字节 MemAgent 让 LLM 拥有“无限记忆”
- 2025-07-17 18:08:00

论文题目:MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent
论文地址:https://arxiv.org/pdf/2507.02259
代码地址:https://memagent-sialab.github.io/

创新点
不同于传统方法试图扩展上下文窗口或使用稀疏/线性注意力,MemAgent 把超长文档看作连续证据流:模型每次只读入一个固定长度的文本块,并维护一个固定长度的可覆写记忆槽(memory slot)。该记忆以普通 token 形式存在于上下文窗口内,无需修改位置编码或引入额外模块,即可让“8K 训练窗口”在推理时平滑外推到百万级 token,实现 O(N) 线性复杂度。
记忆更新被形式化为一个强化学习决策:每读完一个文本块,模型生成一段新的记忆 token 序列直接覆盖旧记忆。保留什么、丢弃什么由策略网络决定,奖励来自下游任务最终答案的规则可验证结果。这种“写后即焚”的极简机制避免了记忆膨胀,却通过 RL 学习到了任务相关的压缩与保留策略,显著减少信息丢失。
由于一次长文本会衍生多条相互独立的对话轨迹(每段文本块对应一次记忆更新),传统 PPO/GRPO 无法直接应用。作者将 DAPO 扩展为 Multi-Conv DAPO:把每条轨迹视为一个可独立采样的“对话”,用最终答案的奖励计算归一化优势,并一次性回传到所有相关轨迹。这样既保持了组内归一化的稳定性,又实现了跨多段上下文的高效策略梯度训练。
方法
本文将超长文本处理抽象为“分段读取-记忆覆写-最终回答”的闭环流程:在推理阶段,把任意长度的文档切成若干 5K token 的块,每次把当前块与一段固定 1K token 的显式记忆拼接送入 8K 窗口的 LLM;模型先输出一段新的 1K token 记忆直接覆盖旧记忆,再进入下一块,如此循环直至文档读完,最后仅依赖累积记忆生成答案。训练阶段,作者将上述“读-写-读”循环视为 RL 轨迹,用基于规则的可验证答案作为最终奖励,采用扩展的 Multi-Conv DAPO 算法同时对多条独立对话轨迹进行组内归一化与策略梯度更新,使模型学会在有限记忆槽中保留关键信息、丢弃冗余内容,从而以 O(N) 计算代价实现从 8K 训练到 3.5M token 推理的近乎无损外推。
不同模型在RULER-HotpotQA任务中的准确率随上下文长度变化趋势图

本图展示了不同模型在RULER-HotpotQA任务中的准确率随上下文长度(从7K到3.5M tokens)变化的趋势图。图中对比了MemAgent(7B和14B)与多个基线模型(如Qwen2.5-Instruct-1M、DS-Distill-Qwen等)的表现,突出MemAgent在超长上下文下性能几乎无损,而其他模型在扩展上下文后性能迅速下降。
传统长上下文LLM与MemAgent处理机制的对比示意图
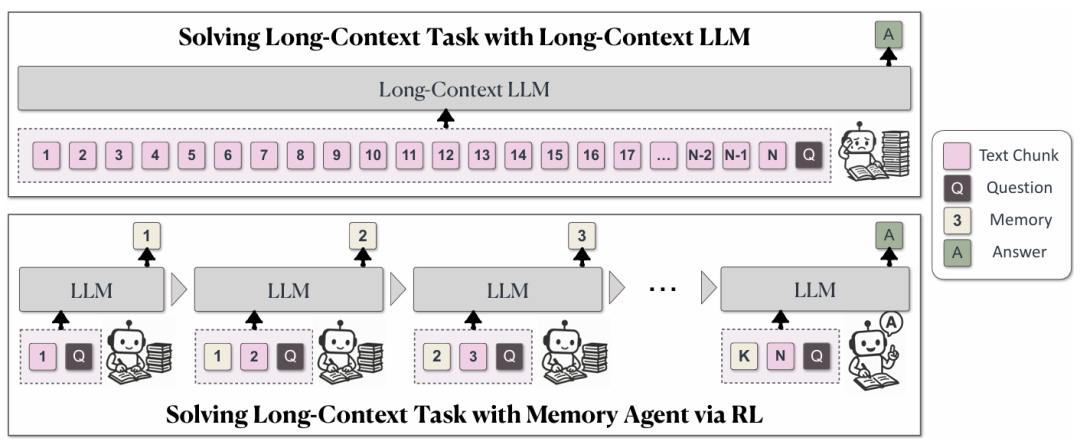
本图左侧描绘了我们熟悉的“传统长上下文 LLM”工作方式:面对一份从 Chunk1 一路排到 ChunkN 的超长文档,模型一次把所有文本塞进上下文窗口,再连同问题 Q 直接吐出答案 A;如果文本超过窗口上限,就只能截断或压缩,性能随之骤降。右侧则呈现了 MemAgent 的全新机制:它不再强求一次性读完所有内容,而是像人类做笔记那样,把文档切成若干 5000 token 左右的片段,每读一段就更新一次固定长度(1024 token)的“记忆”。这个记忆并非外部模块,而是一段普通文本,直接写在上下文里,下一轮读新片段时旧片段被丢弃,只剩最新记忆继续参与推理。如此循环,直到文档读完,最终只凭问题与这段精炼记忆生成答案。
Multi-Conv DAPO与标准GRPO训练流程对比图
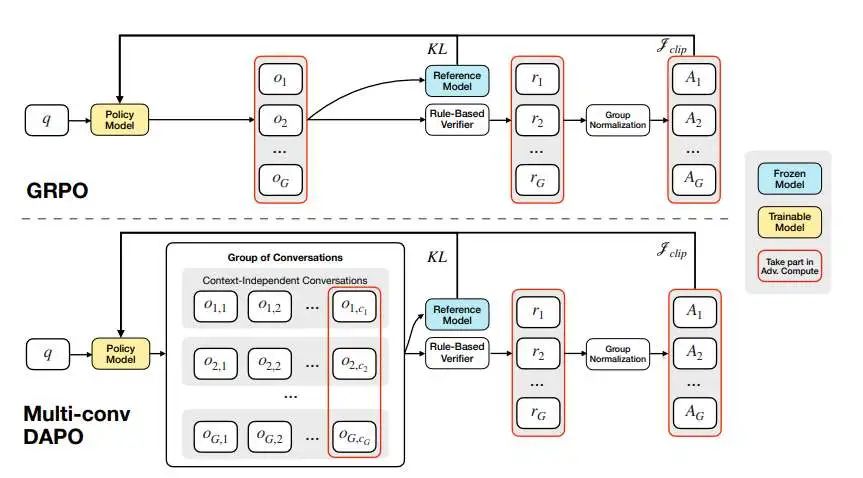
本图把强化学习训练流程画成两条平行的“流水线”,一条是 vanilla GRPO,另一条是本文提出的 Multi-Conv DAPO。在左侧 GRPO 的流水线里,一个样本只产出一组对话,每个对话的 token 被放进同一上下文窗口,靠注意力掩码区分回合,最终用这组对话的奖励 r₁…r_G 计算优势值并更新策略;右侧 Multi-Conv DAPO 的流水线则把同一样本拆成多条完全独立的对话,每条对话彼此无上下文依赖,各自独立生成,直到最后一条对话给出答案后,才用一个统一的规则验证器算出单个奖励 r,然后把这一奖励广播回前面所有对话,统一计算组归一化优势值并一次性更新整条策略。
实验

本表展示了不同模型在不同上下文长度下的性能表现。表格从左到右列出了从 7K 到 3.5M 不同长度的上下文,每一列对应一个上下文长度,每一行对应一个模型。 表格中的模型包括了多种不同的长上下文处理方法,如 QwenLong-L1、Qwen2.5-Instruct 系列、DS-Distill-Qwen 系列以及本文提出的 MemAgent。这些模型在不同的上下文长度下进行了评估,以考察它们在处理长文本任务时的性能表现。总结来说,本表的结果清楚地展示了 MemAgent 在处理长文本任务时的优越性。与其他基线模型相比,MemAgent 在不同上下文长度下都能保持较高的准确率,证明了其在长文本处理中的高效性和可扩展性。这验证了 MemAgent 通过固定长度记忆和强化学习训练所实现的线性复杂度和几乎零损耗的性能外推能力。
-- END --

关注“学姐带你玩AI”公众号,回复“2025大模型”
领取2025大模型创新方案合集+开源代码

 扫码添加微信
扫码添加微信
- 点赞 0
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊