


一个任务50次调用,成本狂砍90%?Manus首次公开上下文工程秘诀,一堆反复重写换来的教训
- 2025-07-21 15:04:06

在 Manus 项目伊始,我和我的团队面临一个关键决策:我们是应该使用开源基础模型训练一个端到端的 Agent 模型,还是应该在前沿模型的上下文学习能力之上构建一个 Agent?
之前我还在 NLP 领域的第一个十年时,我们是没有这样的选择余裕的。在 BERT(是的,已经过去七年了)那段遥远的日子里,模型必须先进行微调并评估,然后才能转移到新任务上。这个过程通常需要每周迭代一次,尽管与今天的大型语言模型相比,当时的模型很小。对于快速进化的应用,尤其是处于产品市场契合阶段(PMF)之前的应用,这样的慢反馈循环是不可接受的。这是我上一次创业的苦涩教训,当时我从头开始训练模型,用于开放信息提取和语义搜索用例。然后 GPT-3 和 Flan-T5 出现了,我的内部模型一夜之间就落伍了。讽刺的是,这些模型标志着上下文学习时代的开始——而且开启了一条全新的前进道路。
那个来之不易的教训让我们下定决心:Manus 将押注于上下文工程。这使我们能够在几小时内而不是几周内发布改进,并且使我们的产品与底层模型保持正交:如果模型进步是潮水上涨,我们希望 Manus 是船,而不是粘在海底的柱子。
尽管如此,上下文工程实际上并非易事。它是一门实验科学——我们已经四次重建了我们的 Agent 框架,每次都是因为我们发现了塑造上下文的更好方法。我们亲切地将这种手动的架构搜索、提示调整和经验猜测过程称为“随机梯度下降”(SGD)。它并不优雅,但有效。
这篇文章分享了我们通过自己的“SGD”到达的局部最优解。如果你正在构建自己的 AI Agent,我希望这些原则能帮助你更快地收敛。
如果我只能选择一个指标,我会争辩说 KV 缓存命中率是生产阶段 AI Agent 最重要的单一指标。它直接影响延迟和成本。为了理解个中原因,我们来看一个典型 Agent 的操作方式:
在接收到用户输入后,Agent 通过一系列工具来完成任务。在每次迭代中,模型根据当前上下文从预定义的动作空间中选择一个动作,然后在环境(例如 Manus 的虚拟机沙箱)中执行该动作以产生观察结果。动作和观察结果被追加到上下文中,形成下一次迭代的输入。这个循环一直持续到任务完成。
可以想象,上下文随着每一步的进行而增长,而输出——通常是结构化的函数调用——保持相对简短。这使得 Agent 中的预填充和解码之间的比例相比聊天机器人高出很多。例如,在 Manus 中,平均输入到输出的 token 比例大约是 100:1。
还好,具有相同前缀的上下文可以利用 KV 缓存,这大大减少了生成第一个 token 的时间(TTFT)和推理成本——无论你是使用自托管模型还是调用推理 API。节约的费用可不少:例如,使用 Claude Sonnet 时,缓存的输入 token 成本为 0.30 美元 /MTok,而未缓存的 token 成本为 3 美元 /MTok——相差 10 倍。

从上下文工程的角度来看,提高 KV 缓存命中率涉及一些关键实践:
让你的提示前缀保持稳定。由于 LLM 的自回归特性,即使单个 token 的差异也可以使该 token 之后的缓存失效。一个常见的错误是在系统提示的开头包含一个时间戳——特别是精确到秒的时间戳。当然,它可以让模型告诉你当前的时间,但它也杀死了你的缓存命中率。
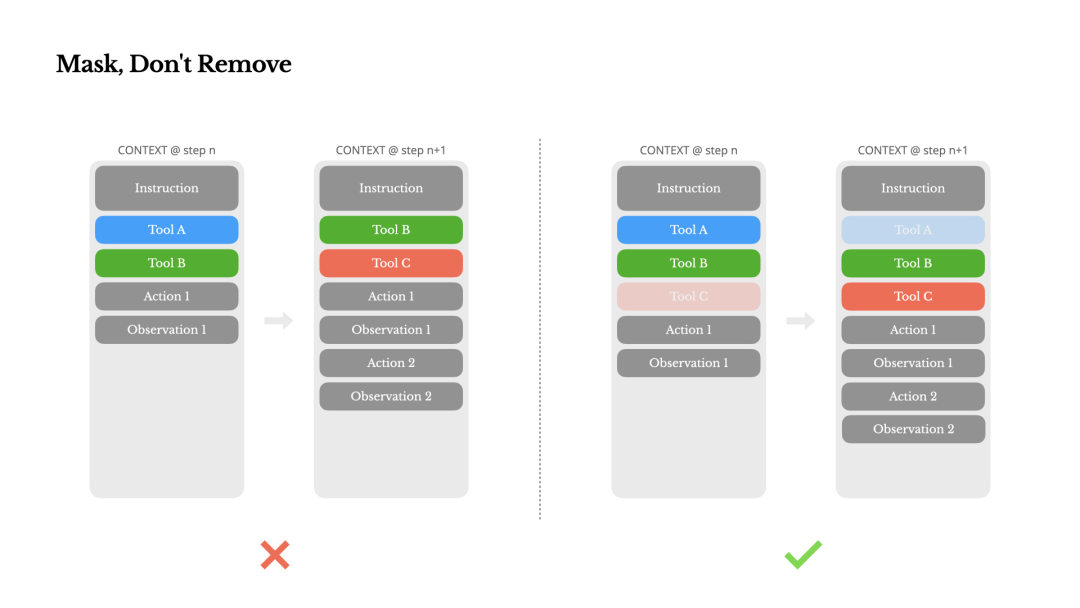
让你的上下文只追加内容。避免修改之前的行动或观察。确保你的序列化是确定性的。许多编程语言和库在序列化 JSON 对象时不保证稳定的键排序,这可能会悄无声息地破坏缓存。
在需要时明确标记缓存断点。一些模型提供商或推理框架不支持自动增量前缀缓存,而是需要在上下文中手动插入缓存断点。在分配这些时,考虑潜在的缓存过期问题,并至少确保断点包括系统提示的结束。
此外,如果你使用像 vLLM 这样的框架自托管模型,请确保启用了前缀 / 提示缓存,并使用 会话 ID 等技术在分布式工作器之间一致地路由请求。
随着你的 Agent 发展出更多能力,其动作空间自然变得更加复杂——换句话说,工具的数量激增。最近 MCP 的流行更是火上浇油。如果你允许用户配置工具,相信我:有人会不可避免地将数百个神秘的工具插入到你精心策划的动作空间中。结果,模型更有可能选择错误的行动或采取低效的路径。简而言之,你全副武装的 Agent 变得更笨了。
一个自然的反应是设计一个动态的动作空间——可能是按需加载工具,使用类似 RAG 的东西。我们在 Manus 中也尝试过。但我们的实验表明了一个明确的规则:除非绝对必要,否则避免在迭代过程中动态添加或移除工具。主要有两个原因:
在大多数大型语言模型中,工具定义位于上下文的前端,通常在系统提示之前或之后。因此,任何更改都会使所有后续动作和观察的 KV 缓存失效。
当之前的行动和观察仍然引用当前上下文中不再定义的工具时,模型会感到困惑。如果没有约束解码,这通常会导致模式违规或幻觉动作。
为了在不修改工具定义的情况下解决这个问题并改进动作选择,Manus 使用了一个上下文感知的状态机来管理工具的可用性。它不是移除工具,而是在解码过程中屏蔽 token 的对数,以防止(或强制)根据当前上下文选择某些动作。
在实践中,大多数模型提供商和推理框架都支持某种形式的响应预填充,这允许你在不修改工具定义的情况下限制动作空间。通常有三种函数调用模式(我们将以 NousResearch 的 Hermes 格式为例):
自动 - 模型可以选择调用函数或不调用。通过仅预填充回复前缀实现: <|im_start|>assistant
必需 - 模型必须调用函数,但选择不受限制。通过预填充到工具调用 token 实现: <|im_start|>assistant<tool_call>
指定 - 模型必须从特定子集中调用函数。通过预填充到函数名称的开头实现: <|im_start|>assistant<tool_call>{"name": “browser_
使用这种方法,我们通过直接屏蔽 token 的对数来限制动作选择。例如,当用户提供新输入时,Manus 必须立即回复而不是执行一个动作。我们还故意设计了具有一致前缀的动作名称——例如,所有与浏览器相关的工具都以 browser_ 开头,命令行工具以 shell_ 开头。这使我们能够轻松地强制 Agent 在给定状态下仅从特定的工具组中选择,而不需要使用有状态的对数处理器。
这些设计有助于确保 Manus Agent 循环即使在模型驱动的架构下也能保持稳定。
现代前沿的大型语言模型现在提供 128K token 或更多的上下文窗口。但在现实世界的 Agent 场景中,这往往是不够的,有时甚至是一种负担。有三个常见的痛点:
观察结果可能非常大,特别是当 Agent 与像网页或 PDF 这样的非结构化数据交互时。很容易超过上下文限制。
模型性能往往会在某个上下文长度之后下降,即使技术上上下文窗口可以支持这么大的长度。
长输入很贵,即使有前缀缓存。你仍然需要支付传输和预填充每个 token 的费用。
为了解决这个问题,许多 Agent 系统实现了上下文截断或压缩策略。但过于激进的压缩不可避免地会导致信息丢失。问题直达根本:Agent 本质上必须根据所有先前的状态预测下一个动作——你 不能 可靠地预测哪个观察结果可能在十步之后变得关键。从逻辑上讲,任何不可逆的压缩都带有风险。
这就是为什么我们在 Manus 中将 文件系统视为最终的上下文:大小无限,本质上持久,并且可以直接由 Agent 本身操作。模型学会按需写入和读取文件——不仅将文件系统用作存储,而且作为结构化的、外部化的记忆。
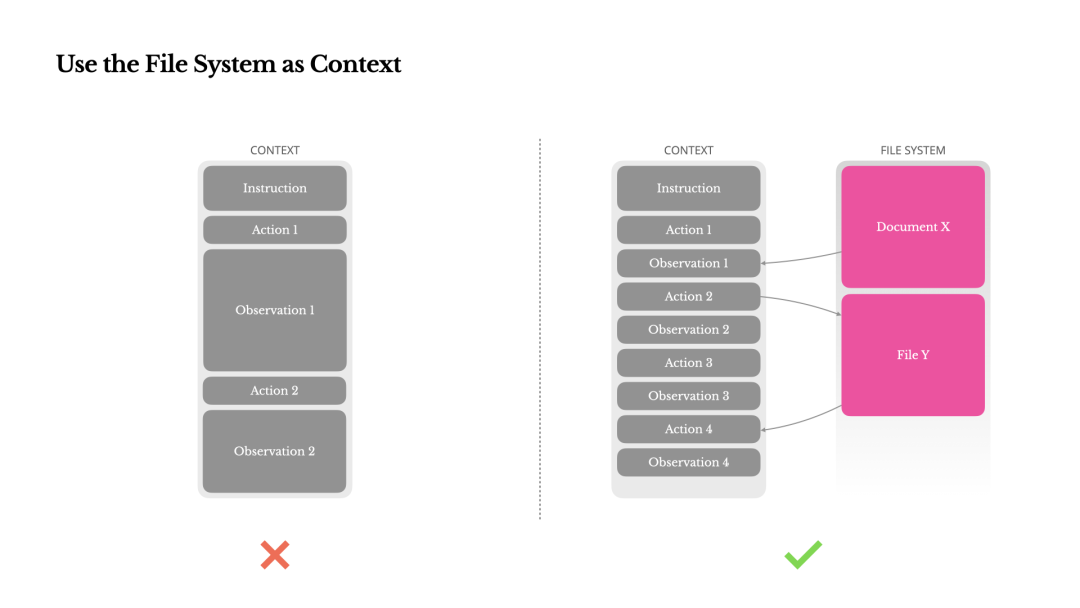
我们的压缩策略总是设计成可恢复的。例如,只要保留 URL,就可以从上下文中删除网页的内容,如果文档的路径在沙箱中仍然可用,就可以省略文档的内容。这允许 Manus 在不永久丢失信息的情况下缩短上下文长度。
在开发这个功能时,我发现自己想象着一个 状态空间模型(SSM)在 Agent 环境中有效工作需要做到哪些事情。与 Transformer 不同,SSM 缺乏完全的注意力,并且难以处理长距离的后向依赖。但如果它们能够掌握基于文件的记忆——将长期状态外部化而不是在上下文中持有——那么它们的速度和效率可能会解锁一类新的 Agent。AgentSSM 可能是神经图灵机的真正继承者。
如果你使用过 Manus,你可能已经注意到了一些奇怪的事情:在处理复杂任务时,它倾向于创建一个 todo.md 文件——并在任务进展时逐步更新它,勾选已完成的项目。
这不仅仅是某种可爱的行为——它是一种故意的,用来操纵注意力的机制。
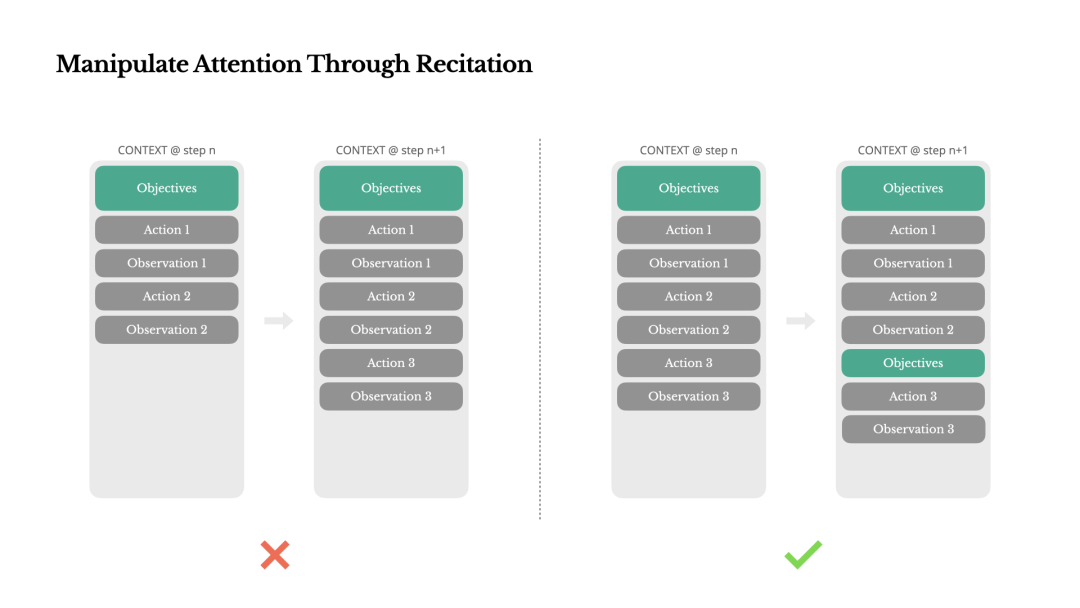
在 Manus 中,一个典型的任务平均需要大约 50 次工具调用。这是一个漫长的循环——由于 Manus 依赖大型语言模型进行决策,它容易偏离主题或忘记早期目标,特别是在长篇的上下文或复杂的任务中。
通过不断地重写待办事项列表,Manus 将其目标背诵到上下文的末尾。这会将全局计划推入模型的近期注意力范围,避免了“迷失在半道”的问题,并减少了目标错位。实际上,它正在使用自然语言来引导自己的焦点朝向任务目标——而无需特殊的架构变化。
Agent 会犯错误。这不是一个错误——这是现实。语言模型会产生幻觉,环境会返回错误,外部工具会行为失常,意外边缘情况随时都会出现。在多步骤任务中,失败不是例外;它是循环的一部分。
然而,一个常见的冲动是隐藏这些错误:清理痕迹,重试动作,或重置模型的状态并将其留给神奇的“温度”。这感觉更安全,更有控制感。但它有代价:没有证据,模型就无法适应。
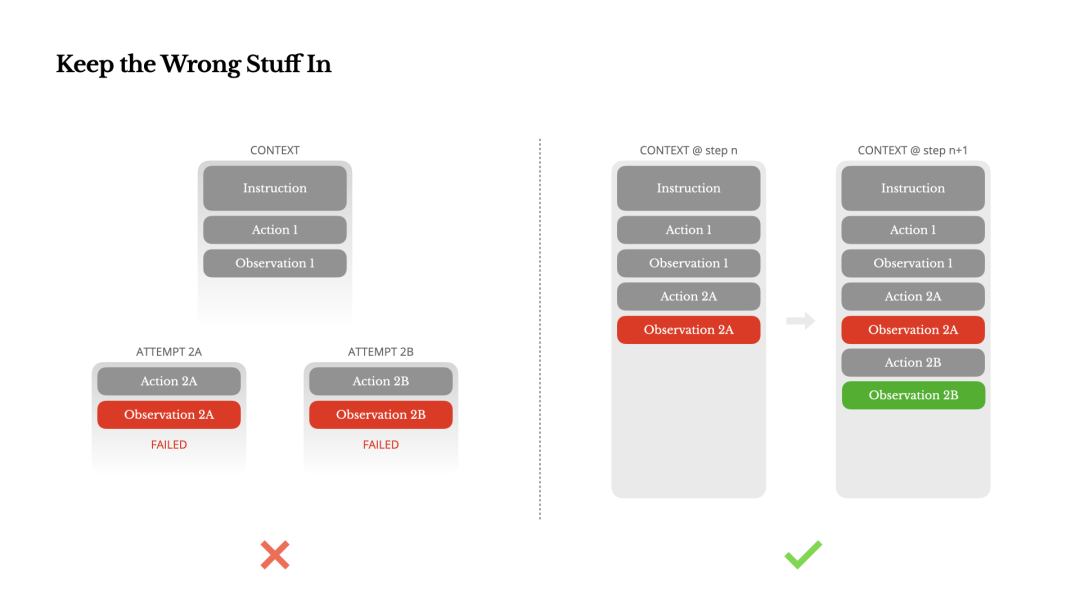
在我们的经验中,改进 Agent 行为最有效的一种方法出奇地简单:在上下文中保留错误的回合。当模型看到一个失败的动作——以及由此产生的观察或堆栈跟踪——它隐式地更新其内部信念。这样它就能提前避开类似的动作,减少了重复相同错误的机率。
事实上,我们认为错误恢复是真正的 Agent 行为最清晰的指标之一。然而,它在大多数学术工作和公共基准中仍然被低估,这些工作通常关注在理想条件下的任务成功率。
少样本提示是改进 LLM 输出的常用技术。但在 Agent 系统中,它可能会以微妙的方式适得其反。
语言模型是出色的模仿者;它们 模仿上下文中的行为模式。如果你的上下文充满了类似的过去动作 - 观察对,模型将倾向于遵循这种模式,即使它不再是最优的。
这在涉及重复决策或动作的任务中可能是危险的。例如,当使用 Manus 帮助审查一批 20 份简历时,Agent 经常陷入一种节奏——仅仅因为上下文中看到了类似动作,就重复类似的动作。这导致了漂移、过度泛化,有时甚至产生幻觉。

解决方案是增加多样性。Manus 在动作和观察中引入少量的结构化变化——不同的序列化模板、交替的措辞、顺序或格式中的小噪声。这种受控的随机性有助于打破模式并调整模型的注意力。
换句话说,不要让自己陷入少样本的困境。你的上下文越统一,你的 Agent 就越脆弱。
上下文工程仍是一个新兴的领域——但对于 Agent 系统来说,它已经变得至关重要。模型可能变得更强大、更快、更便宜,但任何原始能力都无法取代对记忆、环境和反馈的需求。你塑造上下文的方式最终定义了你的 Agent 行为:它运行的速度、恢复的能力以及扩展的范围。
在 Manus,我们通过重复重写、死胡同和数百万用户的现实世界测试学到了这些教训。我们在这里分享的都不是普遍真理——但这些是我们成功的模式。如果它们能帮助你避免哪怕是一次痛苦的迭代,那么这篇文章就完成了它的任务。
Agent 的未来将一次构建一个上下文。好好设计它们。
原文链接:
https://manus.im/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-Manus
首届 AICon 全球人工智能开发与应用大会(深圳站)将于 8 月 22-23 日正式举行!本次大会以 “探索 AI 应用边界” 为主题,聚焦 Agent、多模态、AI 产品设计等热门方向,围绕企业如何通过大模型降低成本、提升经营效率的实际应用案例,邀请来自头部企业、大厂以及明星创业公司的专家,带来一线的大模型实践经验和前沿洞察。一起探索 AI 应用的更多可能,发掘 AI 驱动业务增长的新路径!

今日荐文
万人见证,“出轨”CEO被停职;陶哲轩评“OpenAI内部实验模型获IMO金牌”;传字节Seed视觉负责人“暂休”|AI周报
烧钱换能力,老员工经验作废!一线Agent厂商、用户经验亲述:抛弃技术驱动,巨额投入如何不打水漂?
OpenAI新Agent遭中国24人初创团队碾压!实测成本、质量全输惨,海外用户:中国Agent代差领先
宅男福音!定制“二次元女友”AI 火爆,马斯克开 44 万刀抢工程师
最强人才接连被挖,创业大佬离开 OpenAI 后说了实话:7 周硬扛出 Codex,无统一路线、全靠小团队猛冲

你也「在看」吗?👇
 扫码添加微信
扫码添加微信
- 点赞 0
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊





