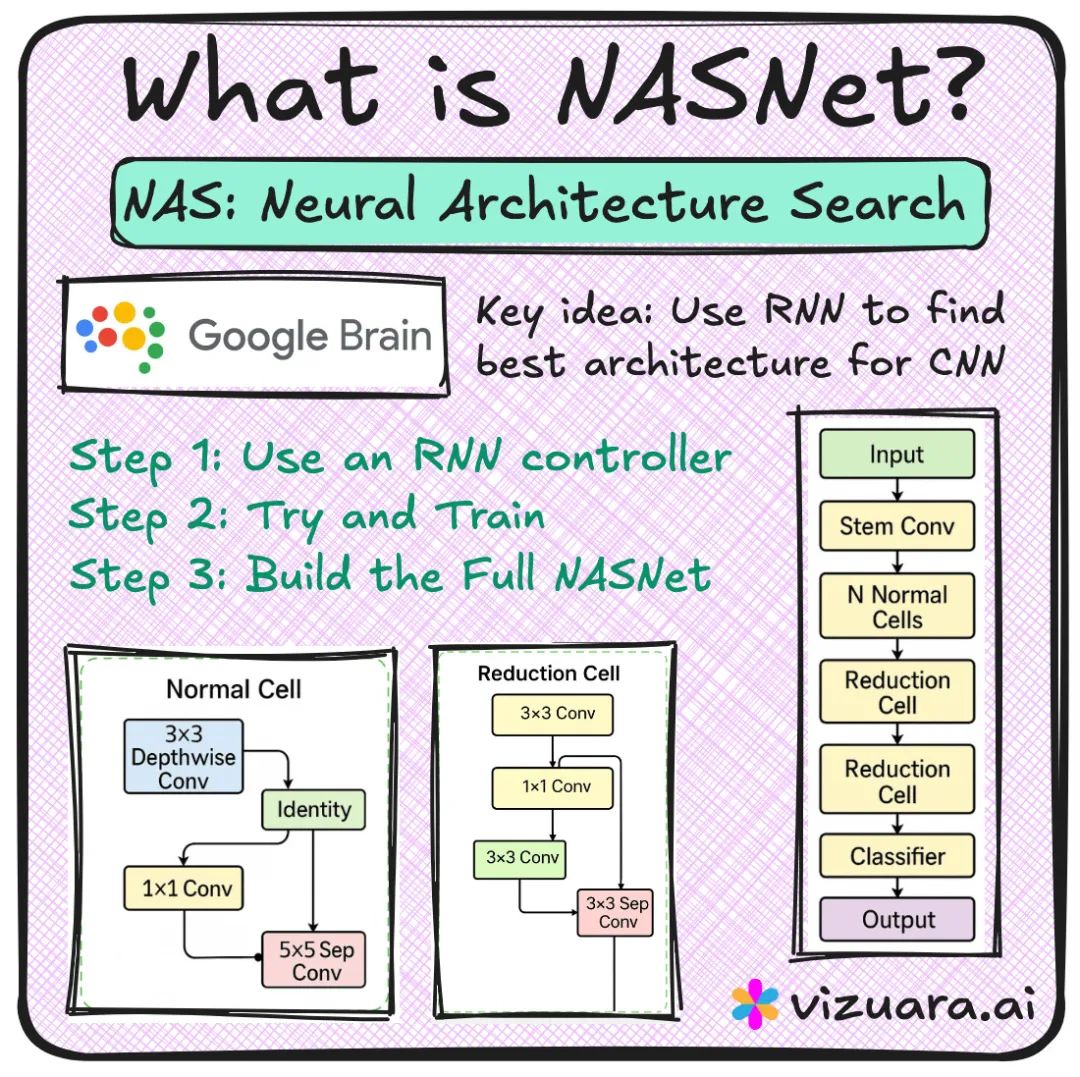
当架构可以被自动发现,为何还要人工设计?
从 AlexNet、VGG 到 Inception、ResNet,乃至 EfficientNet,我们熟知的每一个神经网络,都是人类直觉、经验与无数次试错的结晶。
设计这些模型的过程充满挑战。研究者必须去猜测,究竟哪种网络层与操作的组合能够发挥出最佳性能。他们有时能猜对,但更多时候会猜错。即便方向正确,也往往需要耗费数月光阴的反复实验,才能最终得到一个稳定的模型。
谷歌大脑的科学家们不禁思考——能否将这一过程自动化?
我们能否让一个神经网络,在浩瀚无垠的 CNN 架构空间中自行探索,并发现那个性能最优的方案?
这便是 神经网络架构搜索(简称 NAS)的初衷,而 NASNet 正是这一思想下的产物。

NAS 工作原理解析:RNN + 强化学习 = 架构搜索
它的工作流程可以分解如下:
首先,一个 RNN 控制器 负责生成架构的蓝图——它会输出一个序列,用以描述如何连接卷积、池化、恒等映射等不同的基础操作。 每一份蓝图都定义了一个可复用的构建模块,我们称之为单元。 这些单元主要分为两种:
常规单元:在构建网络时保持特征图的空间尺寸不变。 缩减单元:负责降低特征图的空间尺寸,功能类似于最大池化层。



这个循环需要重复数千次,其计算成本高昂得惊人。根据 NASNet 的原论文,仅搜索架构这一步,就动用了 500 块 GPU 整整运行了四天。
但最终的成果证明,这一切都是值得的。 RNN 控制器成功发现了一组表现极为出色的单元。基于这些单元构建的 NASNet-A (Large) 模型,在 ImageNet 等多个权威基准测试中,取得了当时最顶尖的成果。
乐高的比喻
我们可以用一个简单的比喻来理解这个过程。
想象一下,你给一个孩子一整桶乐高积木,让他去搭建一座城堡。每一块积木,就好比一个卷积层、一个跳跃连接或一个池化层。如果孩子搭出了一座既稳固又漂亮的城堡,你就给他奖励;如果城堡塌了,他就什么也得不到。
随着时间的推移,这个孩子自然会学会如何搭建出越来越好的城堡。
在神经网络架构搜索中,那个孩子就是 RNN 控制器,乐高积木就是各种基础操作,城堡就是最终的 CNN 模型,而奖励,就是在 CIFAR-10 这类数据集上的验证准确率。
这个过程并非什么魔法,它缓慢、耗费算力,甚至有些“粗暴”,但它确实行之有效。

NASNet 为何与众不同?
与 ResNet 或 MobileNet 不同,NASNet 在传统意义上并不是模块化的。
虽然它也是通过重复堆叠常规单元和缩减单元来构建,但这些单元的核心区别在于它们是被发现的,而非被人类设计的。这里没有像 Fire 模块或深度可分离卷积那样,由某位研究员灵光一现想出的精巧结构。NASNet 的单元,完全是在奖励信号的引导下,对整个架构空间进行暴力优化后的产物。


这也使得解释 NASNet 的工作原理变得异常困难。
谈及 VGG,我们可以说,它通过堆叠 3x3 卷积来加深网络。 谈及 ResNet,我们可以说,它利用跳跃连接解决了梯度消失的问题。 而谈及 NASNet,我们只能这样描述:“搜索算法发现,将 1x1、3x3、5x5 卷积、恒等映射和池化等操作,按照某种特定的方式组合起来,能够产生最佳效果。”
我们能做的,只是在架构被找到之后,再去尝试解读它。
这正是 NASNet 令人着迷,又令人颇感无奈的地方。

在“五种花卉”数据集上实战 NASNet
在本课程中,由于 PyTorch 官方并未提供预训练的 NASNet 模型,我们选用了 Keras 在自建的“五种花卉”数据集上对 NASNet Large 模型进行了实现。
一些关键信息如下:
输入图像尺寸:331x331 总参数量:约 8800 万 模型大小:约 343 MB 预训练:已在 ImageNet 数据集上完成 微调策略:仅重新训练最后的分类头
仅仅训练了 2 个周期,我们就达到了:
训练准确率:87% 验证准确率:85%
不过,训练过程非常缓慢——在 CPU 上慢得令人痛苦。仅仅 3 个周期就耗费了超过 3 个小时。NASNet 是一个重量级模型,除非你拥有强大的 GPU 或 TPU,否则不建议用它来进行快速实验。

各模型对比

| MobileNet | |
| ResNet50 | |
| NASNet |
代码




结语
神经网络架构搜索并非 CNN 设计的终点,而是一个全新的纪元。
NASNet 向我们证明,模型设计这项工作可以外包给机器。它雄辩地说明,在强化学习和精心设计的搜索空间引导下,神经网络能够创造出人类设计师可能永远无法构思出的架构组件。
但它也同时提醒着我们现实的局限。
训练 NASNet 的成本高昂,解释其架构的原理晦涩,而且,除非你在拥有 500 块 GPU 的顶级研究室工作,否则你几乎不可能亲自复现整个 NAS 算法。
尽管如此,它依然是人工智能领域向前迈出的里程碑式的一步。正是这一步,启发了后来者创造出像 EfficientNet 这样更高效的架构——它不仅继承了 NAS 的核心思想,还通过复合缩放策略将效率提升到了新的高度。
想和更多聪明大脑一同探讨AI前沿? 添加主理人微信:znqbs1,备注“情报”,我会邀请你进入“智能情报所”核心社群,共同进步,期待我们都有所获得。
本期推荐其他阅读:
刚刚,延迟超25秒,上下文仅64K,DeepSeek的低价策略成功了吗?
美国AI“曼哈顿计划”数据曝光,算力超GPT-4万倍,2700万块H100集结,目标直指2027
a16z错了,为什么GEO是一个缺乏技术和商业基础的构想?随机性、不确定性,以及旧 SEO 思维为何在 AI 时代难以为继
算个账刷屏硅谷:AI创业就是给英伟达和OpenAI打工,为什么说,大多数 VC 还没搞懂 AI 的真实游戏规则?
对话Canva联合创始人:坐拥每月10亿份设计,全球最受欢迎设计工具背后的AI策略
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!

 扫码添加微信
扫码添加微信
- 点赞 0
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊