


阿里推出Qwen3背后的GSPO算法,破解大模型尤其是混合专家模型强化学习的稳定性难题
- 2025-07-29 23:31:03

本文由 Intern-S1、Qwen3 等 AI 生成, 由机智流编辑部校对
近年来,大语言模型(LLMs)在自然语言处理、数学推理、编程等领域的表现令人瞩目,而强化学习(Reinforcement Learning, RL)作为提升模型能力的关键技术,正成为AI研究的前沿热点。然而,随着模型规模的扩大和任务复杂度的增加,强化学习的训练稳定性问题逐渐暴露,尤其是在稀疏激活的混合专家模型(Mixture-of-Experts, MoE)中,训练过程常常面临灾难性的模型崩溃。针对这一挑战,阿里巴巴Qwen团队提出了一种全新的强化学习算法——Group Sequence Policy Optimization (GSPO) ,通过序列级别的优化设计,显著提升了训练的稳定性、效率和性能,为大语言模型的强化学习训练开辟了新的可能性。这项成果不仅推动了Qwen3模型的性能突破,还为未来AI模型的规模化训练提供了坚实的算法基础。
目前 huggingface 的强化学习库 trl 和阿里的大模型微调库 ms-swift 已支持该算法。
论文链接:https://huggingface.co/papers/2507.18071
trl 对 GSPO 的支持:https://github.com/huggingface/trl/pull/3775
ms-swift 对 GSPO 的支持:https://swift.readthedocs.io/zh-cn/latest/Instruction/GRPO/AdvancedResearch/GSPO.html

GSPO的创新突破
GSPO的核心创新在于重新定义了强化学习中的重要性比率(importance ratio),从传统的基于单个token的计算转向基于整个序列的可能性(sequence likelihood)。这一转变源于对现有算法(如GRPO)的深入剖析。GRPO(Group Relative Policy Optimization)作为一种主流的强化学习算法,通过比较同一查询下多个响应的相对优势,规避了对价值模型的依赖。然而,GRPO在处理长序列任务和大模型时,表现出显著的不稳定性。Qwen团队发现,这一问题根源在于GRPO在token级别应用重要性权重,导致训练过程中引入了高方差噪声。这种噪声随着序列长度的增加而累积,并被裁剪机制进一步放大,最终可能引发不可逆的模型崩溃。
为了解决这一问题,GSPO提出了序列级别的优化目标。GSPO通过计算整个序列在当前策略和旧策略下的可能性比率,结合序列级别的奖励和裁剪机制,确保优化过程与奖励分配保持一致。这种设计不仅遵循了重要性采样的基本原理,还通过长度归一化(length normalization)降低了序列可能性比率的波动性,使其在不同序列长度下保持统一的数值范围,从而大幅提升了训练的稳定性。
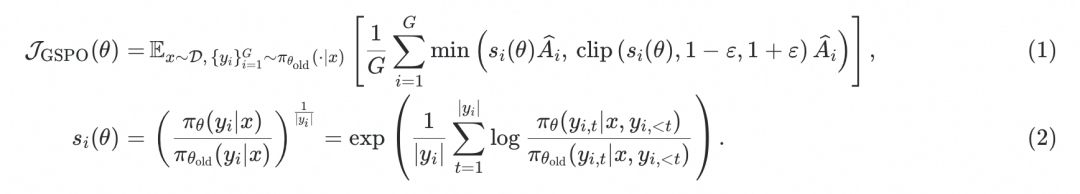
此外,GSPO还推出了一个token级别的变体算法GSPO-token,允许在多轮强化学习场景中进行更精细的优势调整,同时保留了序列级别优化的核心优势。
GSPO的另一个显著优势是其对混合专家模型(MoE)的优化效果。MoE模型因其稀疏激活特性,在强化学习训练中常常面临专家激活的不稳定问题。GRPO需要依赖额外的路由重放(Routing Replay)策略来稳定训练,但这增加了内存和通信开销,并限制了模型的实际容量。相比之下,GSPO通过关注序列级别的可能性,直接规避了token级别可能性波动带来的问题,无需复杂的稳定策略即可实现MoE模型的稳定训练。这不仅简化了训练流程,还释放了MoE模型的全部潜力。
实验设计与方法
为了验证GSPO的性能,Qwen团队基于Qwen3-30B-A3B-Base模型进行了冷启动实验,比较了GSPO与经过仔细调优的GRPO算法在多个基准测试上的表现。实验设计涵盖了以下几个关键方面:
数据集与任务:实验使用了AIME’24(数学推理)、LiveCodeBench(202410-202502,编程能力)和CodeForces(Elo评分)等基准测试,评估模型在复杂任务上的表现。这些任务要求模型进行深度推理和长序列生成,充分考验了算法的稳定性与效率。
训练设置:团队从Qwen3-30B-A3B-Base模型开始进行强化学习微调,记录了训练过程中的奖励曲线和模型性能曲线。GSPO和GRPO均在相同的计算资源和查询集更新条件下进行比较,以确保公平性。特别地,GRPO需要使用路由重放策略来保证MoE模型的正常收敛,而GSPO则无需此策略。
评估指标:实验主要关注训练的稳定性(是否发生模型崩溃)、训练效率(在相同计算资源下达到的性能提升)以及在基准测试上的性能表现(如AIME’24的Pass@1分数、LiveCodeBench的Pass@1分数和CodeForces的Elo评分)。
实验中,GSPO的序列级别裁剪机制和归一化重要性比率被特别验证。团队还分析了裁剪比例(clipping fraction)对训练效果的影响,发现GSPO尽管裁剪了更多的token,却依然展现出更高的训练效率,这一现象进一步印证了其优化设计的有效性。
实验结果与分析
实验结果显示,GSPO在训练稳定性、效率和性能上全面超越了GRPO。以下是主要发现:
训练稳定性:如图1所示,GSPO的训练过程始终保持稳定,未出现模型崩溃的现象。相比之下,GRPO在训练MoE模型时需要依赖路由重放策略,且在长序列任务中容易因高方差噪声导致性能波动。GSPO通过序列级别的优化设计,消除了这些不稳定因素,使得训练过程更加可靠。

图1:Qwen3-30B-A3B-Base模型的训练曲线,GSPO展现出比GRPO更高的训练效率和稳定性。
训练效率:GSPO在相同的计算资源和查询消耗下,取得了更高的训练精度和基准性能。实验表明,GSPO能够通过增加训练计算量、定期更新查询集以及延长生成序列长度,持续提升模型性能。这种高效性得益于序列级别优化的低噪声特性,使模型能够更充分地利用样本数据。
性能表现:在AIME’24、LiveCodeBench和CodeForces等基准测试中,GSPO训练的模型在Pass@1分数和Elo评分上均优于GRPO训练的模型。这些结果表明,GSPO不仅提升了训练过程的稳定性,还显著增强了模型在复杂推理任务上的能力。
裁剪比例的观察:如图2所示,GSPO的token裁剪比例比GRPO高出两个数量级,但其训练效率却更高。这一发现颠覆了直觉,表明GRPO的token级别梯度估计存在固有的噪声,而GSPO的序列级别方法提供了更可靠的学习信号。
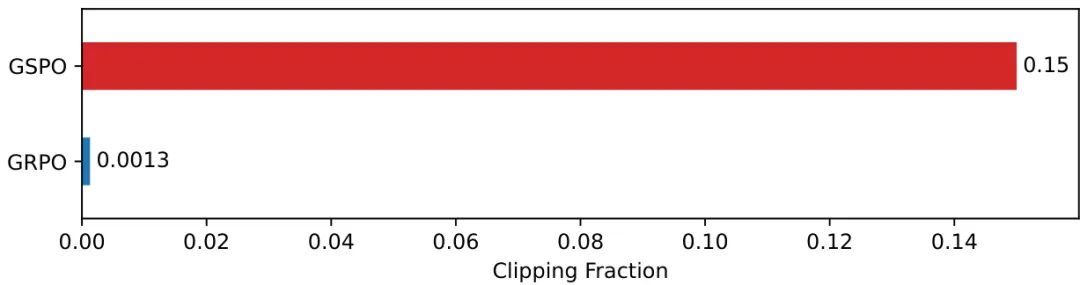
图2:GSPO与GRPO在强化学习训练中的token裁剪比例,GSPO的高裁剪比例并未影响其训练效率。
MoE模型训练的突破:如图3所示,GRPO在MoE模型训练中依赖路由重放策略,而GSPO无需此策略即可实现稳定收敛。GSPO通过关注序列可能性,规避了专家激活波动的影响,显著简化了MoE模型的强化学习流程。

图3:路由重放策略在GRPO训练MoE模型中的关键作用,GSPO无需此策略即可稳定训练。
GSPO的广泛影响
GSPO的提出不仅在技术层面解决了强化学习训练的稳定性问题,还对AI基础设施的设计产生了深远影响。传统强化学习训练通常需要在训练引擎(如Megatron)中重新计算旧策略下的序列可能性,以应对训练与推理引擎之间的精度差异。而GSPO由于仅依赖序列级别的可能性,对精度差异的容忍度更高,因此可以直接使用推理引擎(如SGLang或vLLM)返回的可能性进行优化。这不仅降低了计算开销,还为部分rollout、多轮强化学习以及训练-推理分离框架提供了更大的灵活性。
此外,GSPO的成功应用在Qwen3模型的性能提升中得到了充分体现。作为阿里巴巴Qwen团队的最新成果,Qwen3模型在GSPO的加持下,展现出卓越的数学推理和编程能力,为复杂任务的解决提供了强大支持。这一成果也为未来大语言模型的规模化强化学习奠定了坚实基础。
未来展望
GSPO的出现标志着大语言模型强化学习领域的一次重要突破。其序列级别的优化设计不仅解决了GRPO的固有缺陷,还为MoE模型的训练提供了简单而高效的解决方案。展望未来,GSPO有望成为强化学习训练的标杆算法,推动AI模型在更复杂任务和更大规模上的持续进步。阿里巴巴Qwen团队表示,他们将基于GSPO继续探索强化学习的边界,期待在智能技术的核心领域实现更多突破。
论文链接:https://huggingface.co/papers/2507.18071
trl 对 GSPO 的支持:https://github.com/huggingface/trl/pull/3775
ms-swift 对 GSPO 的支持:https://swift.readthedocs.io/zh-cn/latest/Instruction/GRPO/AdvancedResearch/GSPO.html
-- 完 --
机智流推荐阅读:
1. Code is Cheap,Show me your Prompt!Spec 将成为一统天下的编程语言
2. 打通投机采样最后一公里!SGLang联合美团技术团队开源投机采样训练框架
3. LLM智能购物助手革新电商体验!从直接搜索商品转向提出场景需求,揭秘香港科技大学等如何打造电商智能规划新标杆
4. Intern-S1发布8小时内,我用了8000万Tokens生成了3000篇ACL2025论文解读博客!
关注机智流并加入 AI 技术交流群,不仅能和来自大厂名校的 AI 开发者、爱好者一起进行技术交流,同时还有HuggingFace每日精选论文与顶会论文解读、Talk分享、通俗易懂的Agent知识与项目、前沿AI科技资讯、大模型实战教学活动等。
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 智能体 | Agent 技术交流群
 扫码添加微信
扫码添加微信
- 点赞 (0)
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊





