


Skywork-OR1——小作坊的强化之路
- 2025-07-15 08:00:00
作者 | ybq 编辑 | 大模型之心Tech
原文链接:https://zhuanlan.zhihu.com/p/1925691663654850602
点击下方卡片,关注“大模型之心Tech”公众号
>>点击进入→大模型没那么大Tech技术交流群
本文只做学术分享,如有侵权,联系删文,自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
不知不觉,deepseek r1 的那篇技术报告过去半年了,“遇事不决上强化”的风气也没有年初那么夸张了。或多或少,大家都陆续回归到 sft 和 R1 混合使用的传统路线了。
既然强化的浮夸风已经过去大半,我们不妨平心静气的看下小作坊的强化之路 —— Skywork or1 的技术报告。
前言
并非所有团队都有 dpsk、seed、qwen 的豪华配置,包括但不限于:infra 基建,人才密度,gpu,市面上所有好模型的请求额度,标注团队 …… 因此,不同团队做强化学习的目标是不同的:
dpsk 和各大厂的核心团队:追赶 OpenAI 和 Google,提高模型泛化能力,尽早建立技术壁垒; 普通从业者和小作坊:培养强化学习的认知,掌握相关技术栈,助力于日常工作或是保证自己能跟得上一线技术团队; 普通爱好者:发论文。
当大家都把目光聚焦在御三家的研究成果时,我个人反倒是觉着,小作坊的经验分享和技术报告更有价值。一方面内容更加接地气(消耗的资源量并不浮夸,有复现的可能性),另一方面也足够的大方(qwen3 的技术报告,关于强化细节那是一个字都没提)。
skywork 的这篇技术报告最起码在以下几点上来说是聪明的:
使用了字节的 veR1 和 qwen 的底座模型,复现起来非常容易; 找了一个强有力的的 baseline:DeepScaleR,模仿它,分析它,超越它; 卡的数量很友好,各种消融实验都是 32卡、64卡、128卡; 选定了一个核心技术方向来分析:Mitigating Policy Entropy Collapse; 不搞花里胡哨的,就做所有人都在做的 math、code,吃透就好; 消融实验足够多,可能不具有普适性,但至少告诉了我们强化的哪些细节是需要做消融的。
训练策略
这篇文章的 R1 用的是最基础的 GRPO 算法,唯一的改动点就就是移除了 response 的长度归一化项 来减轻长度偏差,这个技巧以及下文会提到的 clip_higher 技巧都在 DAPO 论文里有讲。
基础知识我也就不再多赘述了,有疑惑的话可以再翻翻 PPO、GRPO、DAPO 的论文。
多阶段训练
llm 自从进入 long cot 阶段之后,4k、8k 基本就是过家家了,32k 已经是 post training 的入门级长度了 —— 这极大的增加了 R1 的算力需求。文章的作者别出心裁,提出可以把 R1 的训练分为多阶段进行:先训 8k,等模型的效果快收敛了,再训 16k …… 以此类推。
先训 8k,再训 16k 是一种听上去就不太对的做法。毕竟超长的 response 会在训练中被视为负例,训 8k 的时候很可能让模型学的不再出更长的 response,失去解决复杂问题的能力,等到再训 16k 的时候就啥也学不到了。
★R1 涉及到的一个特殊概念是“模型的提升空间”,举个例子:学生 A 完全掌握了“反证法”且只会使用该方法,在低年级阶段成绩很好,但在高年级阶段遇到更复杂的问题的时候,却完全学不会;学生 B 则是同时学习了“反证法”、“归纳法”、“构造法”等,由于学的不深,在低年级的的时候成绩不是很理想,但高年级接触更多知识的时候,往往能学的更快。所以衡量一个策略好坏的标准,一定不仅仅是当前 step 的得分,而是要看远点,看看更多 step 下的趋势变化。
文章里并没有在原理上解释多阶段训练为什么具有可行性,只是默默的把消融实验的结果抬了出来:一直训 16k 的蓝线和先训 8k 再训 16k 的黄线,最终会在测试集合取得相同的效果。那么在这种情况下,多阶段训练的优点就彰显出来了:
节省算力,具体看下图的左图,相同 gpu 卡时的情况下,多阶段训练的模型效果始终处于领先地位; 提高 token efficiency,也就是让模型少说废话。这一点是很有意义的,现在的 long cot 模型(以 R1 为代表),无意义的废话确实很多。初始阶段不要用过长的输出,说不定真能让模型少说一些“让我好好想一下”这种无意义的 token。(不要因为现在流行 long cot 就忘了大模型是按照 token 数量收费的, 如果效果一样,输出短的模型一定是更好的模型 ) Preserve Scaling Potential,也就是模型还能训回去,response 在后续训练中依然能稳定提升,模型的上限没有被削减。(感觉实验不充分,个人持小小的怀疑态度)

说句题外话,就我的视角而言, post training 最关键的并不是 sft 和 r1 谁更重要,恰恰就是 multi_stage 的设计 。既可以是多阶段的 sft,也可以是多阶段的 r1,亦或者是相互交叉的多阶段。不同 topic 的多阶段,不同任务难度的多阶段,不同训练方法的多阶段,不同 seq_len 的多阶段等等,都需要做实验去设计,也往往都能让模型的效果有所提升。
pretrain 的技术方法正在全面入侵 post training(退火、课程学习、多阶段训练 ……)。
针对截断的 advantage mask
承接上文,文章继续讨论了“response 截断的数据到底该不该作为 r1 阶段的负例”。
在 8k 的训练设置下,模型初始截断比例非常高。如下图所示,训练初期(0-100 步),准确率的升主要是由于截断比例的急剧下降。在 100 步之后,算法开始提高非截断 response 的准确率。

从数学的视角出发,模型的优化目标有两个变量: ,分别代表非截断的概率,和非截断时的期望 reward。很显然,我们不是很在乎截断率,我们希望模型在训练中主要聚焦在提高非截断时的期望 reward。那么,这就需要设计一些 advantage mask 策略,来修正模型的优化目标。
针对 advantage mask,一共有三种策略:
no mask:无任何 mask advantage_mask_before:截断 response 不参与 group 内的 advantage 计算,这些截断 response 的 advantage 设为零。公式中 是非截断的 response, advantage_mask_after:截断 response 参与 group 内的 advantage 计算,这些截断 response 的 advantage 设为零 。公式中 是所有的 response,
三种策略的消融实验从下图可以看到具体情况:
图 a 是截断比例,能发现 advantage_mask_before 策略变化明显; 图 b 是训练准确率,advantage_mask_before 策略准确率下降,no mask 和 advantage_mask_after 两个策略都能稳定上升; 图 c 是非截断数据的准确率,advantage_mask_before 最高,no mask 最低,但是和 advantage_mask_after 的趋势一样,都是先降再升。
advantage_mask_before 策略的表现非常特殊:非截断 response 的准确率有所提升,整体的训练准确率却持续下降,且截断比例稳步上升。这种现象应该是一种典型的 reward hacking —— 我不知道这道题会不会写,我只要告诉老师说题目“超纲”了就不会被批评。
最终,advantage_mask_before 策略因为试图作弊,率先出局。

进一步的,我们来看下不同策略训出来的模型在更长的 response_len 下的表现(此时基本上不存在截断问题了)。下图的曲线很明显的说明了, 黄线 no mask ≈ 红线 advantage_mask_after > 绿线 advantage_mask_before。
注意下图中的紫线,应该是在 no mask stage1 基础上做了 stage2 (更长 response_len)训练的模型,说明第一阶段学到的较短的 response 完全没影响模型的上限,第二阶段的 response_len 和 accuracy 仍然能稳步提升。
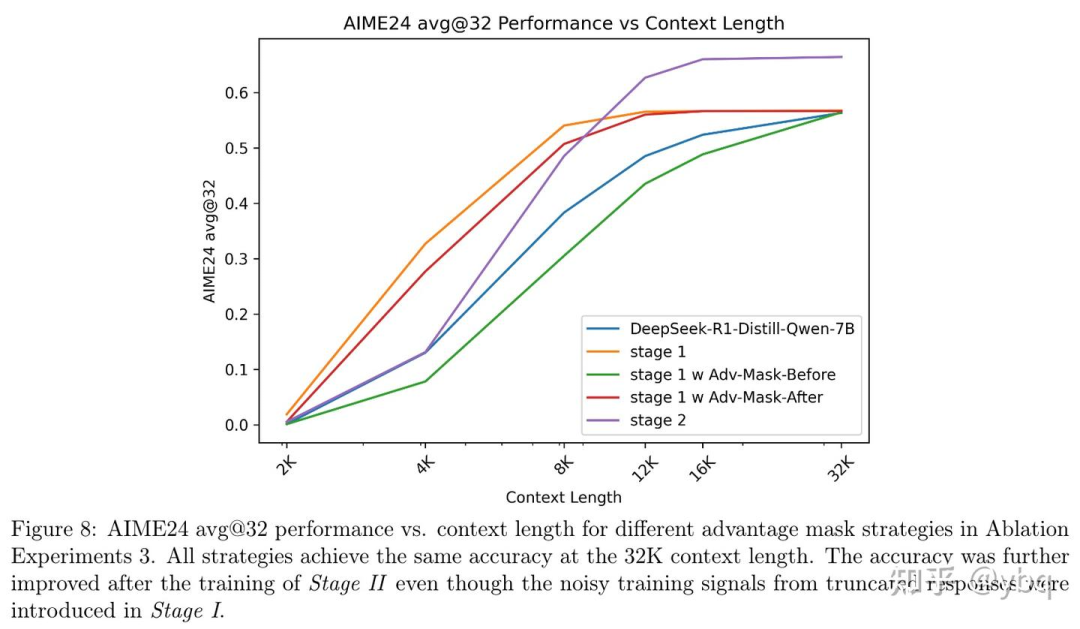
在更大的推理 response_len下,advantage mask 技巧并不能带来更优秀的性能。第一阶段不使用 advantage mask 的模型,在第二阶段扩大 response_len 之后,依然能提高 accuracy,并且显著优化了 token efficiency。 如无必要,勿增实体 ,作者选择不做 advantage_mask。
高温采样
GRPO 的分组特性意味着 response 的采样过程会直接影响每个 group 的质量和多样性,进而影响模型的训练效果。如果采样的温度过高,随机性过大,可能会导致“全错 group”出现的概率,进而影响训练效率;采样温度过低,则会降低 group 内的多样性,增加“全对 group”出现的概率。
针对采样温度,文章做了一个消融实验,基本结论是:高温采样的模型效果更好。 较高的温度显著增强了早期阶段的学习信号,并为后续训练保留了更大的潜力 。同时,高温采样初始的熵也更大, 衰减也更慢。(图中的熵之所以降到 0.2 就不再降低了,是因为作者加了熵 loss 来阻止进一步下降)

自适应熵控制
文章指出,熵坍缩会严重影响模型的效果。所以希望在 r1 的过程中抑制熵的快速下降。提出的做法就是引入一个熵 loss,来把熵控制在某个值附近。
这个熵 loss 的系数 是动态调控的,为此需要引入两个额外的超参数:
:期待模型的熵稳定在这个值附近; :熵损失系数的调整步长。
在第 步更新的时候,actor model 的熵记为 ,如果它小于 ,就把熵 loss 的系数 加上 ,大于则减去 ,这个策略只在 时生效。具体的公式为:
关于熵的讨论是这篇文章最精彩的地方,下文会详细解读,这里就不多提了。
KL Loss
训到一定阶段后,KL_loss 会将 actor model 的策略拉到和 reference model 一致,导致 KL_loss 下降至接近零。同时,模型在测试集合上的性能也基本不会再提升了。所以文章里的实验也都不再加 KL_loss 了。
如图,KL_loss 初期基本没影响,训得久了之后(750 step 往后)就让模型训不动了。KL_loss 一直以来被诟病的就是“reference_model 为什么不定期更新一下”。都过了几千、几万step 了,还要被原始的模型来约束,非常不合理,现在很多强化工作确实也都选择不用 KL_loss 了。

缓解策略熵坍缩的探索
名词解释
,即 rollout batch size:每次使用的 prompt 数量 ,即 mini batch size:每次模型进行参数更时新使用的 response 数量 ,即数据复用:每次 rollout 产生的 response 的使用次数 ,即 group size:每条 prompt 生成的 response 数量 :response 的最大长度 :temperature :在一次 rollout 数据的情况下,对模型的参数进行多少次更新。该数值等于 1 即为 on-policy,大于 1 即为 off-policy。特别的, on-policy:所有参与训练的 response 都是模型自己生成出来的 off-policy:参与训练的 response 可能是较早时期的模型生成出来的
on-policy 和 off-policy 的区别,主要体现在对数据的使用上,off-policy 的训练效率会明显更高一些。一方面,off-policy 可以不等所有的 response 生成完毕,就启动模型训练;另一方面,off-policy 可以多次使用同一条数据,提高数据利用率,on-policy 则不可以。

核心论点:过早的熵坍缩会导致模型效果差
“过早的熵坍缩会导致模型效果差,强化训练中引入熵 loss 能明显缓解熵坍缩的速度”属于文章的核心观点,关于熵的所有讨论和实验也都是围绕这一观点进行的。文章里通过一个对比实验来支撑该观点:
蓝线引入了 1e-3 的 熵 loss,熵坍缩的比较快,模型的测试效果差; 黄线引入了 5e-3 的 熵 loss,熵坍缩的比较慢,模型的测试效果好。
个人觉着,文章里对该论点的证明有点单薄了,baseline 缺少一个不加熵 loss 的曲线,实验也不是那么充分。虽然目前大部分人都认可 “ 熵低 = 模型输出多样性差 = 强化的探索空间小 = 强化效果差 ” 这一观点,但其实还是缺少一些系统性的分析和证明的,毕竟 entropy 和 diversity 并不能完全划等号,也有很多强化的工作完全无视对熵的控制。

rollout 多样性对熵的影响
既然熵对模型的效果影响很大,那哪些因素能影响熵呢?首先是 rollout 的采样阶段,文章分析了这几个超参数: , ,temperature。实验结论如下图所示,在 on-policy 的情况下, 和 怎么调整都不会出现快速熵坍缩。
至于 Temperature,上文提到过:使用适当选择的较高温度,在训练初期会导致较差的测试性能,但最终能带来更大的性能提升。

对熵的影响
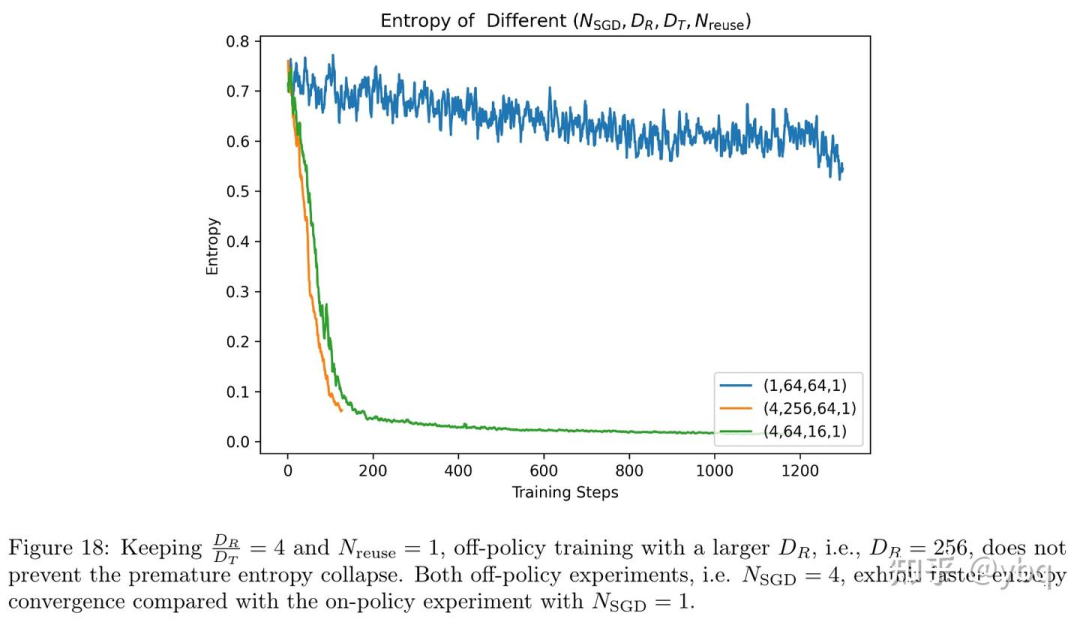
对 的分析,其实就是对 off-policy 和 on-policy 的分析。文章通过三组消融实验给出了一个结论: on-policy 在任何情况下都好于 off-policy 。
实验 1: 相同的 rollout 配置下,off-policy 容易熵坍缩,on-policy 不易熵坍缩 。下图中,只有蓝线的 on-policy 没有快速熵坍缩,自然而然效果也更好了。

实验 2 : on-policy 可以用更少的训练数据,达到比 off-policy 更好的效果 。重点观察下图的红线和黄线,红线每一步训练使用了 64 条 prompt,而黄线是 32 条 prompt。模型效果上,红线初期是明显压着黄线的,但在 1500 step 左右,红线训不动了,黄线还在上继续涨。

实验 3 : 即使增大 rollout 的数据量,也无法阻止 off-policy 的模型快速熵坍缩 。黄线和绿线的趋势完全一致,即使黄线的 rollout 数量有 256 条之多。
如何防止熵坍缩
总结下前文关于熵的讨论,大概可以概括为下面这几个观点:
熵坍缩就会导致模型效果差; 只要不是 on-policy,模型必然会快速熵坍缩,调整任何其他参数都没用; off-policy 能大幅度提高训练效率以及数据的利用率,不可能完全舍弃,尤其是“异步训练框架”的使用就离不开 off-policy 的训练策略; 即使是 on-policy,也只是缓慢熵坍缩,并不能从根本上防止熵坍缩。
气氛都铺垫到这儿了,那肯定要讨论下如何防止熵坍缩呗。文章给出了两个方法来防止熵坍缩: 加入熵 loss 和 clip higher 技巧 。
先说熵 loss,这个非常直接,让模型直接朝着熵增的方向学习呗。此处必须提一句的是,语言模型的训练是朝着熵减的方向去优化的,所以 熵 loss 和语言模型 loss 是两个截然相反的优化目标,把它们揉杂在一起是一个很反直觉的行为。
★有没有感觉强化学习很拧巴,既希望模型朝着某个分布去学习,又怕模型过于拟合某个分布导致没有训练空间。我是感觉这也能从侧面说明, pretrain 阶段是在学习人类语言分布,而 posttrain 阶段只是在调整模型学到的人类语言分布
言归正传,下图充分说明了熵 loss 不是随便加的,加大了模型直接崩溃,加小了又没作用。

除此之外, 熵 loss 对训练数据也很敏感 ,相同参数配置下使用不同的数据,会得到完全不同的趋势。(这里其实可以更细致的探究一下,两份数据的 response 多样性到底差别多大,比较一下 response 的熵的平均值,也许能给出一个近似的拟合公式:“熵在多大的区间内适合多大的 loss 系数”)

文章读到这里我觉着作者的意图已经很明显了,深度学习的惯用伎俩: 当一个参数同时兼具 significant 和 sensitive 两个属性的时候,那不妨就给它补充一个 dynamic 属性。 也就是文章前面介绍过的动态调整熵 loss 系数的方法。
需要注意的是,当 较大的时候,自适应系数也控制不了熵。文章推测是因为“熵损失是基于整个词汇表计算的,这可能会增加许多非预期 token 出现的概率”。因此,只推荐 的情况下使用自适应的熵控制。

再说另一个技巧,DAPO 论文里已经讲过的 clip higher,认真读下 DPAO 论文里的分析过程就好啦,这已经快属于强化学习的常识之一了。
如下图所示,clip_higher 之后,熵坍缩显著放缓,模型在测试集表现更好。但是不能设置的过高,比如图中的红线 0.28。有意思的是,红线的 0.28 恰恰是 DAPO 原始论文中的推荐值,所以这说明 clip higher ratio 也是严重依赖于数据的(既然熵 loss 都动态调控系数了,干脆 clip higher ratio 也动态调算了)

训练资源分配的探索
训练资源分配问题是 qwen、seed 不太会探讨的一个话题,因为他们并不缺卡,但对普通团队来说资源分配确实是搞强化实验的命门所在。
首先明确下 r1 的训练时间: ,分别代表 data rollout 的时间,policy update 的时间,以及其他操作的时间(reward computation,experience generation),更具体地说:
的主要影响因素是 rollout batch size ( )和 group size( ) 的主要影响因素是 随机梯度下降(SGD)的步数( )

policy update 的耗时
毋庸置疑, 是 的大头,因此可以合理做出判断:适当增加每次 rollout 时的 ,可以在几乎不增加 的情况下提高训练效率(这里很好理解,一次 rollout,多次 policy update 自然是能让模型学的更多)。下表也证明了这个假设,一次 rollout,更新四次模和更新一次模型相比,仅仅增加了 3% 的耗时。

但是前面的实验提到过,off-policy 会加剧熵坍缩。因此,不建议仅仅为提高训练效率而增加 ,除非有适当的机制来缓解熵坍缩。
rollout 的耗时
现在考虑如何减少生成时间 。如下表所示, 主要由 batch size 和生成最长的那条 response 所需要的时间来确定。 在计算资源充足的时候,增加生成阶段的 gpu 数量并不能明显降低最长的那条 response 所需要的时间,也就不能大幅度减少生成阶段的耗时 。

也就是说,当有了更多的训练资源用来做生成阶段的推理,完全不调整超参数带来的收益是比较小的,这就是个木桶效应,更多的卡也没办法解决最长那条 response 对应的耗时。最好的办法是,增加卡数量的同时,也增大 rollout batch size 或者 group size, 通过利用更大的 rollout buffer,来获得更精确的梯度估计 。
长话短说,论文做了一些简单的消融实验,结论大概是: rollout batch size 越大,模型在测试集上的表现越好;group size 越大,模型在测试集上的表现越好。 具体效果详见下面两张图。

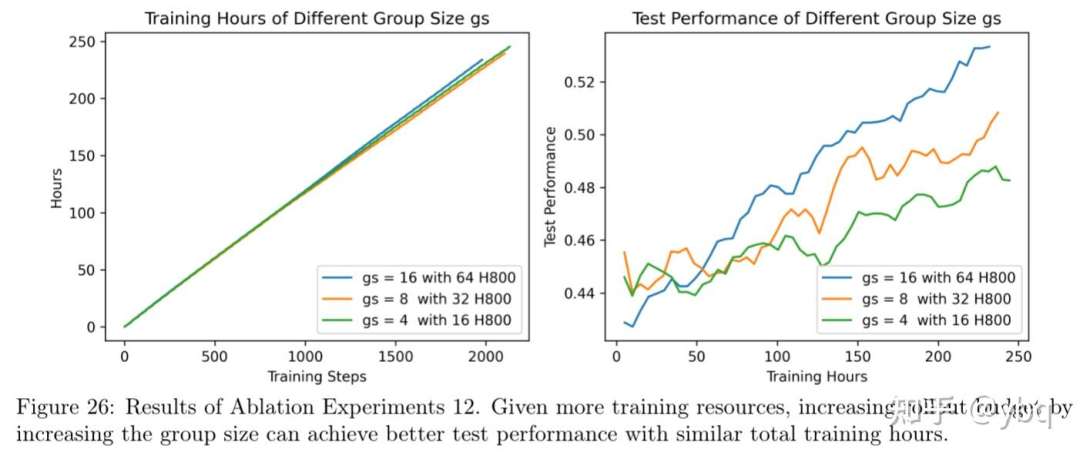
其他
文章还有一些内容,诸如:训练数据如何清洗,math 任务的 verifier 怎么设计,code 任务的 sandbox 怎么搞等等。感兴趣的同学自己去读读吧(显然我不感兴趣哈哈),我就不再解读了。
最后总结一句,r1 的实验结果和底座模型能力、训练数据、训练 topic 息息相关。大家都知道 qwen 底座模型训过很多的题,那它就很容易在学习数学题的时候熵减过快,就会依赖文章里讲的控制熵的技巧。也许 llama 模型的做题能力较差,也就完全不需要考虑文章对熵的各种分析。
我们学习的是文章作者在尝试稳定 r1 训练的思考过程和实验设计(尤其是消融实验的动机和分析),而不是一昧相信文章里给出的实验结论。
大模型之心Tech知识星球交流社区
我们创建了一个全新的学习社区 —— “大模型之心Tech”知识星球,希望能够帮你把复杂的东西拆开,揉碎,整合,帮你快速打通从0到1的技术路径。
星球内容包含:每日大模型相关论文/技术报告更新、分类汇总(开源repo、大模型预训练、后训练、知识蒸馏、量化、推理模型、MoE、强化学习、RAG、提示工程等多个版块)、科研/办公助手、AI创作工具/产品测评、升学&求职&岗位推荐,等等。
星球成员平均每天花费不到0.3元,加入后3天内不满意可随时退款,欢迎扫码加入一起学习一起卷!

 扫码添加微信
扫码添加微信
- 点赞 0
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊





