


Altman 秀新模型“翻车”,谷歌补刀躺赢!OpenAI 前员工爆肝3天,编程再赢老东家模型!
- 2025-07-22 17:37:00

近期, OpenAI 接连在多个场合携不同新模型“上桌”,且这些模型均还未公开发布。上周,OpenAI 分别曝出了两款与 o3 有关联但都未公开过的新模型。其中,一款被疑是“伪装的 GPT-5”,另一款则在一场 AI 模型和人类选手都参与的编程世界锦标赛中拿到了第二名的成绩。
最新上场的是,一款 OpenAI 宣称“在国际数学奥林匹克竞赛(IMO)中取得了金牌级别成绩”的模型。每年参加国际数学奥林匹克竞赛(IMO)的学生,都是全球范围内极具天赋的年轻数学才俊。今年,他们迎来了一批实力更强的 AI 模型的挑战。刚刚,谷歌 DeepMind 联合创始人兼 CEO Demis Hassabis 亦宣布,Gemini Deep Think 在 IMO 中达到了金牌水平。
然而,虽然都宣布拿到金牌的成绩,但评价风向却差不少。不少网友认为:“OpenAI 为了博眼球啥都干得出来。没官方分数,没点耐心,更没底线。”“谷歌 DeepMind 的表现堪称典范,非常钦佩。”
“进步惊人”,用 Hassabis 的话来说。谷歌表示,其经过专门优化的数学人工智能在六道题目中答对了五道。在此之前,谷歌曾于 2024 年 7 月宣称,其 AlphaProof 和 AlphaGeometry 2 模型在 IMO 中取得了相当于银牌的成绩——不过谷歌的系统解决每个问题需要长达三天时间,而非人类的 4.5 小时限制,且需要人类协助将题目转化为正式的数学语言。
然而,就在前几天,OpenAI 研究员 Alexander Wei 就抢先宣布,该公司正在研发的一款新 AI 模型在 IMO 中取得了金牌级别的成绩,达到了每年仅有不到 9% 的人类参赛者能企及的水平。这款实验性 AI 模型的研究团队由 Alexander Wei 领衔,并有 Sheryl Hsu 和 Noam Brown 提供支持。
据悉,该模型在解决竞赛中的六道证明类题目时,遵循了与人类参赛者相同的限制条件:每场考试时长 4.5 小时,不允许使用互联网或计算器。OpenAI 称,这一成就与以往 AI 在数学奥林匹克题目上的尝试有所不同——以往的尝试依赖于专门的定理证明系统,且往往会超出人类的时间限制。该公司表示,其模型将题目作为纯文本处理,并生成自然语言证明,运作方式类似标准语言模型,而非专门构建的数学系统。
另外,OpenAI 起初并未计划参与这项竞赛,而是在测试中观察到令人欣喜的结果后,才决定对自身研究成果进行评估。据了解,国际数学奥林匹克竞赛主办方新出的题目会同时分享给多家 AI 公司,OpenAI 也收到了这些题目。为验证结果,每一份解题方案都由 OpenAI 组织的三位前国际数学奥林匹克竞赛奖牌得主组成的评审团进行盲审,且只有达成一致意见才算通过。
尽管国际数学奥林匹克竞赛主办方曾要求人工智能公司推迟至 7 月 28 日再公布结果,但 OpenAI 还是发布了这一消息。然而,几位了解该过程的内部人士表示,由于 OpenAI 是自行对其在国际数学奥林匹克竞赛中的成绩进行评分的,该公司这一说法的合法性可能存在疑问。OpenAI 计划公布相关证明过程和评分标准,供公众审阅。
据领导 DeepMind 超级推理团队的 Thang Luong 介绍,IMO 主办方有一套官方评分标准,但未对外公开。若未依据该标准进行评估,任何奖牌归属的宣称都站不住脚。“扣掉一分后,它就得是银牌,而非金牌。”
另外,除了对自动评分结果存在争议外,OpenAI 还因其提前宣布获奖情况,似乎违反了与国际数学奥林匹克竞赛的保密协议而惹恼了 IMO 社群。
一家同样参与竞赛的 AI 公司 Harmonic 在 7 月 20 日的 X 帖子中透露:“IMO 董事会已要求我们,连同其他参与竞赛的主要 AI 公司,暂缓发布我们的结果,直到 7 月 28 日。”Hassabis 也在社交媒体上侧面抨击 OpenAI 过早宣布金牌的行为:“我们尊重国际数学奥林匹克委员会最初的请求,即所有人工智能实验室只有在官方结果经过独立专家验证且学生应得的赞誉得到公正对待后才能分享结果。”

上周,一位网友曝出,OpenAI 正在 WebArena 上测试名为“o3-alpha-responses-2025-07-17”的新模型,该模型以“Anonymous-Chatbot”的名字出现。

Jimmy Apples 将这一新模型与 Gemini 2.5 pro 进行了网页开发的对比,使用的提示词是“制作一个神秘风格的网站”,之后评价道:“这东西很强大,太让人惊艳了。”
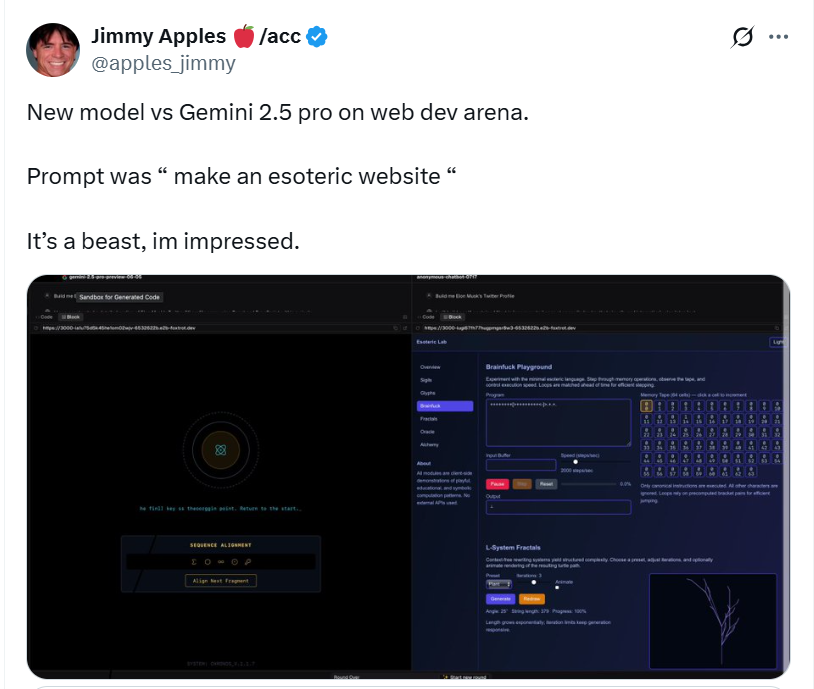
目前,“o3 Alpha”已从 Web 开发测试平台下架。据悉,它只上线了大概 5、6 个小时。上次 Quazar Alpha 在测试后不久就正式发布了,所以这个新编程模型也可能将在未来几周内亮相。
关键在于, OpenAI 内部确实有个编程能力极强的模型。OpenAI 的 CEO Sam Altman 早就有所暗示:2025 年 2 月时,他提到公司内部有个模型能排进全球编程高手前 50 名,且有望在 2025 年底推出 “超人类级” 编程模型。而现在这个模型,似乎已经非常接近这个目标了。
除 Jimmy Apples 之外,还有几位模型体验者对“o3 Alpha”给出不错的使用评价。还有人猜测:“这是否是伪装成 o3 alpha 的 GPT-5 ?”
但需要注意的是,尽管该公司已确认其下一代主要人工智能模型 GPT-5 “即将推出”,但同时也表示“相关技术将会延续,但具备这种水平能力的模型短期内不会发布。” 显然,OpenAI 为这项特定实验投入了大量计算资源(这意味着高昂的成本),而这样的计算规模在近期内不太可能出现在面向消费者的 AI 模型中。
巧合的是,上周前 OpenAI 员工 Przemysław Dębiak 在参加在东京举行的 2025 年 AtCoder 世界巡回赛总决赛启发式竞赛之时,就不仅与多名人类选手比拼了编程技能,还和一款据说出自 OpenAI、类似于 o3 的新定制化模拟推理模型一较高下,代号为“OpenAIAHC”。
在这场比赛中,参赛者被要求在 10 小时内解决一个复杂的优化问题,随后再根据他们的表现进行评分。参赛者可以使用 AtCoder 平台上提供的任何编程语言来解决该问题,但他们使用的硬件规格完全相同,且每次提交代码之间必须等待五分钟。Dębiak 以“Psyho”的名字参赛,最终得分为 1,812,272,588,909,位居排行榜榜首,击败了得分为 1,654,675,725,406 的 AI,后者获得亚军。

“我已经筋疲力尽了。我算了一下,过去三天里我只睡了 10 个小时,现在几乎是靠着一口气撑着。”Dębiak 在 X 上庆祝自己的成就,自豪地宣布“人类已经获胜(暂时!)”,但也承认比赛让他筋疲力尽。
OpenAI 则似乎对其新模型获得银牌的成绩相当满意,该公司发言人在接受采访时表示,“像 o3 这样的模型在编程 / 数学竞赛中能排进前 100 名,但据我们所知,这是首次在顶级编程 / 数学竞赛中进入前三名。像 AtCoder 这样的赛事,为我们提供了一种测试模型能力的方式——看它们能否像人类一样进行战略性推理、做长期规划,以及通过反复试错来改进解决方案。”
此次竞赛是 AI 模型首次在编程赛事中与人类程序员直接同台竞技,AI 虽未夺冠但能获得第二名,依然令人印象深刻。这对于人类编程参赛者的未来而言,或许不是个好兆头。因为尽管程序员的技能必然会不断提升,但 AI 的飞速发展很可能意味着,用不了多久,AI 模型就会在类似赛事中占据榜首。
参考链接:
https://www.pcgamer.com/software/ai/humanity-has-prevailed-for-now-says-former-openai-employee-admitting-hes-barely-alive-after-beating-one-of-its-ai-models-in-a-coding-world-championship-fight/
https://arstechnica.com/ai/2025/07/openai-jumps-gun-on-international-math-olympiad-gold-medal-announcement/
https://www.youtube.com/watch?v=BZAi9h9uCX4
声明:本文为 AI 前线整理,不代表平台观点,未经许可禁止转载。
📢 AI 能否终结游戏研发 996?
7 月 24 日 15:00-16:00,锁定这场超有料的直播,
拆解亿级玩家场景的 AI 降本增效公式,
助力提升游戏开发与运营效率!
点击【阅读原文】,立即预约!

今日荐文
万人见证,“出轨”CEO被停职;陶哲轩评“OpenAI内部实验模型获IMO金牌”;传字节Seed视觉负责人“暂休”|AI周报
烧钱换能力,老员工经验作废!一线Agent厂商、用户经验亲述:抛弃技术驱动,巨额投入如何不打水漂?
OpenAI新Agent遭中国24人初创团队碾压!实测成本、质量全输惨,海外用户:中国Agent代差领先
宅男福音!定制“二次元女友”AI 火爆,马斯克开 44 万刀抢工程师
最强人才接连被挖,创业大佬离开 OpenAI 后说了实话:7 周硬扛出 Codex,无统一路线、全靠小团队猛冲

你也「在看」吗?👇

 扫码添加微信
扫码添加微信
- 点赞 0
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊







