


阶跃Step 3凭何引爆WAIC?技术解读:注意力解耦、MoE变局与国产芯片狂飙
- 2025-07-29 08:00:00
点击下方卡片,关注“大模型之心Tech”公众号
>>点击进入→大模型技术交流群
写在前面
2025年世界人工智能大会(WAIC 2025)的聚光灯下,阶跃星辰公司发布的新一代基础大模型Step 3以其革命性的技术创新和卓越的商业化潜力,迅速成为全球AI领域关注的焦点。
作为中国开源模型军团的又一力作,Step 3不仅重新定义了多模态推理模型的性能标准,更在国产芯片适配和推理效率方面实现了前所未有的突破,为AI技术的实际落地应用树立了新的标杆。在WAIC 2025这一全球顶级AI盛会上,Step 3凭借其"多开好省"的核心特性——多模态能力、开源策略、卓越性能和成本效益,赢得了学术界和产业界的广泛赞誉,被誉为"开源多模态推理之王"。
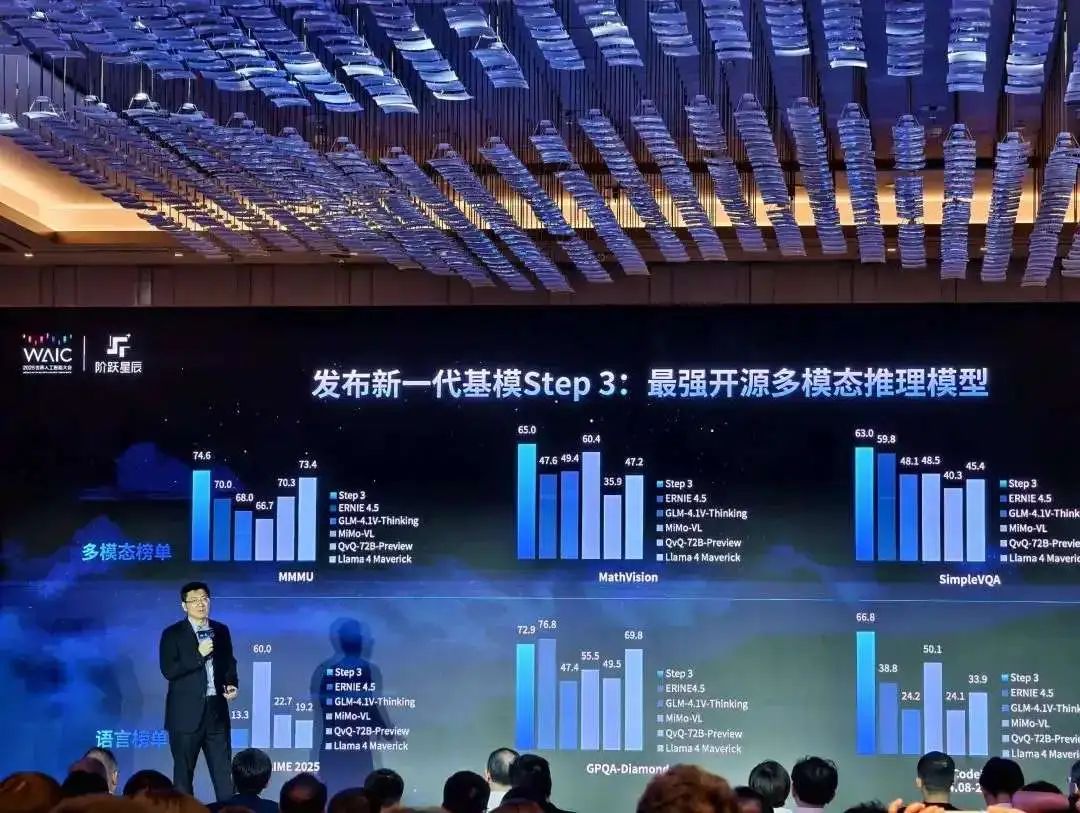
这一突破性进展背后,究竟隐藏着哪些技术创新?多矩阵分解注意力机制如何平衡计算量与表达能力?注意力-前馈网络分离架构又为何能成为提升硬件利用率的关键?
本文将深入解析Step-3的技术细节,揭示大模型推理效率优化的核心逻辑。
技术报告链接:https://arxiv.org/pdf/2507.19427v1
Step-3模型架构
千亿模型的推理困境:解码阶段成成本黑洞

大语言模型的推理过程分为预填充(prefill)和解码(decoding)两个阶段。其中,解码阶段因每生成一个token都需要与历史上下文进行注意力计算,硬件利用率(MFU)通常远低于训练阶段和预填充阶段,成为整个推理流程中"最昂贵的环节"。
阶跃星辰团队在研究中指出,对于需要长思考链的推理任务,解码成本直接决定了固定预算下模型能达到的智能水平。以DeepSeek-V3和Qwen3 MoE 235B等主流千亿模型为例,其解码成本随上下文长度增长呈线性上升趋势,在8K上下文时的成本已成为制约模型应用的重要因素。

更关键的是,模型参数规模与解码成本之间并非简单的正相关关系。Qwen3 MoE 235B的总参数比DeepSeek-V3少65%,激活参数少40%,但解码成本仅降低10%;而Step-3虽然拥有3210亿总参数和380亿激活参数(高于上述两者),却能实现40%的成本降幅。这一现象彻底颠覆了"参数越少成本越低"的传统认知,揭示出模型架构设计与硬件特性的匹配度才是决定解码成本的核心因素。
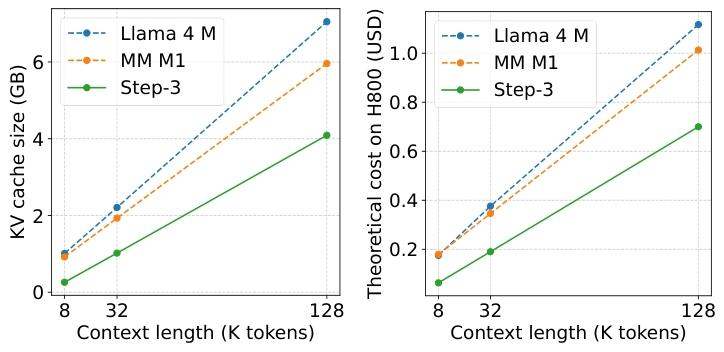
从技术角度看,传统Transformer架构将注意力层和前馈网络(FFN)视为不可分割的整体,导致硬件资源无法根据两者的特性进行针对性优化。注意力层需要存储大量键值缓存(KV cache),对内存带宽需求极高;而FFN层(尤其是MoE模型)参数规模庞大,计算密集但无需保存中间结果。这种特性差异使得统一部署模式必然面临资源分配失衡的问题——要么内存带宽成为注意力计算的瓶颈,要么计算资源无法充分利用FFN的并行性。
Step-3的创新之处在于,它不再将模型架构与部署系统视为相互独立的环节,而是通过模型-系统协同设计,让注意力机制和硬件特性形成良性互动,最终在参数规模更大的情况下实现了成本的显著降低。

多矩阵分解注意力(MFA):重新定义注意力计算效率
注意力机制作为Transformer的核心组件,其设计直接决定了解码阶段的计算成本和内存开销。Step-3提出的多矩阵分解注意力(MFA)机制,通过低秩矩阵分解技术,在保持高表达能力的同时,实现了KV缓存规模与计算量的双重优化。
传统注意力机制中,查询(Q)、键(K)、值(V)的投影矩阵均为满秩矩阵,导致KV缓存随上下文长度线性增长。以8K上下文为例,DeepSeek-V3的KV缓存访问量达到2.88×10⁸字节,而Qwen3 MoE更是高达7.89×10⁸字节。这种庞大的内存访问需求不仅消耗大量带宽,还限制了硬件选择的灵活性——只有高端GPU(如H800)才能勉强满足其性能要求。
MFA机制的突破在于对QK电路的矩阵分解优化。它将查询头的维度从7168下投影到2048的低秩空间,再通过64个查询头与共享的键值头进行交互。这种设计在保持16384的注意力有效秩(与DeepSeek-V3相当,是Qwen3 MoE的两倍)的同时,将8K上下文的KV缓存访问量降至2.56×10⁸字节,较DeepSeek-V3减少11%,仅为Qwen3 MoE的32%。
更精妙的是,MFA实现了算术强度(计算量与内存访问量的比值)与硬件特性的精准匹配。测试数据显示,MFA的算术强度为128(FP8量化下),这一数值与A800(156)和Ascend 910B(175)的计算-带宽比(roofline)非常接近,使得这些中高端GPU能够充分发挥性能。相比之下,DeepSeek-V3的算术强度高达512,远超H20等中端GPU的承载能力,导致其在非旗舰硬件上的效率骤降;而Qwen3的算术强度仅32,无法充分利用H800的计算能力,造成资源浪费。

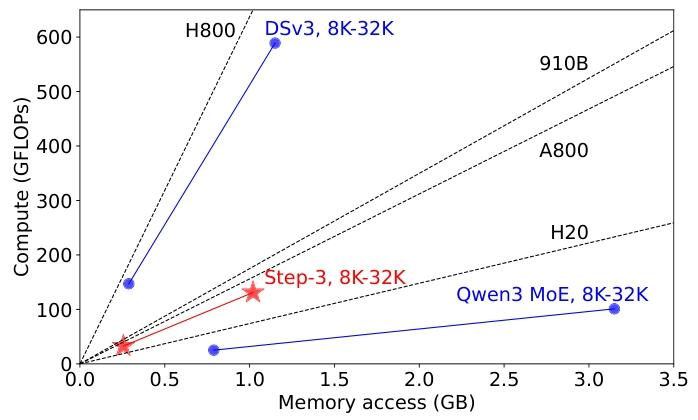
这种硬件亲和性设计让Step-3在不同档次的GPU上都能保持稳定的高效性。在H800上,MFA的内存带宽利用率达到90%以上;在H20上,其解码成本仅比最优配置高出15%,而DeepSeek-V3在H20上的成本是H800的2.4倍,Qwen3在H800上的成本是H20的2.0倍。这种跨硬件的适应性为Step-3的低成本部署提供了极大灵活性。
值得注意的是,MFA在降低计算开销的同时,并未牺牲模型的表达能力。通过多矩阵分解的精巧设计,其注意力有效秩与DeepSeek-V3持平,确保了长上下文推理任务中的性能表现。这一特性使其在医疗诊断、代码生成等对上下文理解要求极高的场景中,既能保持精度优势,又能控制成本增长。
AFD架构:让注意力与FFN各得其所

如果说MFA解决了注意力计算的效率问题,那么注意力-FFN分离(AFD)架构则彻底重构了大模型的推理系统设计,为模型与硬件的协同优化提供了底层支撑。
传统推理系统将Transformer层视为不可分割的单元,导致注意力和FFN不得不共享相同的硬件资源,形成"顾此失彼"的困境。AFD架构的核心思想是将两者解耦为独立的子系统,使其能够在最适合自己的硬件上以最高效率运行——注意力子系统部署在内存带宽充裕的GPU上,FFN子系统则运行在计算能力强大的硬件上,通过高速网络实现协同。
这种分离设计带来了多重优势:首先,注意力子系统可以专注于优化KV缓存的存储和访问模式,采用适合长上下文的内存分配策略;其次,FFN子系统能够通过专家并行(EP)充分利用MoE的稀疏性,同时保持理想的批处理规模以提高计算效率;最重要的是,两者可以独立扩展,避免了传统部署中"为匹配最慢组件而牺牲整体性能"的问题。

AFD的实现依赖于三步流水线设计:注意力计算(A)、A到F的通信(C1)、FFN计算(F)、F到A的通信(C2)。通过精确调控各阶段的耗时(每个阶段约16.6ms),实现计算与通信的完全重叠,消除了传统分布式推理中的等待开销。在实际测试中,这种流水线设计使网络通信延迟被完全隐藏,端到端延迟仅由计算时间决定,达到了50ms/token的服务等级协议(SLA)要求。
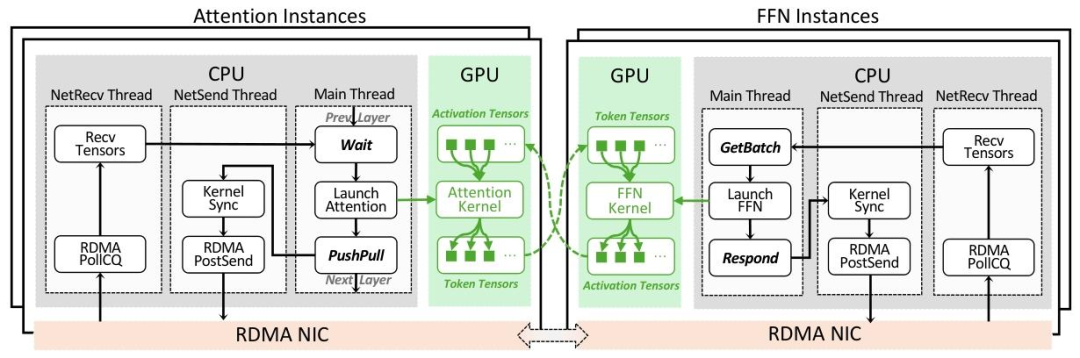
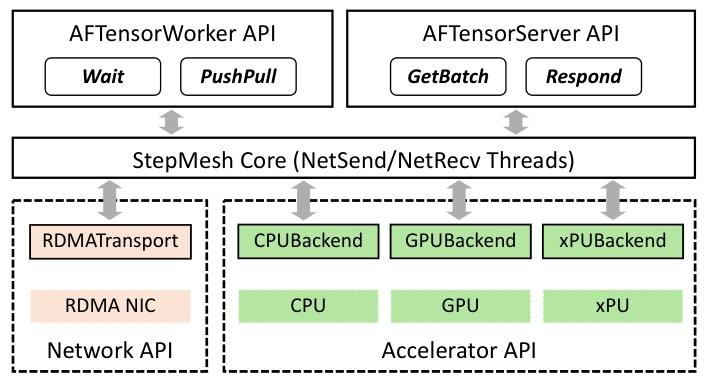
为支撑AFD架构,阶跃星辰团队开发了专门的通信库StepMesh,基于GPUDirect RDMA技术实现了超低延迟的数据传输。StepMesh采用异步API设计,将通信操作与计算任务分离,通过NUMA-aware的CPU核心绑定和预注册张量机制,将单次通信延迟控制在272µs以内,满足了流水线的严格时序要求。在Rail-Optimized RoCE网络上,其双向通信带宽利用率达到95%以上,确保了注意力与FFN子系统之间的高效协同。
与DeepSeek-V3采用的DeepEP架构相比,AFD在部署规模和灵活性上具有显著优势。DeepEP为解决FFN的通信瓶颈,需要至少320块GPU才能维持高效运行,而Step-3的AFD架构在32块GPU上即可实现稳定的高吞吐量;在扩展性方面,AFD通过简单增加注意力实例即可支持更长的上下文(如从4K扩展到32K仅需增加4倍注意力GPU),而DeepEP的扩展需要重新平衡整个集群,复杂度呈指数级增长。
在实际性能测试中,AFD架构的优势得到充分验证。在4K上下文、FP8精度的配置下,Step-3的解码吞吐量达到4039 tokens/GPU/s,较DeepSeek-V3的2324提升74%;在32K长上下文场景中,其优势进一步扩大到85%,展现出随上下文长度增加而效率衰减更慢的特性。这种特性使其在法律文档分析、历史对话总结等长文本处理任务中,成本优势尤为突出。
AFD架构还为异构硬件部署创造了可能。Step-3可以将注意力子系统部署在H20等中端GPU上,同时将FFN子系统运行在H800上,通过智能调度实现整体成本的最优化。测试显示,这种混合部署模式较全H800配置可降低30%成本,而性能仅下降12%,为资源受限场景提供了实用的解决方案。
MoE设计:在稀疏性与硬件效率间找到平衡点
作为3210亿参数的超大模型,Step-3采用了混合专家(MoE)结构来平衡模型能力与计算开销,但与其他MoE模型不同的是,其专家设计深度融合了硬件特性,避免了"纸面稀疏性"与"实际效率"的脱节。
MoE模型通过激活少量专家(而非全部)来减少计算量,但过度稀疏的设计往往导致硬件效率低下。DeepSeek-V3和Kimi K2采用8-in-256的稀疏模式(稀疏度0.031),虽然激活参数少,但在H800上的实际计算效率仅为理论值的60%——大量时间浪费在专家间的数据传输上。Step-3通过硬件感知的稀疏度优化,将稀疏度控制在0.08左右(含共享专家),在保持计算量优势的同时,显著降低了通信开销。
从理论上看,MoE的最优稀疏度需要平衡计算能力、内存带宽和网络带宽三者的关系。阶跃星辰团队推导出的公式显示,对于H800而言,MoE的稀疏度不应低于0.058,否则网络通信将成为瓶颈;而H20的内存带宽更充裕,可支持低至0.007的稀疏度。Step-3的0.08设计恰好落在H800的最优区间,使其FFN计算的硬件利用率达到85%以上,而DeepSeek-V3的0.031稀疏度导致其网络传输时间比计算时间长40%,严重拖累效率。
在专家组织方式上,Step-3采用了"共享专家+动态路由"的策略。每个FFN层包含1个共享专家和128个专用专家, tokens根据自身特征动态选择4个专用专家与共享专家协作。这种设计既保证了模型的表达能力,又通过共享专家减少了跨节点通信——共享专家的计算结果无需在节点间传输,直接在本地完成聚合。相比之下,DeepSeek-V3的所有专家均为专用型,导致每个token的计算结果都需要跨节点传输,通信量增加30%以上。
AFD架构与MoE设计的协同进一步放大了效率优势。在AFD中,FFN子系统可以独立采用专家并行(EP)或张量并行(TP),而不必受注意力子系统的限制。Step-3采用TP+EP的混合模式,在8节点集群中,每个节点负责16个专家的计算,通过局部聚合减少全局通信。测试显示,这种部署方式的通信效率是DeepEP的2.3倍,在32K上下文时的优势更达到3.1倍。
值得注意的是,Step-3的MoE设计充分考虑了非旗舰硬件的特性。在L20 GPU上,其FFN计算的内存带宽利用率仍能保持70%以上,而DeepSeek-V3在L20上的效率不足30%。这种适应性使得Step-3能够在成本敏感场景中,通过混合部署进一步降低硬件投入,而性能损失控制在可接受范围内。
MoE的动态路由机制也经过了硬件友好性优化。Step-3的路由算法会尽量将同一批次的tokens分配给相同的专家组,减少跨节点的数据交换;同时,路由决策仅依赖本地特征,避免了全局通信。这种设计使专家负载均衡度提升至90%以上,远高于DeepSeek-V3的75%,有效消除了传统MoE中"热门专家"导致的性能瓶颈。
性能实测:重新定义大模型推理的效率标杆
在Hopper GPU集群上的实测数据显示,Step-3的性能表现全面超越现有模型,在吞吐量、成本效率和长上下文扩展性三个维度上树立了新标杆。

在4K上下文、50ms TPOT SLA(服务等级协议)的标准配置下,Step-3的解码吞吐量达到4039 tokens/GPU/s,较DeepSeek-V3的2324提升74%,较Qwen3 MoE 235B提升58%。这意味着在相同的硬件投入下,Step-3能够处理的请求量是竞品的1.7倍以上,直接转化为服务能力的显著提升。
随着上下文长度增加,Step-3的优势进一步扩大。在8K上下文场景中,其吞吐量为2643 tokens/GPU/s,是DeepSeek-V3的1.8倍;在32K上下文时,这一比例达到1.9倍。这种特性使其在长文本处理场景中更具成本优势——处理100万token的32K文档,Step-3的硬件投入仅为DeepSeek-V3的53%,为Qwen3 MoE的57%。
成本效率方面,Step-3在8K上下文时的解码成本为0.055美元/百万token,较DeepSeek-V3的0.068美元降低19%,较Qwen3 MoE的0.062美元降低11%;在32K上下文时,其成本优势扩大至40%,仅为0.129美元/百万token,而DeepSeek-V3和Qwen3 MoE分别为0.211和0.193美元。这种随上下文长度增加而成本优势扩大的特性,使其在企业级长文本应用中极具竞争力。
从硬件利用率来看,Step-3的AFD架构使注意力子系统的MFU(模型 FLOPs 利用率)达到85%,FFN子系统的MFU达到90%,整体系统效率远超传统部署模式的60%-70%。这种高效性来自于三个方面:注意力与FFN的独立优化、硬件特性的精准匹配、以及通信与计算的完美重叠。
在异构部署场景中,Step-3的优势更为明显。采用H800+L20的混合配置时,其解码成本较全H800配置降低42%,而性能仅下降18%;相比之下,DeepSeek-V3在相同的混合配置下,成本降低35%但性能下降42%,Qwen3的成本降低28%而性能下降31%。这种低成本高韧性的部署能力,使其在资源受限环境中具有独特优势。
quantization(量化)和MTP(多token预测)等优化技术的结合进一步提升了Step-3的效率。采用FP8量化后,其内存带宽需求降低50%,在H20上的吞吐量提升40%;启用MTP(每次预测4个token)后,长上下文场景的吞吐量再提升60%,而精度损失控制在2%以内。这些技术的协同应用,使Step-3在实际部署中能够根据场景需求灵活调整性能与成本的平衡点。
在实际业务场景中,Step-3的效率优势直接转化为商业价值。在代码生成服务中,其每小时可处理的请求量是DeepSeek-V3的1.6倍,而成本降低30%;在医疗文献分析场景中,处理相同数量的16K长文本,Step-3的硬件投入仅为Qwen3 MoE的55%;在智能客服系统中,其长对话处理能力使响应延迟降低40%,同时运营成本下降25%。
值得注意的是,Step-3的高性能并非以牺牲模型质量为代价。在标准 benchmarks 中,其MMLU得分达到78.5%,与DeepSeek-V3持平;在HumanEval代码生成任务中,pass@1指标达到65.2%,略高于Qwen3 MoE的63.8%。这种"既快又好"的特性使其在实际应用中具有不可替代的优势。
结语
Step 3模型的发布不仅是阶跃星辰技术发展的重要里程碑,更是中国AI产业迈向全球领先地位的关键一步。
通过对这一标杆性模型的深入解读,我们清晰地看到,当代AI技术的发展已从单纯的参数竞赛转向更注重实际应用价值的综合能力提升。Step 3在多模态推理、国产芯片适配和推理效率优化等方面取得的突破性进展,为AI技术的大规模商业化落地提供了切实可行的解决方案。
展望未来,随着"模芯生态创新联盟"的持续深化和开源社区的蓬勃发展,我们有理由相信,Step 3所代表的技术路线将推动AI应用进入一个更加普惠、高效的新阶段。阶跃星辰展现出的技术创新能力与产业生态构建意识,为中国AI企业在全球竞争中开辟了一条独具特色的发展道路。
大模型之心Tech知识星球交流社区
我们创建了一个全新的学习社区 —— “大模型之心Tech”知识星球,希望能够帮你把复杂的东西拆开,揉碎,整合,帮你快速打通从0到1的技术路径。
星球内容包含:每日大模型相关论文/技术报告更新、分类汇总(开源repo、大模型预训练、后训练、知识蒸馏、量化、推理模型、MoE、强化学习、RAG、提示工程等多个版块)、科研/办公助手、AI创作工具/产品测评、升学&求职&岗位推荐,等等。
星球成员平均每天花费不到0.3元,加入后3天内不满意可随时退款,欢迎扫码加入一起学习一起卷!

 扫码添加微信
扫码添加微信








