


关于矩阵扩展,RISC-V社区提出了四种方案
- 2025-07-26 09:10:00
当前,AI模型的核心需求集中在两点:一是高效处理小型、多样化的数据类型(如从FP32到BF16的精度压缩),二是管理海量参数所需的内存带宽。这种需求组合要求处理器既能支持通用计算,又能灵活适配AI特有的矩阵运算。

SiFive联合创始人、首席架构师Krste Asanovic
“RISC-V的基因是通用性,它并非为AI专属设计,但正是这种开放性,使其成为AI与通用计算融合的最佳载体。”在2025年RISC-V中国峰会人工智能分论坛上,SiFive联合创始人、首席架构师Krste Asanovic深入剖析了RISC-V架构在AI领域的演进路径,揭示了从向量扩展(RVV)到矩阵扩展的技术选择与挑战,不仅展现了RISC-V的灵活性,更折射出异构计算时代架构设计的深层逻辑。
向量扩展是AI计算的“隐形基石”
作为RISC-V生态的关键组件,向量扩展(RVV 1.0)自批准以来,已经被视为支撑AI计算的底层支柱。
Krste解释,尽管矩阵计算(MatMul)近年备受瞩目,但AI算法中的许多关键步骤(如激活函数、归一化)仍依赖向量运算。例如,RVV通过LMUL机制支持多种数据类型(如INT8、FP16)的混合精度操作、可扩展的向量长度(最高达每寄存器16Kb)以及宽度扩展(widening)和压缩(narrowing)运算,显著提升了AI推理和训练的效率。
目前,RVV已集成至主流编译器,并支持INT8/16/32/64及FP16/32/64等数据类型,未来还将通过Zvfbfa、Zvfofp8min等提案扩展对新兴格式的支持。
矩阵扩展:四条路径的博弈
面对AI对矩阵运算的爆发式需求,RISC-V社区提出了四种矩阵扩展方案,形成技术路线分野:
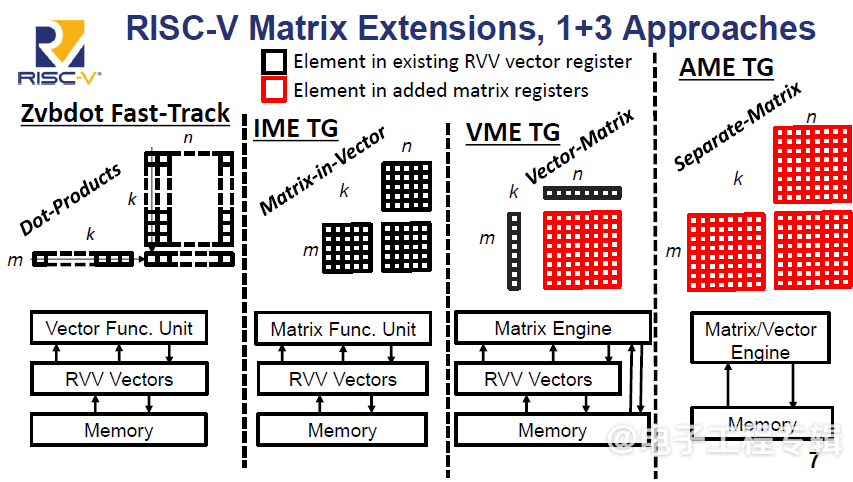
批次点积(Zvbdot):作为快速通道方案,该扩展无需新增状态,利用现有向量寄存器完成8个点积运算,适合小规模向量长度场景,预计最快实现标准化。

向量中的矩阵(IME TG):通过将向量寄存器视为矩阵分块,支持外积形式的矩阵乘法,适用于长向量长度场景,设计空间较大,需时间收敛。

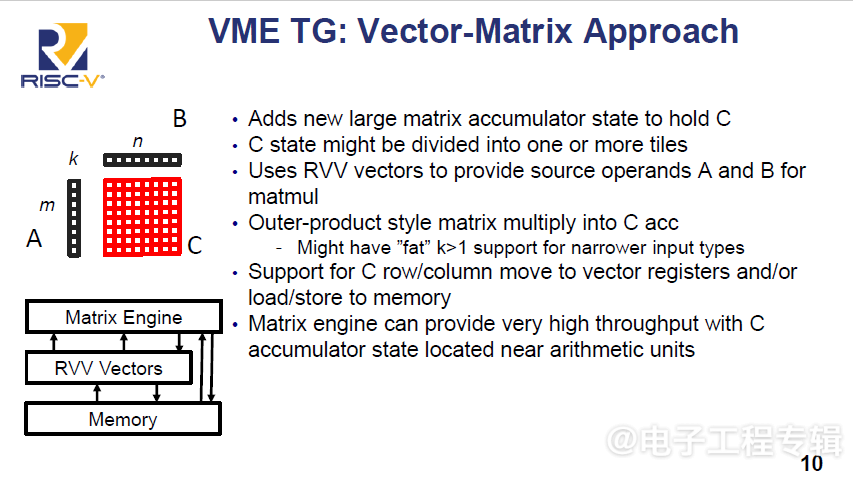
向量-矩阵(VME TG):新增矩阵累加器状态,结合RVV向量源操作数,提供高吞吐量矩阵运算,同时维护向量ISA的兼容性,被视为平衡性能与实现难度的中间方案。
独立矩阵引擎(AME TG):完全解耦矩阵与向量设计,理论上可实现最高性能,但需重新定义指令集与软件栈,设计复杂度最高,标准化进程最慢。

Krste坦言:“分离矩阵方案虽具潜力,但需平衡设计自由度与生态碎片化风险。当前更务实的选择是优先完善‘向量矩阵’路径,逐步融合其他方案。” 例如,Zvbdot因简单高效,可能率先落地;而独立矩阵引擎虽潜力巨大,但需解决大规模软件移植难题。
标准化挑战与未来展望
RISC-V矩阵扩展的标准化进程仍处博弈阶段。尽管RVV已获编译器生态支持,但矩阵指令的多样性导致软件适配成本高企。
Krste呼吁:“我们需在性能与创新速度间找到平衡——既不能因过度标准化扼杀创新,也不能任由生态分裂。”他透露,RISC-V国际基金会正推动“快速通道”提案(如Zvbdot),以加速关键指令的落地。

在AI架构的军备竞赛中,RISC-V选择了一条“通用底座+灵活扩展”的中间路线。正如Krste所言:“真正的创新不在于创造专用硬件,而在于构建一个能容纳所有可能性的框架。”这一理念,或许正是RISC-V在AI时代破局的关键。

 扫码添加微信
扫码添加微信

- 点赞 (0)
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊







