GPU市场分析、竞争格局和产业链
- 2025-07-21 17:49:00
 关注公众号,点击公众号主页右上角“ · · · ”,设置星标,实时关注旺材芯片最新资讯
关注公众号,点击公众号主页右上角“ · · · ”,设置星标,实时关注旺材芯片最新资讯
一、行业概述
1、GPU定义
GPU一般指图形处理器(graphics processing unit,缩写GPU),又称显示核心、视觉处理器、显示芯片,是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上做图像和图形相关运算工作的微处理器。
GPU是显卡的处理器。显卡全称显示适配卡,又称显示适配器,用于协助CPU进行图像处理,作用是将CPU送来的图像信号经过处理再输送到显示器上,由主板连接设备、监视器连接设备、处理器和内存组成,GPU即是显卡处理器。

2、GPU在并行运算层面具备一定优势
当前主要兴起的计算芯片分别为GPU、ASIC、FPGA等,其中GPU最初专用于图形处理制作,后逐渐应用于计算。GPU的工作通俗的来说就是完成3D图形的生成,将图形映射到相应的像素点上,对每个像素进行计算确定最终颜色并完成输出,一般分为顶点处理、光栅化计算、纹理贴图、像素处理、输出五个步骤。

GPU内部大量的运算单元核心,尽管单个核心缓存较小,逻辑功能简单,仅能执行有限类型的逻辑运算操作,但其多核心架构天然适合执行复杂的数学和几何计算,且科学计算领域通用性较高,相比CPU,综合性能更好。当前缺点在于功耗过高,效率不足。

3、GPU按应用端细分
GPU按应用端划分为PCGPU、服务器GPU、智能驾驶GPU、移动端GPU。
PCGPU可以进一步划分为独立显卡和集成显卡。独立显卡是一种与处理器(CPU)分离的GPU,具备的专用内存,不与CPU共享,拥有自己的内存源和电源,因此性能更高,功率更大,产生热量更多。集成显卡是一种内置于处理器的GPU。集成GPU使用与CPU共享系统内存,由于集成显卡内置于处理器中,性能较低,因此通常功耗更低,产生的热量更少。

服务器GPU通常应用在深度学习、科学计算、视频编解码等多种场景,主要的厂商包括英伟达和AMD,英伟达占主导地位。
自动驾驶GPU通常用于自动驾驶算法的车端AI推理,英伟达占据主导地位。
4、GPU的核心功能
(1)图形渲染
GPU凭借其较强的并行计算能力,已经成为个人电脑中图像渲染的专用处理器。图形渲染具体实现要通过五阶段:顶点着色、形状装配、光栅化、纹理填充着色、测试与混合。

(2)通用计算
2003年,GPGPU(General Purpose computing on GPU,基于GPU的通用计算)的概念首次被提出,意指利用GPU的计算能力在非图形处理领域进行更通用、更广泛的科学计算。
GPGPU在数据中心被广泛地应用在人工智能和高性能计算、数据分析等领域。GPGPU的并行处理结构非常适合人工智能计算,人工智能计算精度需求往往不高,INT8、FP16、FP32往往可以满足大部分人工智能计算。GPGPU同时可以提供FP64的高精度计算,使得GPGPU适合信号处理、三维医学成像、雷达成像等高性能计算场景。

5、GPU中常见的数据格式和应用场景
计算机中常用的数据格式包括定点表示和浮点表示。定点表示中小数点位置固定不变,数值范围相对有限,GPU中常用的定点表示有INT8和INT16,多用于深度学习的推理过程。浮点表示中包括符号位、阶码部分、尾数部分。符号位决定数值正负,阶码部分决定数值表示范围,尾数部分决定数值表示精度。FP64(双精度)、FP32(单精度)、FP16(半精度)的数值表示范围和表示精度依次下降,运算效率依次提升。
除此以外还有TF32、BF16等其他浮点表示,保留了阶码部分但是截断了尾数部分,牺牲数值精度换取较大的数值表示范围,同时获得运算效率的提升,在深度学习中得到广泛应用。

6、应用程序接口是GPU和应用软件的连接桥梁
GPU应用程序接口(API):API是连接GPU硬件与应用程序的编程接口,有利于高效执行图形的顶点处理、像素着色等渲染功能。早期由于缺乏通用接口标准,只能针对特定平台的特定硬件编程,工作量极大。随着API的诞生以及系统优化的深入,GPU的API可以直接统筹管理高级语言、显卡驱动及底层的汇编语言,提高开发过程的效率和灵活性。

7、CUDA架构实现了GPU并行计算的通用化
GPGPU相比于CPU,其并行计算能力更强,但是通用灵活性相对较差,编程难度相对较高。在CUDA出现之前,需要将并行计算映射到图形API中从而在GPU中完成计算。
CUDA大幅降低GPGPU并行计算的编程难度,实现GPU的通用化。CUDA是英伟达2007年推出的适用于并行计算的统一计算设备架构,该架构可以利用GPU来解决商业、工业以及科学方面的复杂计算问题。

CUDA采用了一种全新的计算体系结构来调动GPU提供的硬件资源,本质上是应用程序和GPU硬件资源之间的接口。CUDA程序组成包括CUDA库、应用程序编程接口(API)及运行库(Runtime)、高级别的通用数学库。
CUDA提供了对其它编程语言的支持,如C/C++,Python,Fortran等语言。CUDA支持Windows、Linux、Mac各类操作系统。

2010年英伟达发布了全新GPU架构Fermi,其是支持CUDA的第三代GPU架构(第一代与第二代分别是G80架构与GT200架构)。随后在2012、2014年陆续发布的Kepler架构、Maxwell架构中,尽管英伟达并未在硬件层面对AI计算做特定优化,但在软件层面却引入了深度神经网络加速库cuDNN v1.0,使英伟达GPU的AI计算性能与易用性得到提升。
Pascal架构发布,AI计算专精版本到来:Pascal架构在2016年3月被推出,是英伟达面向AI计算场景发布的第一版架构。
8、细分场景不断追赶,GPU迎来高速发展期
继Pascal架构后,面对Google TPU在AI计算层面带来的压力,英伟达先后更新了Volta(2017)、Turing(2018)、Ampere(2020)架构。AI计算领域的技术代差在Volta架构通过引入第一代Tensor Core在训练场景进行了拉平,随后Turing架构的第二代Tensor Core在推理场景上进行了拉平,直到Ampere时代,NV才算再次巩固了自己在AI计算领域的龙头地位。双方激烈竞争下,GPU迎来高速发展期。

二、影响GPU性能的关键因素
1、微架构设计是GPU性能提升的关键所在
评估GPU物理性能的参数主要包括:微架构、制程、图形处理器数量、流处理器数量、显存容量/位宽/带宽/频率、核心频率。其中微架构设计是GPU性能提升的关键所在。
GPU微架构(MicroArchitecture)是兼容特定指令集的物理电路构成,由流处理器、纹理映射单元、光栅化处理单元、光线追踪核心、张量核心、缓存等部件共同组成。图形渲染过程中的图形函数主要用于绘制各种图形及像素、实现光影处理、3D坐标变换等过程,期间涉及大量同类型数据(如图像矩阵)的密集、独立的数值计算,而GPU结构中众多重复的计算单元就是为适应于此类特点的数据运算而设计的。
微架构的设计对GPU性能的提升发挥着至关重要的作用,也是GPU研发过程中最关键的技术壁垒。微架构设计影响到芯片的最高频率、一定频率下的运算能力、一定工艺下的能耗水平,是芯片设计的灵魂所在。英伟达H100相比于A100,1.2倍的性能提升来自于核心数目的提升,5.2倍的性能提升来自于微架构的设计。
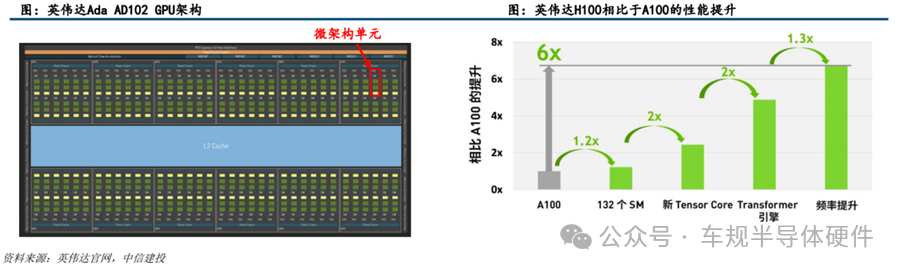
2、GPU微架构的硬件构成
流处理器:是GPU内基本运算单元,通常由整点运算部分和浮点运算部分共同组成,称为SP单元,从编程角度出发,也将其称为CUDA核心。
纹理映射单元:作为GPU中的独立部件,能够旋转、调整和扭曲位图图像(执行纹理采样),将纹理信息填充在给定3D模型上。
光栅化处理单元:依照透视关系,将整个可视空间从三维立体形态压到二维平面内。流处理器和纹理映射单元分别把渲染好的像素信息和剪裁好的纹理材质递交给处于GPU后端的光栅化处理单元,将二者混合填充为最终画面输出,此外游戏中雾化、景深、动态模糊和抗锯齿等后处理特效也是由光栅化处理单元完成的。

光线追踪核心:是一种补充性的渲染技术,主要通过计算光和渲染物体之间的反应得到正确的反射、折射、阴影即全局照明等结果,渲染出逼真的模拟场景和场景内对象的光照情况。
张量核心:张量核心可以提升GPU的渲染效果同时增强AI计算能力。张量核心通过深度学习超级采样(DLSS)提高渲染的清晰度、分辨率和游戏帧速率,同时对渲染画面进行降噪处理以实时清理和校正光线追踪核心渲染的画面,提升整体渲染效果。

三、市场分析
1、GPU市场规模及预测
根据Verified Market Research的预测,2020年GPU全球市场规模为254亿美金,预计到2028年将达到2465亿美金,行业保持高速增长,CAGR为32.9%,2023年GPU全球市场规模预计为595亿美元。

2、PC显卡市场
2022年独立显卡出货遭遇巨大下滑的原因有三点:(1)受宏观经济影响,个人电脑市场处于下行周期;(2)部分独立GPU参与虚拟货币挖矿,以太坊合并对独立GPU出货造成巨大冲击;(3)下游板卡厂商开启降库存周期。
3、GPU在数据中心的应用蕴藏巨大潜力
在数据中心,GPU被广泛应用于人工智能的训练、推理、高性能计算(HPC)等领域。
预训练大模型带来的算力需求驱动人工智能服务器市场快速增长。巨量化是人工智能近年来发展的重要趋势,巨量化的核心特点是模型参数多,训练数据量大。
战略需求推动GPU在高性能计算领域稳定增长。高性能计算(HPC)提供了强大的超高浮点计算能力,可满足计算密集型、海量数据处理等业务的计算需求,如科学研究、气象预报、计算模拟、军事研究、生物制药、基因测序等。

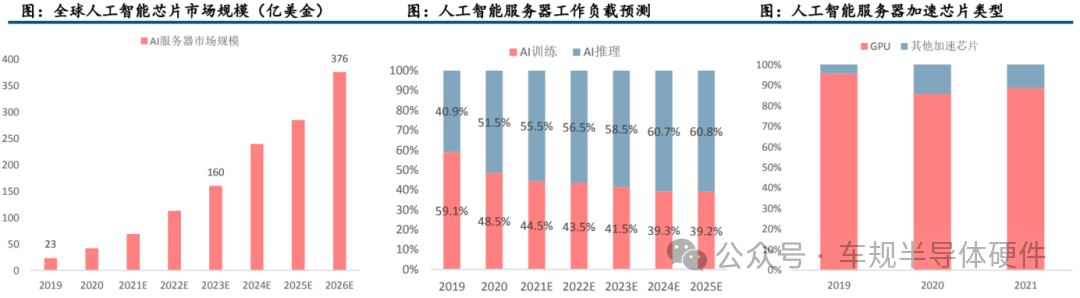
4、AI服务器是GPU市场规模增长的重要支撑
根据Omdia数据,2019年全球人工智能服务器市场规模为23亿美金,2026年将达到376亿美金,CAGR为49%。根据IDC数据,2020年中国数据中心用于AI推理的芯片的市场份额已经超过50%,预计到2025年,用于AI推理的工作负载的芯片将达到60.8%。
人工智能服务器通常选用CPU与加速芯片组合来满足高算力要求,常用的加速芯片有GPU、现场可编程门阵列(FPGA)、专用集成电路(ASIC)、神经拟态芯片(NPU)等。
北美云厂商资本开支有所放缓。人工智能服务器多采取公有云、私有云加本地部署的混合架构,以北美四家云厂商资本开支情况来跟踪人工智能服务器市场需求变动,2022年四家云厂商资本开支合计1511亿美元,同比增长18.5%。
5、GPU在超算服务器中的市场规模保持稳定增长
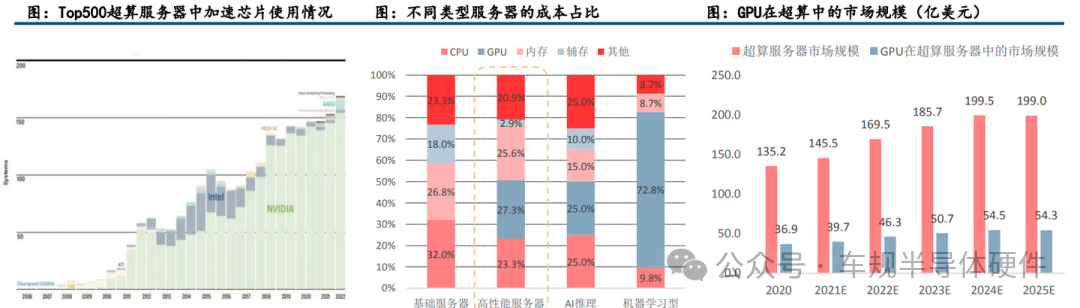
GPGPU在高性能计算领域渗透率不断提升。在高性能计算领域,CPU+GPU异构协同计算架构得到越来越多的应用,全球算力前500的超级计算机中,有170套系统采用了异构协同计算架构,其中超过90%以上的加速芯片选择了英伟达的GPGPU芯片。
GPU在超算服务器中的市场规模保持稳定增长。根据Hyperion Research数据,全球超算服务器的市场规模将从2020年的135亿美金上升到2025年的199亿美金,按照GPU在超算服务器中成本占比为27.3%核算,GPU在超算服务器中的市场规模将从2020年的37亿上升至2025年的54亿美金,CAGR为8%。
四、产业链及竞争格局分析
1、GPU产业链
GPU行业的产业链主要涉及三个环节:设计、制造、封装。供给模式有IDM、Fab+Fabless和Foundry三种。

2、竞争格局
全球GPU市场中,基本被Nvidia、Intel和AMD三家垄断。据JPR统计,全球PC GPU在2022年Q2出货量达到8400万台,同比下降34%,预计2022-2026年GPU复合增长率为3.8%。从市场格局来看,Nvidia、Intel和AMD三家在2022年Q2市场占有率分别为18%、62%和20%,Intel凭借其集成显卡在桌面端的优势占据最大的市场份额。

独显市场中,Nvidia占据领先地位。不同于整体市场,在独显市场中,Nvidia与AMD双雄垄断市场,其2022年Q2市占率分别约为80%和20%,可以看到近年来Nvidia不断巩固自己的优势,其独立显卡市占率整体呈现上升趋势。

国内市场来看,国产GPU赛道持续景气。近年来,国产GPU公司如雨后春笋般涌现,璧韧科技、摩尔线程、芯动科技、天数智能等公司纷纷发布新品。但是IP授权来看,国内主要的GPU创业公司,如芯动、摩尔线程、壁仞等采用的是Imagination IP或芯原授权的IP。
Imagination是一家总部位于英国,致力于打造半导体和软件知识产权(IP)的公司。公司的图形、计算、视觉和人工智能以及连接技术可以实现出众的PPA(功耗、性能和面积)指标、强大的安全性、快速的上市时间和更低的总体拥有成本(TCO)。2017年9月,私募投资公司Canyon Bridge以5.5亿英镑收购Imagination,Canyon Bridge其背后投资方为中国国新。


3、美国对华禁令如何应对
为应对封锁,短期来看可以选择英伟达和AMD的还没有被禁止的中低性能GPU芯片。对于云端计算,算力既可以通过产品升级得以提升,也可以通过增加计算卡的数量进行提升,因此短期内可以通过使用多个算力较低的CPU、GPU和ASIC芯片来复制高端GPU芯片的处理能力,基本可以满足云端训练和高性能计算的要求。长期来看,选择国产GPU进行替代。虽然芯片是算力的主要来源和最根本的物质基础,但是算力的生产、聚合、调度和释放是一个完整过程,需要复杂系统的软硬件生态共同配合,才能实现“有效算力”。因此短期内可能会因为无法兼容在人工智能领域广泛使用的CUDA架构而遭遇替换困难,但是长期来看,国产CPU、通用GPU、AI芯片将获得前所未有的发展机会,通过软硬件技术提升,逐步实现高端GPU领域的国产化替代。
专心 专业 专注


分布图领取







 扫码添加微信
扫码添加微信
- 点赞 0
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊