


字节 Seed 团队 ICML 2025 论文一览
- 2025-07-17 22:07:15

大模型浪潮奔涌,前沿探索永不止步!在机器学习顶会 ICML 2025 上,字节跳动 Seed 团队共有25篇论文入选。研究方向涵盖多模态基础模型、AI for Science、大模型理论、生成模型等多个前沿领域。本文将带您解读其中 15 篇最新研究成果,一窥通往 AGI 之路上的新洞见与新突破。
https://research.doubao.com/zh/public_papers
悄咪咪的吐槽一句上面这个网页,点击下一页没有反应所以只能看到第1页 ICML 2025 的 15 篇论文。本推文由AI生成可能有误。
(1) 构建VLM的“金钟罩”:用闭式解对齐对抗路径单纯形 🔥
论文类别:Spotlight
论文英文标题:Improving Zero-Shot Adversarial Robustness in Vision-Language Models by Closed-form Alignment of Adversarial Path Simplices
论文链接:https://icml.cc/virtual/2025/poster/45018
介绍:
由相关机构的研究者们提出了名为 AdvSimplex 的新方法,旨在提升视觉语言模型(VLM)的零样本对抗鲁棒性。尽管像 CLIP 这样的大型VLM在零样本分类上表现出色,但它们极易受到精心设计的对抗样本的攻击,这给其在现实世界中的安全部署带来了巨大隐患。
现有的对抗微调方法通常只关注将最终生成的“最强”对抗样本与原始干净样本的预测结果进行对齐,却忽略了在生成对抗样本过程中,那些跨越模型决策边界的“中间”对抗样本。研究者们敏锐地指出,这些中间样本及其邻近区域蕴含了关于模型决策边界的丰富信息。一个创新的想法是,通过连接干净样本和对抗路径上连续的两个中间样本,可以构成一个“单纯形”(Simplex,二维空间中即为三角形)。通过在这个单纯形区域内采样,可以生成更多样化且信息丰富的对抗候选,从而更全面地提升模型的鲁棒性。
然而,对这些单纯形进行显式采样并逐一训练,计算成本极其高昂,难以实际应用。为此,该工作的核心贡献在于,通过泰勒展开,巧妙地推导出了一个对齐损失的上界。这个上界不再依赖于昂贵的采样过程,而是可以通过一个**闭式解(closed-form)**来高效计算。该计算仅依赖于在干净样本点上即可轻松获得的雅可比矩阵(Jacobian)和海森矩阵(Hessian),相当于对单纯形进行了无穷次的均匀采样,极大地提升了训练效率。
最终,AdvSimplex 在15个不同的数据集和多样化的视觉语言任务上取得了当前最先进的(SOTA)对抗鲁棒性。这项工作不仅为提升VLM的安全性提供了强大的新工具,也为理解和利用对抗样本的几何结构开辟了新的理论视角。
核心图片:

(2) 解码蛋白质语言模型:系统性探索多模态设计空间 🔥
论文类别:Spotlight
论文英文标题:Elucidating the Design Space of Multimodal Protein Language Models
论文链接:https://icml.cc/virtual/2025/poster/44312
介绍:
由相关机构的研究者们对多模态蛋白质语言模型(PLM)的设计空间进行了系统性的探索和阐释。多模态PLM通过整合蛋白质的序列(一维)和结构(三维)信息,为蛋白质建模、生成和设计提供了强大的基础。然而,现有模型普遍依赖于将连续的3D结构“分词化”(tokenize)为离散的标记,这一过程不可避免地会丢失精细的结构细节和原子间的关联信息,从而成为模型性能的主要瓶瓶颈。
该研究深入剖析了基于分词的多模态PLM存在的两大核心问题:1) 分词损失:将连续的3D坐标量化为离散token会造成结构保真度的显著下降;2) 结构预测不准确:即使分词器的重构精度很高,语言模型在生成这些结构token时依然表现不佳,因为模型难以学习到不同token索引之间的语义关联。
针对这些挑战,研究者们基于DPLM-2模型,系统性地探索并提出了一系列改进策略,构建了一个完整的设计空间:
- 改进生成模型
:提出了比特级(bit-wise)离散建模,提供更细粒度的监督信号,显著提升了模型的结构生成能力。 - 结构感知架构与表示学习
:引入了几何感知模块和表示对齐技术,为模型注入几何归纳偏置,有效改善了生成结构的多样性。 - 数据探索
:创新性地引入了多链蛋白质(multimer)数据进行训练。研究发现,多链和单链蛋白质的建模是深度关联的,利用多链数据中更丰富的结构相互作用,可以同时提升模型对单链和多链蛋白质的结构理解能力。
通过这些精心设计的方法,多模たPLM的结构建模能力得到了巨大提升。实验结果惊人,一个仅有650M参数的模型,在蛋白质折叠任务上的RMSD(均方根偏差)从5.52埃降低到2.36埃,其性能不仅超越了3B参数的基线模型,甚至与专门的蛋白质折叠模型相媲美。这项工作为构建更强大的多模态蛋白质基础模型指明了清晰的方向。
核心图片: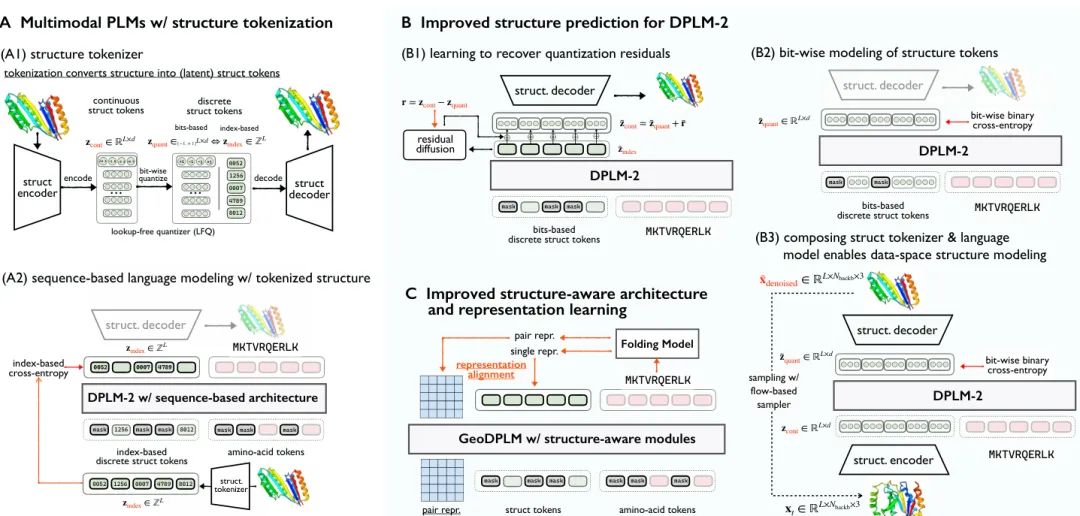
(3) 万物皆可奏鸣:交互式、对象感知的图像到音频生成
论文类别:Poster
论文英文标题:Sounding that Object: Interactive Object-Aware Image to Audio Generation
论文链接:https://icml.cc/virtual/2025/poster/46382
介绍:
由相关机构的研究者们提出了一个创新的交互式、对象感知的图像到音频生成模型。在复杂的视听场景中,准确地为特定物体生成声音是一项巨大挑战。例如,一张繁忙的街景图片,现有模型生成的音频往往是整体的环境音,难以区分汽车的引擎声、行人的脚步声和人群的嘈杂声,常常出现声音混杂或遗漏关键声源的问题。
为了解决这一难题,该研究从人类感知世界的方式中汲取灵感。我们能自然地将声音与特定的物体联系起来,该模型旨在复现这种“对象级别”的声音生成能力。研究者们将以对象为中心的学习范式(object-centric learning)融入条件潜在扩散模型中,通过多模态注意力机制,让模型在训练过程中自监督地学习图像区域与其对应声音之间的关联。
该模型最酷的特点是其交互性。在测试阶段,用户可以利用图像分割技术(如SAM),通过简单的鼠标点击或文本提示,在图片上选中一个或多个感兴趣的物体(例如,一辆汽车或一群人)。随后,模型会专门为被选中的物体生成对应的声音(如引擎声或人群嘈杂声)。如果用户同时选择多个物体,模型还能自然地将它们的声音融合到一个协调一致的声景中,而不是简单地叠加独立的音频片段。
更重要的是,研究者们从理论上证明了,在测试时用分割掩码(segmentation mask)替代训练时的注意力图是可行的。他们证明了模型的注意力机制在功能上近似于分割掩码,从而保证了生成音频与所选对象的精确对齐。大量的定量和定性评估表明,该模型在声-物对齐和用户可控性方面均优于现有基线方法,为视听内容的创作和编辑提供了强大的新工具。
核心图片:
(4) DiTAR:融合扩散与自回归,革新连续语音生成
论文类别:Poster
论文英文标题:DiTAR: Diffusion Transformer Autoregressive Modeling for Speech Generation
论文链接:https://icml.cc/virtual/2025/poster/46258
介绍:
由相关机构的研究者们提出了DiTAR(Diffusion Transformer AutoRegressive Modeling),一个创新的基于补丁(patch-based)的自回归框架,旨在高效地生成连续的语音表示。自回归语言模型(LM)在处理离散文本token方面取得了巨大成功,但对于音频、图像等连续信号,离散化往往会损失大量信息。直接对连续token进行自回归建模是一个极具挑战性的方向。
现有的一些工作尝试将扩散模型与自回归模型结合,但普遍面临计算负载过高或生成质量不佳的问题。研究者们分析认为,性能不佳的原因在于,传统的因果注意力(causal attention)语言模型强制的单向依赖关系,与连续信号(如语音帧)之间紧密的双向关联性相冲突。
为此,DiTAR提出了一种巧妙的“分而治之”策略。它将连续的语音token序列分解为多个补丁(patch)。然后,用一个因果语言模型来负责补丁与补丁之间的长程依赖关系预测(inter-patch prediction),而用一个带有双向注意力的扩散变换器(Diffusion Transformer, DiT)来负责每个补丁内部的token生成(intra-patch prediction)。这个用于生成局部补丁的DiT被命名为LocDiT。这种设计充分发挥了LM在处理长序列上下文和DiT在建模局部紧密结构方面的各自优势,同时通过补丁化大幅降低了计算复杂度。
此外,该研究还为连续值自回归模型提出了一种新颖的采样方法。通过将“温度”定义为在反向扩散ODE轨迹中引入噪声的时间点,该方法能够在使用快速ODE求解器的同时,有效平衡生成的多样性与确定性。
在零样本文本到语音(Zero-Shot TTS)任务上的实验表明,DiTAR在生成鲁棒性、说话人相似度和自然度方面均达到了SOTA水平,并且计算成本远低于其他竞争模型。这项工作为连续多媒体信号的自回归生成提供了一个高效且可扩展的强大新范式。
核心图片:
(5) Expert Race:用灵活路由策略扩展扩散变换器
论文类别:Poster
论文英文标题:Expert Race: A Flexible Routing Strategy for Scaling Diffusion Transformer with Mixture of Experts
论文链接:https://icml.cc/virtual/2025/poster/46221
介绍:
由相关机构的研究者们提出了 Race-DiT,一种针对扩散变换器(Diffusion Transformer)的新型专家混合(Mixture of Experts, MoE)模型,其核心是一种名为“专家竞赛(Expert Race)”的灵活路由策略。
扩散模型已成为视觉生成的主流框架,而MoE作为扩展大模型规模的有效技术,两者的结合展现出巨大潜力。然而,研究者们观察到,扩散模型处理的视觉信号与语言模型有两大不同:1)视觉信息存在高度的空间冗余(如背景和前景的信息密度差异巨大);2) 降噪任务的复杂度随时间步(timestep)动态变化(早期降噪简单,后期需要重建精细细节)。这些特性要求MoE的路由策略必须具备高度的灵活性,能够根据任务难度动态分配计算资源。
传统的MoE路由策略(如token-choice或expert-choice)在分配灵活性上存在局限,无法同时兼顾空间区域和时间步的复杂度变化。为此,“专家竞赛”策略应运而生。它打破了常规的分配模式,让所有样本、所有时间步的所有token与所有专家一起“同场竞技”,然后选择全局得分最高的top-k个token-expert对进行计算。这种机制极大地解放了路由的自由度,模型可以自适应地将更多专家资源分配给更关键、更难处理的token(无论是来自复杂图像区域还是困难的降噪阶段),从而实现计算资源的优化配置。
为确保这种高度灵活策略的有效性,研究者们还提出了两项关键技术:1)逐层正则化,解决MoE模型在浅层网络中学习困难的问题;2)路由器相似度损失,通过约束专家之间的选择模式,防止“模式崩溃”(即多个专家学会了同一种分工),确保了专家的多样性和有效利用。
在ImageNet上的大量实验证明了Race-DiT的有效性。它不仅在性能上显著超越了同等激活参数量的稠密模型,还揭示了新的模型缩放规律,为构建更强大、更高效的视觉生成模型铺平了道路。
核心图片: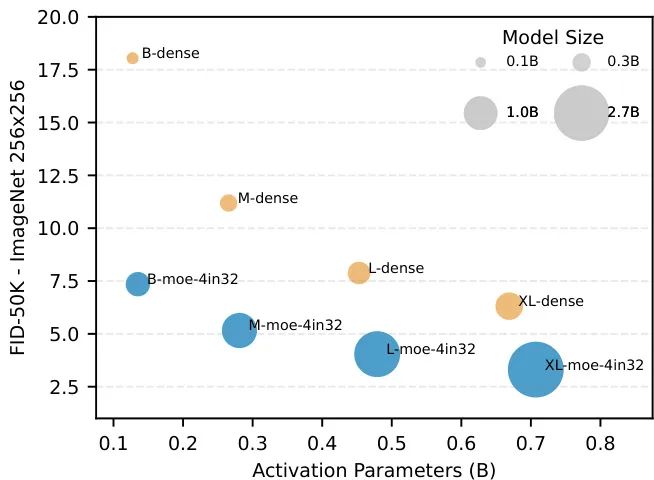

(6) APM:用于设计蛋白质复合物的全原子生成模型
论文类别:Poster
论文英文标题:An All-Atom Generative Model for Designing Protein Complexes
论文链接:https://icml.cc/virtual/2025/poster/46160
介绍:
由相关机构的研究者们推出了一款专为多链蛋白质复合物设计的全原子生成模型——APM (All-Atom Protein Generative Model)。在生物体内,蛋白质通常以复合物的形式存在,通过与其他蛋白质或生物分子相互作用来执行其特定的生物学功能。尽管单链蛋白质建模已取得巨大进展,但对功能至关重要的多链蛋白质研究仍相对不足。
APM的提出旨在填补这一空白,它直面多链蛋白质设计的核心挑战:
- 多链蛋白质建模
:现有模型常通过“伪序列”(如poly-G)将多条链连接成一条来处理,这不符合天然复合物的形成方式。APM则通过混合训练单链和多链数据,并引入链间/链内注意力机制,实现了对多链蛋白质的原生建模,无需人工连接。 - 全原子表示
:蛋白质间的相互作用发生在精细的原子层面。为了精确捕捉这些作用力,APM采用了全原子结构表示。它创新性地将每个残基表示为其氨基酸类型、骨架结构和侧链构象(由最多四个扭转角参数化)的组合,既保留了关键的原子级信息,又维持了计算效率。 - 序列-结构依赖性
:在联合生成序列和结构时,两种模态的独立加噪过程会破坏它们之间的强依赖关系。APM通过解耦加噪过程,并引入50%概率的折叠/逆向折叠任务,强制模型学习这两种模态之间的双向依赖。
APM的架构设计也独具匠心,它包含三个协同工作的模块:一个基于流匹配(flow-matching)的Seq&BB模块用于共生序列和骨架;一个侧链模块用于补全全原子结构;一个精修模块则利用全原子信息进一步优化序列和骨架。
实验结果表明,APM不仅能够生成紧密结合的蛋白质复合物,并胜任多链蛋白质的折叠和逆向折叠任务,在抗体设计和结合肽设计等下游应用中,其性能也超越了当前的SOTA基线。这项工作为设计具有生物活性的蛋白质复合物提供了强大的新工具。
核心图片:
(7) 视频生成离世界模型还有多远?一个物理定律的视角
论文类别:Poster
论文英文标题:How Far Is Video Generation from World Model: A Physical Law Perspective
论文链接:https://icml.cc/virtual/2025/poster/46015
介绍:
由相关机构的研究者们从物理定律的视角,对当前视频生成模型作为“世界模型”的潜力进行了系统性的评估。人们普遍认为,通过扩展模型和数据规模,视频生成模型有望学习并遵循现实世界的基本物理规律。但这些模型是否真的能从纯粹的视觉数据中抽象出物理定律,还是仅仅在“死记硬背”训练样本,这是一个悬而未决的问题。
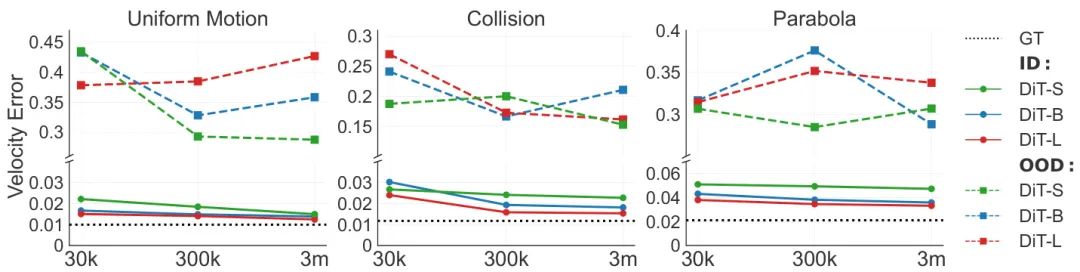
为了回答这个问题,研究者们构建了一个2D物理仿真测试平台。这个平台可以确定性地生成由经典力学定律(如匀速直线运动、完全弹性碰撞、抛物线运动)控制的物体运动视频。这种受控环境排除了真实世界视频中的复杂纹理、非刚性物体等干扰因素,使得对模型物理理解能力的量化评估成为可能。
研究团队将评估场景分为三类,以全面考察模型的泛化能力:
- 分布内(In-distribution, ID)泛化
:测试数据与训练数据遵循相同的物理定律和参数范围。 - 分布外(Out-of-distribution, OOD)泛化
:测试数据的物理参数(如速度、大小)超出了训练范围,考验模型的“举一反三”能力。 - 组合泛化(Combinatorial Generalization)
:测试模型能否将已见过的不同物理概念(如自由落体和碰撞)进行新颖的组合。
通过对不同规模的视频扩散模型(参数从22M到310M)和数据集(从3万到600万)进行扩展性实验,研究者们得出了深刻的洞见:
- 模型在ID场景下表现完美
,但在OOD场景下则完全失效,且增加模型或数据规模对此毫无帮助。这表明单纯的“大力出奇迹”不足以让模型发现普适的物理定律。 模型倾向于“基于案例(case-based)”的泛化,即模仿与测试场景最接近的训练样本,而不是抽象出通用的物理规则。 在泛化到新案例时,模型对不同数据属性的优先级为:颜色 > 大小 > 速度 > 形状。这或许解释了为何当前视频生成模型难以保持物体的形态一致性。
这项研究有力地表明,仅仅依靠扩大规模,视频生成模型离真正理解物理世界的“世界模型”还有很长的路要走。
核心图片:
(8) 基于LLM改写的鲁棒多比特文本水印
论文类别:Poster
论文英文标题:Robust Multi-bit Text Watermark with LLM-based Paraphrasers
论文链接:https://icml.cc/virtual/2025/poster/46008
介绍:
由相关机构的研究者们提出了一种基于大语言模型(LLM)改写(paraphrasing)的、难以察觉的多比特文本水印技术。随着LLM的普及,如何追踪和验证AI生成内容的来源、保护版权,以及检测虚假信息,变得日益重要。文本水印技术为此提供了一种有效的解决方案。
传统的文本水印方法大多基于词汇替换,容易被简单的文本扰动(如替换同义词)破坏。而基于改写的方法拥有更大的操作空间,理论上更具鲁棒性。但其挑战在于,如何在不改变原文语义和保持文本流畅性的前提下,嵌入一个既不可见又可被准确解码的水印信号。
该研究的核心思想是:训练一对行为有细微差异的LLM改写器(paraphraser)。一个改写器代表二进制的“0”,另一个代表“1”。在嵌入水印时,根据预设的二进制密钥(如“0110…”),在句子层面交替使用这两个改写器来重写原文。由于两个改写器被特意训练得不同,它们生成的句子在深层语义上会留下独特的、人眼难以分辨的“指纹”。
解码过程则由一个专门训练的文本分类器(decoder)完成。解码器逐句分析文本,判断每一句是由“0”改写器还是“1”改写器生成的,从而恢复出原始的二进制密钥。
为了让水印信号更强且解码更准,研究者们设计了一个巧妙的协同训练(co-training)框架。编码器(改写器)和解码器(分类器)在训练中交替优化。解码器通过标准分类损失来提升识别能力;而编码器则利用强化学习(PPO算法),将解码器的解码正确率作为奖励信号,来微调自身,使其生成的文本更容易被解码器“看穿”,同时保持与原文的高度语义相似性。
实验结果表明,该方法效果卓越:
- 高精度
:使用1.1B的小模型,水印检测的AUC可超过99.99%,比特准确率高达95%以上。 - 高鲁棒性
:在面对词语替换、句子改写等常见攻击时,水印依然能够被有效检测。 - 高隐蔽性
:通过基于LLM的评估验证,该水印对人类和大型模型来说都难以被察觉。
这项工作为构建安全、可靠且实用的文本溯源系统提供了强大的技术支持。
核心图片:
(9) CPSDE:基于谐波SDE与原子-键建模的环肽设计
论文类别:Poster
论文英文标题:Designing Cyclic Peptides via Harmonic SDE with Atom-Bond Modeling
论文链接:https://icml.cc/virtual/2025/poster/45948
介绍:
由相关机构的研究者们提出了一种名为CPSDE的开创性算法,首次实现了基于生成模型直接设计各类环肽(Cyclic Peptides)。环肽作为一种特殊的肽类药物,因其闭环结构而具有比线性肽更高的稳定性、更好的靶点亲和力以及更强的抗酶解能力,在医药领域展现出巨大潜力。
然而,设计环肽面临着诸多挑战:1)真实世界中环肽-靶蛋白复合物的3D结构数据稀缺;2)环化过程引入了复杂的几何约束;3)环化常常涉及非标准氨基酸。现有计算方法通常只能设计特定类型的环肽(如二硫键连接),无法灵活应对多样的环化方式。
CPSDE巧妙地解决了这些难题,其核心在于两大创新组件和一个创新的采样算法:
- ATOMSDE
:一个基于谐波随机微分方程(harmonic SDE)的全原子和化学键生成结构预测模型。与传统方法在残基层面建模不同,CPSDE在最基础的原子和化学键层面进行建模。这使得模型能够充分利用海量的小分子和线性肽数据,最大程度地减少对稀缺环肽数据的依赖。同时,显式地对化学键进行建模,使模型能够精确满足环化带来的几何约束。 - RESROUTER
:一个残基类型预测器,用于在生成过程中确定非环化部分的氨基酸序列。 - 路由采样算法(Routed Sampling)
:这是连接上述两个模型的桥梁。在生成过程中,算法在ATOMSDE和RESROUTER之间交替进行,迭代地更新肽的序列和全原子三维结构。给定一个蛋白质靶点和期望的环化类型(如头尾相连、侧链-侧链相连等),CPSDE可以从头开始生成符合约束的、具有高亲和力的环肽。
实验结果表明,CPSDE设计的环肽在稳定性和亲和力方面表现出色,同时保持了高度的多样性。通过分子动力学模拟的案例研究进一步证实了该方法在真实药物设计场景中的实用性和有效性。这项工作为基于计算的环肽药物发现开辟了全新的道路。
核心图片:
(10) 主动奖励建模:大语言模型对齐的自适应偏好标注
论文类别:Poster
论文英文标题:Active Reward Modeling: Adaptive Preference Labeling for Large Language Model Alignment
论文链接:https://icml.cc/virtual/2025/poster/45827
介绍:
由相关机构的研究者们针对大语言模型(LLM)对齐中的核心环节——奖励建模,提出了一套基于主动学习的高效数据标注策略。LLM对齐通常依赖于基于人类反馈的强化学习(RLHF),其关键一步是利用人类对不同模型输出的偏好标注来训练一个奖励模型(RM)。然而,人类标注成本高昂且数量有限,如何选择信息量最大的样本对进行标注,以最大限度地提升奖励模型的学习效率,是一个至关重要却尚未被充分解决的问题。
该研究的核心洞见是:一个理想的偏好标注数据集,应该在探索表示空间和进行信息丰富的比较之间取得平衡。也就是说,我们既需要选择那些能够覆盖模型未知区域的样本(探索),也需要选择那些奖励差异适中、能让模型学到细微差别的样本对(利用)。太简单(如冠军对新手)或太相似的比较,提供的信息量都很低。
为了实现这一目标,研究者们将主动学习问题与经典的实验设计理论联系起来,并引入了基于费雪信息(Fisher Information)的样本选择策略。他们将这些经典理论应用于深度神经网络奖励模型的最后一层线性层。费雪信息矩阵可以同时量化“表示空间的多样性”(通过特征差异的协方差矩阵体现)和“比较的信息量”(通过预测概率的方差体现),从而自然地平衡了探索与利用。
该工作系统性地比较了8种不同的主动学习评分算法,包括来自经典统计学和最新深度学习文献的方法。在涉及多种开源LLM(规模从2B到8B)和数据集的广泛实验中,基于费雪信息的经典实验设计方法(如D-optimality)表现出卓越的性能、高计算效率和稳定性,全面超越了其他方法。
此外,一项重要的消融研究发现,在主动奖励建模中引入跨提示(cross-prompt)的比较,能够显著提升标注效率。这为未来设计更高效的RLHF标注策略提供了宝贵的启示。
核心图片:

(11) 信息论视角下的LLM思维链理解
论文类别:Poster
论文英文标题:Understanding Chain-of-Thought in LLMs through Information Theory
论文链接:https://icml.cc/virtual/2025/poster/45723
介绍:
由相关机构的研究者们提出了一个基于信息论的全新形式化框架,用于理解和评估大语言模型(LLM)中的思维链(Chain-of-Thought, CoT)推理过程。CoT通过将复杂问题分解为一系列中间步骤,极大地提升了LLM在数学、逻辑等任务上的表现。然而,如何准确评估CoT中每一步推理的质量,是一个巨大的挑战。
现有的评估方法存在明显缺陷。一些方法如“过程监督”(Process Supervision)依赖于昂贵的人工逐步标注数据,难以大规模应用。而另一些方法如“结果奖励建模”(Outcome Reward Modeling)试图通过最终答案的正确性来反推中间步骤的质量,但这种方法并不可靠,常常导致高“假阳性”率——即模型可能通过错误的推理碰巧得到了正确答案,而该方法却会错误地认为中间步骤也是正确的。
为了克服这些局限,该研究从信息论的角度提出了一个核心洞见:在一次正确的推理中,每一步都应该为预测最终正确答案提供有价值的、相关的信息。基于此,研究者们开发了一个框架来量化CoT中每一步推理所带来的“信息增益(information-gain)”。
具体来说,他们训练一个“监督者模型”(supervisor model),该模型接收CoT到任意一步的中间结果,并被训练来预测最终的正确答案。通过比较输入第 j-1 步和第 j 步的中间结果后,监督者模型预测正确答案的损失(cross-entropy loss)的下降程度,就可以量化出第 j 步带来的信息增益。如果增益为正,说明这一步是有效的;如果增益趋近于零或为负,则说明这一步可能是错误的、无效的或冗余的。
该方法最大的优势在于,它无需任何人工标注的中间步骤数据,仅需要(问题,最终正确答案)对,即可评估模型生成的任意CoT路径中每个步骤的质量。在算术、GSM8K和PRM800K数据集上的大量实验证明,该方法能显著优于现有的基于结果的评估方法,更准确地识别出LLM推理过程中的失败模式,为模型的改进提供了更精细的指导。
核心图片:
(12) 多基座推测解码的理论视角
论文类别:Poster
论文英文标题:polybasic Speculative Decoding Through a Theoretical Perspective
论文链接:https://icml.cc/virtual/2025/poster/45669
介绍:
由相关机构的研究者们提出了一个全新的“多基座(polybasic)”推测解码框架,并为其提供了坚实的理论基础,旨在突破现有大语言模型(LLM)推理加速技术的瓶颈。推测解码(Speculative Decoding)通过“小模型草稿、大模型验证”的机制,能够在不牺牲输出质量的前提下显著提升LLM的推理速度。
然而,现有的推测解码方法大多局限于一个草稿模型和一个目标模型的“二元”框架,并且缺乏严谨的理论指导来优化系统设计。这导致加速效果受限于草稿模型与目标模型之间的能力差距,难以进一步提升。
该研究从理论分析入手,取得了两个核心突破:
- 推导出了一个基本定理
,精确刻画了多模型推测解码系统的最优推理时间。这个定理揭示了模型前向计算成本、平均接受长度和系统整体推理速度之间的内在关系。它清晰地指明了在何种条件下,向系统中增加更多的中间层模型能够带来净收益,从而为从“二元”框架扩展到更通用的“多基座”范式提供了理论依据。 - 证明了推测采样(speculative sampling)在多模型设置下能够显著提升接受长度的稳定性
。通过优化采样参数,可以降低token接受数量的方差,从而获得更可预测、更稳定的加速性能。
基于这些理论洞见,研究者们提出了一个统一的多基座推测解码架构,其中多个草稿模型与一个目标模型协同工作。例如,一个三模型系统可以由一个轻量级草稿模型(如EAGLE)、一个量化版的中等模型和一个全精度目标模型(如LLaMA-7B)组成。草稿首先由中等模型快速验证,累积到一定数量后再由最终目标模型进行批量验证,形成一个高效的“过滤”流水线。
实验结果非常亮眼,该框架在多种LLM(包括LLaMA2-Chat 7B, LLaMA3-8B, Vicuna-7B, Qwen2-7B)和多样化的任务上,均实现了3.3x到4.4x的惊人加速,同时完美保持了原始模型的输出分布,显著优于现有的推测解码技术。
核心图片:
(13) BRiTE:通过自举强化思维过程提升语言模型推理能力
论文类别:Poster
论文英文标题:BRiTE: Bootstrapping Reinforced Thinking Process to Enhance Language Model Reasoning
论文链接:https://icml.cc/virtual/2025/poster/45505
介绍:
由相关机构的研究者们提出了一个名为BRiTE(Bootstrapping Reinforced Thinking Process)的创新算法,旨在解决大语言模型(LLM)在复杂推理任务中生成可靠思维过程(thinking process)的重大挑战。尽管LLM通过思维链(CoT)等技术展现了强大的推理潜力,但其生成的推理步骤往往缺乏逻辑完备性或有效性,严重依赖于提示工程。
为了从根本上解决这个问题,BRiTE框架引入了几个关键创新:
- 统一的概率图模型框架
:研究者们首次将LLM的推理过程形式化为一个概率图模型。这个模型包含了从问题(Prompt, X)到潜在思维过程(Latent Rationale, Z),再到答案(Answer, Y)的生成流程,并引入了一个**评估信号(Evaluation Signal, O)**来判断(Z, Y)的质量。这种形式化不仅将复杂推理分解为更易处理的步骤,还为利用外部反馈(如正确答案验证)来指导高质量思维过程的生成提供了理论基础。 - 两阶段的BRiTE算法
:
- E-Step (强化学习生成高质量思维过程)
:如何生成高质量的思维过程(即后验分布P(Z|X,Y,O))是一个极具挑战性的贝叶斯推断问题。BRiTE创新地将其转化为一个强化学习(RL)优化问题。通过设计一种新颖的奖励塑造(reward shaping)机制,模型被训练去生成那些最有可能导出正确答案的“最优”思维路径。 - M-Step (微调基础模型)
:在获得高质量的思维过程-答案对之后,BRiTE将它们作为“黄金数据”,通过最大化联合概率来微调基础LLM,从而提升其内在的推理能力。
BRiTE为自动化地生成和利用高质量合成CoT数据来增强LLM推理能力,提供了一个可证明、可实践的强大框架。
核心图片:
(14) 过度分词的Transformer:词汇表通常值得扩展
论文类别:Poster
论文英文标题:Over-Tokenized Transformer: Vocabulary is Generally Worth Scaling
论文链接:https://icml.cc/virtual/2025/poster/44467
介绍:
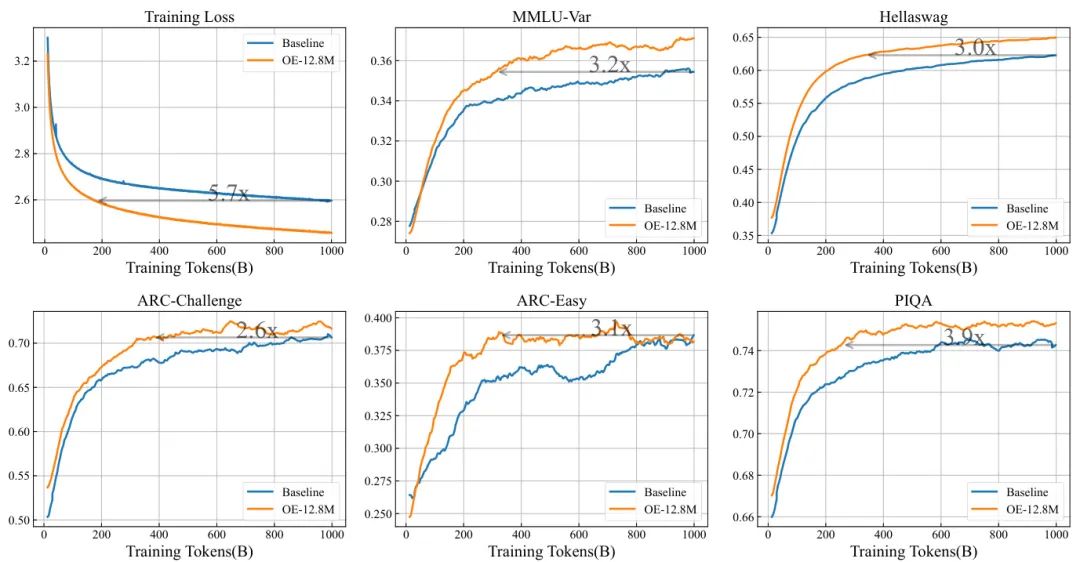
由相关机构的研究者们提出了一种名为“过度分词变换器(Over-Tokenized Transformer)”的新框架,并揭示了一个关于大语言模型(LLM)缩放定律(scaling laws)的新维度:词汇表规模通常值得扩展,尤其是输入词汇表。
分词(Tokenization)是LLM的基础构件,但其对模型性能和扩展性的影响尚未被充分挖掘。传统的LLM通常使用一个统一的词汇表进行输入编码和输出解码。研究者们敏锐地指出,扩大输入词汇表(embedding)和输出词汇表(unembedding)对计算成本的影响是截然不同的:扩大输入词汇表几乎不增加训练和推理的计算开销,而扩大输出词汇表则会显著增加softmax层的计算负担。
基于这一观察,该研究创造性地解耦了输入和输出词汇表,并分别研究它们的影响。他们引入了两个核心概念:
- 过度编码(Over-Encoding, OE)
:通过使用一个层级化的n-gram输入词汇表,极大地扩展输入词汇表的规模。例如,可以将词汇表规模从标准的10万级别扩展到千万级别。 - 过度解码(Over-Decoding, OD)
:利用更大的输出词汇表来提供更细粒度的监督信号,实践中,这可以被看作是多令牌预测(Multi-Token Prediction, MTP)等技术的一种理论近似。
通过在合成数据和真实自然语言数据上的大量实验,研究者们发现了令人振奋的规律:
- 输入词汇表与模型性能之间存在对数线性关系
:即输入词汇表规模的指数级增长,能带来模型训练损失的线性下降。这一规律在不同模型尺寸下都保持一致。 - 扩大输入词汇表的收益巨大
:实验显示,一个400M参数的OE模型,其性能可以媲美一个1B参数的基线模型,而训练成本几乎没有增加。这相当于用“免费”的稀疏参数换来了稠密参数的性能。 - OE和OD可以互补
:将OE和OD(以MTP形式)结合,能取得比单独使用其中任何一种更好的效果。
为了解决大词汇表带来的内存和通信挑战,研究者们还提出了高效的工程解决方案,使得额外的训练开销低于5%。这项工作为LLM的缩放定律增添了“词汇表”这一新维度,为设计更高效、更强大的LLM提供了宝贵的实践指导。
核心图片: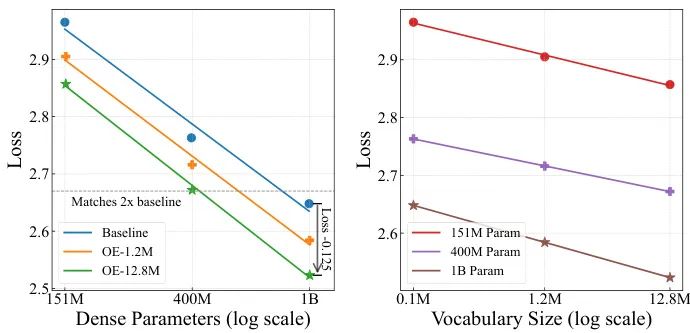
(15) 从CNN到LLM:被忽视的海森矩阵幂律结构揭秘
论文类别:Poster
论文英文标题:Investigating the Overlooked Hessian Structure: From CNNs to LLMs
论文链接:https://icml.cc/virtual/2025/poster/44080
介绍:
由相关机构的研究者们首次揭示了一个在深度学习中长期被忽视的、简单而深刻的结构——海森矩阵(Hessian)的幂律(power-law)结构。海森矩阵描述了损失函数的局部曲率,对理解模型的优化、泛化和鲁棒性至关重要。
以往的研究笼统地指出,深度学习模型的损失景观中,海森矩阵的谱(即特征值集合)由“少量大特征值和大量接近零的特征值”构成。然而,这种描述缺乏定量的统计分析。该研究通过对卷积神经网络(CNN)和大型语言模型(LLM)进行大量的谱分析实验,惊人地发现:对于一个训练良好的深度神经网络,其海森谱的特征值分布惊人地遵循一个幂律分布。这意味着,如果将特征值按大小排序,其数值与它的排序之间在双对数坐标下呈现出一条近似的直线。
这项发现不仅是一个经验观察,研究者们还为其提供了最大熵理论的解释,从统计物理学的角度论证了这种幂律结构的理论起源。此外,他们还从理论上证明了,这种谱结构的存在,自然地导出了深度神经网络中存在一个鲁棒且低维的学习子空间的现象,为近期的相关经验发现提供了理论依据。
基于这一发现,该研究提出了一个“幂律谱分析”框架,并用它来审视深度学习中的多个重要行为,得到了许多新颖的洞见,例如优化器、过参数化、训练数据量、批量大小等因素如何影响海森谱的幂律性。
其中最引人注目的发现之一是关于LLM的泛化预测。传统的基于“尖锐度/平坦度”(sharpness-based)的泛化度量(如最大特征值)在CNN上通常很有效,但在LLM上却常常失效。研究者们发现,在某些情况下,一个LLM的海森谱与理想幂律分布的拟合优度(通过KS距离度量)可以非常准确地预测其泛化能力,其相关系数高达0.98。这表明,幂律结构可能是理解和预测LLM泛化性能的一个被忽视的关键钥匙,为探索LLM的泛化之谜开辟了一条全新的道路。
核心图片:

-- 完 --
机智流推荐阅读:
2.LangChain 本地化应用探索(二):修复输出异常与模板适配策略
3.LangChain 本土私有化应用探索:魔搭社区ModelScope 模型对接实践
4.构建可调用外部工具的AI助手:LangChain函数调用与API集成详解
关注机智流并加入 AI 技术交流群,不仅能和来自大厂名校的 AI 开发者、爱好者一起进行技术交流,同时还有HuggingFace每日精选论文与顶会论文解读、Talk分享、通俗易懂的Agent知识与项目、前沿AI科技资讯、大模型实战教学活动等。 在「机智流」公众号后台回复下方标红内容即可加入对应群聊:
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 智能体 | Agent 技术交流群

 扫码添加微信
扫码添加微信
- 点赞 0
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊







