


ERMV框架:针对操作任务的数据增强,显著提升VLA模型跨场景成功率
- 2025-07-29 08:00:00

点击下方卡片,关注“具身智能之心”公众号
作者丨Chang Nie等
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
研究背景
机器人模仿学习高度依赖4D多视图序列图像(包含多视角、时间维度的图像),但高质量数据收集成本高、数量稀缺,严重限制了视觉-语言-动作(VLA)等具身智能策略的泛化与应用。数据增强是缓解数据稀缺的有效手段,但目前缺乏针对操作任务的4D多视图序列图像编辑方法。
现有方法存在明显的局限:传统数据增强方法(如CACTI、ROSIE)仅针对单张静态图像编辑,无法满足VLA模型对时空连续4D数据的需求;多视图编辑方法依赖固定相机位置,难以处理机器人操作中动态变化的多相机系统;视频生成模型因密集时空注意力机制,受限于计算成本,工作窗口小,且难以处理长序列中的误差累积。
核心挑战与解决方案
ERMV(Editing Robotic Multi-View 4D data)是一种新型数据增强框架,基于单帧编辑和机器人状态条件,高效编辑整个多视图序列。其核心是解决三个挑战:动态视图和长时间范围内的几何与外观一致性、低计算成本下扩大工作窗口、确保机器人手臂等关键对象的语义完整性。
视觉引导条件(Visual Guidance Condition)
文本提示在机器人图像编辑中存在歧义(如“将背景改为办公室”无法准确定义细节),难以满足物理场景的精细几何和空间控制需求。ERMV采用视觉引导策略:选择全局信息丰富的帧(通常是主相机第一帧),通过图像修复或手动编辑生成目标引导图像,作为明确的视觉蓝图。该图像经CLIP编码器处理为嵌入向量,为扩散模型提供精确的语义目标,确保编辑在所有视图和时间步中一致传播figure 2。

数学表达:
机器人与相机状态注入(Robotic and Camera State Injection)
为准确渲染机器人相机视角和时间步的场景,ERMV注入明确的状态信息作为条件,包括:
位姿与状态条件:每个目标图像对应的相机位姿()和机器人动作(); 运动动态条件:相机和机器人的时间变化量(、),用于真实渲染运动模糊。
这些状态经MLP和位置编码处理后,作为条件输入网络:
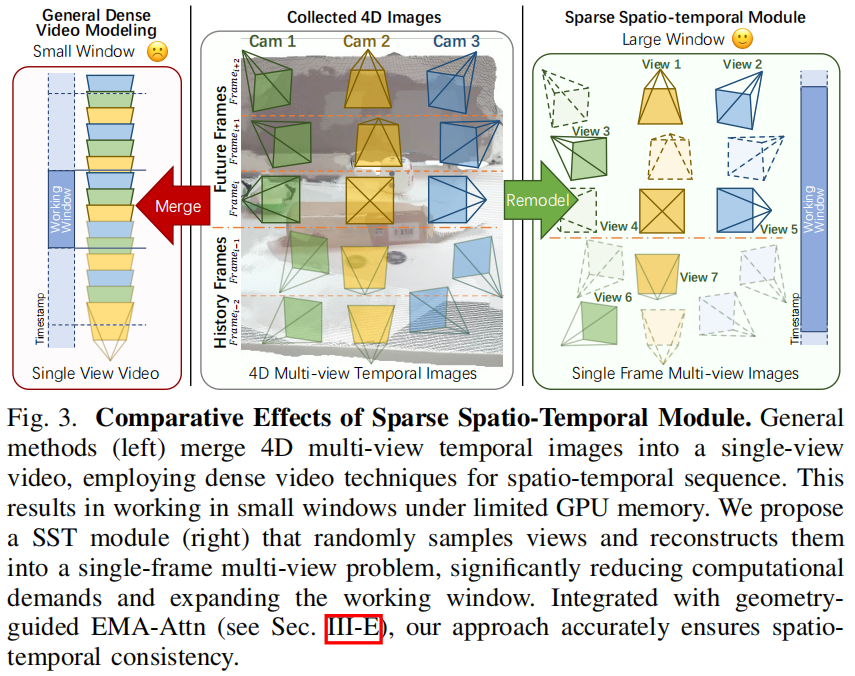
稀疏时空模块(Sparse Spatio-Temporal Module, SST)
传统方法处理4D数据时,需处理所有图像(为时间步,为视图数),计算成本高。SST模块通过稀疏采样,将长序列问题重构为单帧多视图问题:在个连续时间步的滑动窗口中,随机采样张图像(),保留其原始时间和视图索引作为条件,使模型在固定计算预算下处理更宽的时间范围figure 3。
通过建模联合概率分布:
学习稀疏帧集的特征,大幅降低计算需求,同时保证时空一致性。
极线运动感知注意力(Epipolar Motion-Aware Attention, EMA-Attn)
稀疏采样带来新挑战:如何在稀疏帧间传播信息并保证几何一致性。传统极线约束因运动模糊(相机和物体移动导致)失效,难以建立准确特征对应。EMA-Attn通过学习运动诱导的像素偏移,适应动态场景:
先预测运动偏移量:基于局部图像特征和运动条件,通过小型网络预测像素偏移(); 沿偏移极线聚合特征:在修正后的极线上采样点,通过注意力机制聚合多视图特征,确保动态场景中鲁棒的跨视图对应figure 4、figure 5。


注意力计算:
反馈干预机制(Feedback Intervention Mechanism)
自回归模型在长序列编辑中易因误差累积导致核心对象质量下降。ERMV引入反馈干预机制:
用多模态大语言模型(MLLM)作为自动检查器,基于思维链(CoT)提示,对比原始图像和生成图像,检查关键对象一致性table I; 若不一致,请求专家提供核心对象的分割掩码,作为额外条件进行修正生成,仅在模型出错时介入,最小化专家标注负担figure 6。

数学表达:
扩散模型基础(Diffusion Model Foundation)
ERMV基于潜在扩散模型(LDM),在潜在空间中进行扩散过程:编码器将图像映射为潜在表示(),前向过程添加高斯噪声生成含噪潜在变量(),模型训练目标是预测添加的噪声。
损失函数:
实验验证
ERMV在仿真环境、真实世界数据集和物理机器人平台上的实验均显示出显著效果。
仿真环境实验(RoboTwin平台)
编辑效果:ERMV在SSIM、PSNR、LPIPS等指标上大幅优于单帧编辑方法Step1XEdit,体现出优异的时空一致性table II;

下游VLA模型性能:用ERMV增强的数据训练的RDT和Diffusion Policy(DP)模型,在原始场景和未知杂乱场景中的成功率均显著高于基线和Step1XEdit增强模型,验证了ERMV生成数据的有效性table III、table IV。


真实世界实验
真实数据集(RDT-ft-data):ERMV能成功编辑真实机器人操作序列(如替换背景),准确保留核心对象(如抓取的盒子、机器人手臂)的形态和运动,甚至复现运动模糊效果figure 8;

物理机器人平台(双Franka Emika Panda机械臂):ERMV增强数据训练的ACT模型,在原始场景和未知杂乱场景中成功率大幅提升(平均成功率从0.52提升至0.91,未知场景从0.02提升至0.89),证明其在真实世界的鲁棒性table V。

扩展能力
世界模型(World Model):基于单帧初始图像和动作序列,ERMV可预测生成对应的多视图时空图像序列,作为低成本策略验证工具figure 11;

弥合sim-to-real差距:将仿真图像编辑为真实风格,生成“伪真实”4D轨迹,训练的模型可直接在真实场景中完成任务,减少对高保真物理仿真的依赖figure 12。

消融实验
运动条件:移除运动动态条件和EMA-Attn后,模型无法生成真实运动模糊,验证了运动信息注入的必要性figure 13;

稀疏时空模块(SST):相比密集采样,SST在相同计算资源下扩大工作窗口,提升模型性能,且减少50%GPU内存需求table VI;

反馈干预机制:禁用该机制后,长序列编辑出现质量下降和语义偏移,而ERMV能维持高质量输出,证明其在抑制误差累积中的作用figure 14。

参考
[1]ERMV: Editing 4D Robotic Multi-view images to enhance embodied agents

 扫码添加微信
扫码添加微信

- 点赞 (0)
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊







