


世界AI看中美,中美AI看路线:中国AI用「小米打法」釜底抽薪,基础模型或将免费
- 2025-07-31 14:27:34
核心观点:商业策略的终局,由市场决定。
GRACE SHAO
2025 年 7 月 29 日
中美正进行一场不同的人工智能竞赛
上周三,白宫发布了《人工智能行动计划》,这是一份旨在构建国家级 AI 创新生态的蓝图。
这是一场命运的赌博,赌的是智能一旦被唤醒,就将彻底重塑世界秩序。
而中国没有追逐虚无缥缈的命运。它选择了一条务实的路:快速、低成本地部署开放权重的模型,并将其深度融入经济的毛细血管。
这种务实,反而让华盛顿感到不安。中国的实验室如今能更快、更便宜地推出基础模型,而且最关键的是,他们选择公布模型权重。
在硅谷看来,这无异于自毁长城,严重威胁了他们依赖模型层专利保护的盈利模式。
但在中国,这套逻辑是反过来的。一旦模型沦为像水电煤一样的商品,真正的利润就会转移到应用层。
开放权重,恰恰加速了这一天的到来。免费的开源版本和针对不同行业的微调模型大量涌现,每一个新应用,都在为模型的源头开发者带来源源不断的需求。
必须明确,这不是两国政府在背后指导的宏大战略。这纯粹是市场驱动的结果。
它由芯片、资本、分发渠道这三股结构性力量共同塑造,最终让「开放权重」成了通往商业价值最现实的入口。
今天,我将剖析为何中美看似在同一赛道,实则奔向不同终点,希望能提供一个全新的观察视角。
部署 vs. 命运
中美科技公司真正的分歧,在于他们对「利润最终来自哪里」的判断。
中国押注应用,美国押注模型本身。
硅谷痴迷于由模型主导的命运——追求更大的参数、更高的安全基准,以及近乎宗教狂热般地奔向通用人工智能。
在《人工智能帝国》一书中,Karen Hao 记录了山姆·奥特曼等硅谷精英的信念:通用人工智能是改变世界、解决人类终极挑战的唯一答案。
这是一场长线、烧钱且封闭的豪赌。今天,他们将数十亿风险投资砸进持续亏损的模型研发;为的是明天,能拥有那个重塑所有行业的超级平台。
中国的打法则实际得多。这种务实精神,源于其竞争惨烈的消费互联网,那里信奉的是「部署为王」的生产力法则。
无论是微信还是抖音,诞生之初都没有清晰的盈利模式。先不计成本地抢占市场份额,这是深植于中国互联网人骨子里的打法。
通过尽早开放模型权重,中国的 AI 实验室能迅速吸引海量开发者。一旦消费者用上了瘾,日后再想更换的成本将极其高昂。
创业者们则能把这些强大的开源模型,当作免费的开发脚手架。
以电动车行业为例,比亚迪、吉利、长城等二十多家车企,已将 DeepSeek 模型集成到车载 AI 系统中,用以提升智能助手和自动驾驶体验。
在医疗领域,据说全国已有近百家医院,开始使用 DeepSeek 模型进行医疗影像分析和辅助临床诊断。
每一个新集成,都在扩大模型的地盘,都在增加用户的转换成本,最终将利润导向构建于模型之上的各种服务。
开源背后的三股推力
因此,中国所谓的「开源战略」,本质上是一场商业上的务实选择,而非什么地缘政治的大棋。
要理解这种务实为何偏偏以「开源」的形式呈现,就必须看清背后那三股无形的手——芯片、资本和分发渠道——是如何将开放变成了默认选项。
芯片稀缺
自 2022 年 10 月起,美国的出口管制,让中国的模型公司再也无法获得英伟达最新的高端 GPU。
这意味着,无论中国愿不愿意,「砸钱、堆算力、冲向通用人工智能」的暴力美学玩法,已经彻底出局。
中国的实验室,只能依靠手里有限的上一代英伟达 GPU 和国产芯片修修补补,在硬件上比美国落后至少一到两年。
既然算力有了天花板,能效就成了唯一的出路。中国研究员的核心任务,变成了从有限的硬件中榨出极致的性能。
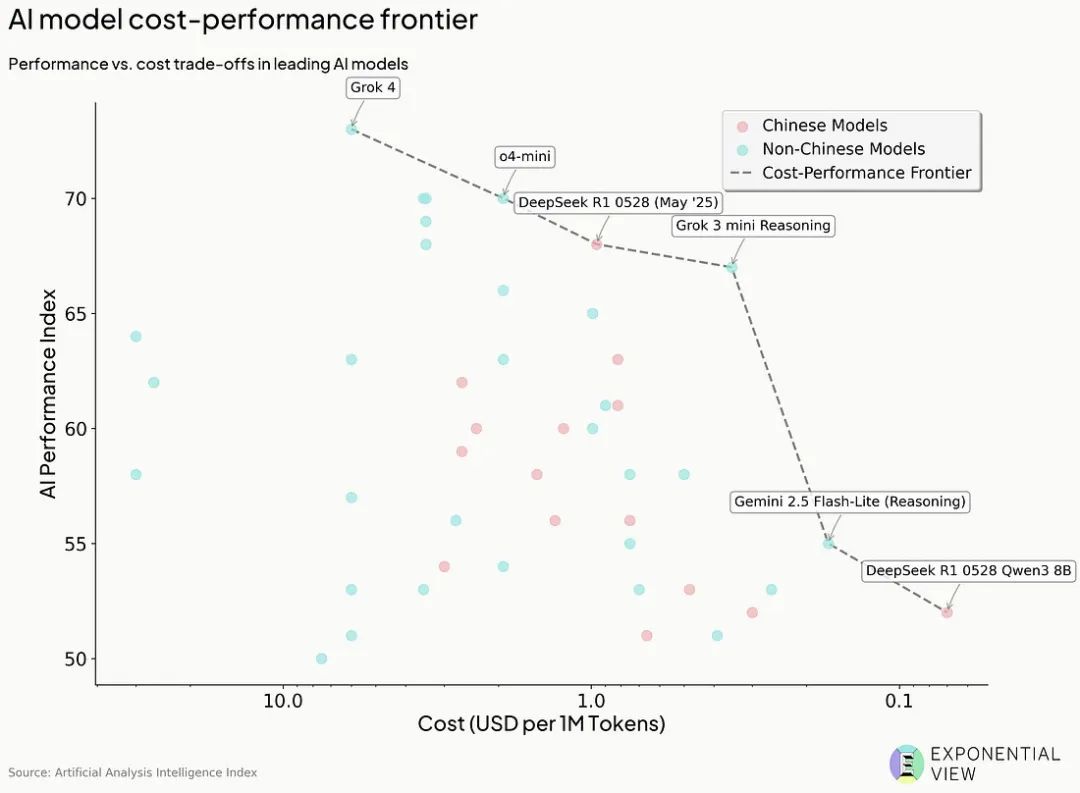
结果是,DeepSeek V3 模型以低 18 倍的成本,实现了与 GPT-4o 相当的性能。月之暗面的 Kimi K2 模型,则通过一项新技术,可能将训练所需的算力消耗直接减半。
美国的芯片封锁,无意间把中国的模型倒逼成了性价比之王。
如今,中国的模型竞争力如此之强,以至于国内外众多公司都希望能基于它们进行开发。
资本寒冬
追求极致效率,同样也符合残酷的商业现实。
风险投资极度稀缺,加上内心深处急于证明自己是「创新者」而非「模仿者」,中国的创始人们必须用最快的速度证明自己的价值。
模型被用得越多,护城河就越深,名气也越大。这是中国 AI 区别于美国的一个显著特征,背后是远比美国紧张的融资环境。
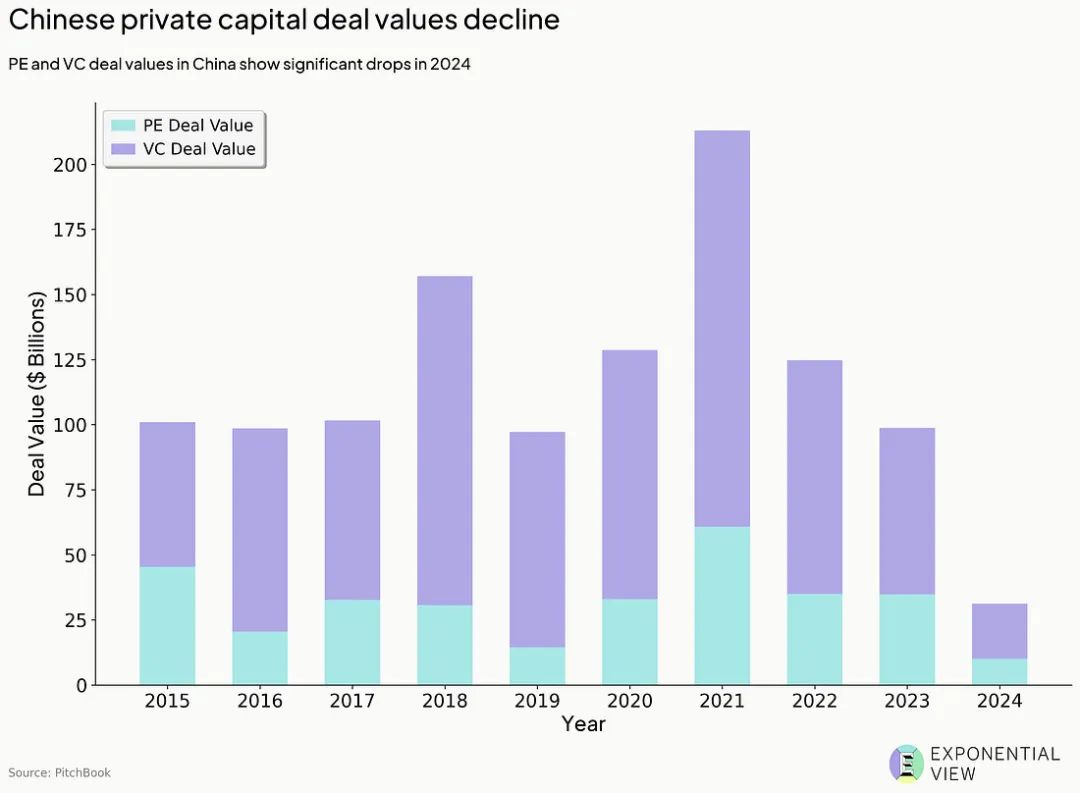
2025 年上半年,美国风投向 AI 领域砸了 1000 亿美元。而同期,中国所有行业的初创公司加起来,才勉强拿到 110 亿美元。
自从网约车巨头滴滴 2022 年从纽交所退市,一场监管风暴席卷了整个互联网行业。
一些美国基金撤离中国,连本土基金也变得小心翼翼。美国政府更是出台规定,禁止本国投资者涉足中国的 AI 和芯片领域。
相比十年前互联网的黄金时代,如今的中国 AI 创业者,必须先拿出能用的产品和实实在在的用户数据,才有可能敲开投资人的大门。
中国的模型虽然高效,但据估算,仅「DeepSeek」一个模型的研发总投入就超过了 5 亿美元。幸运的是,它由对冲基金巨头梁文锋自掏腰包。
但其他创业公司呢?看看被称为「AI 四小龙」的百川智能、智谱 AI、月之暗面和阶跃星辰,他们绝大多数都依赖于 BATJ(百度、阿里、腾讯、字节)等巨头的输血。
百川和智谱,正是通过发布强大的开源模型,向阿里和腾讯证明了自己有交付能力、能聚拢起开发者生态,才在代码开源之后,拿到了数亿美元的巨额投资。
分发瓶颈
当一个模型公司已经小有名气,又是什么力量让他们坚持开源呢?
答案是,中国独特的移动互联网生态。
一个典型的中国用户,每月真正频繁打开的应用不超过 10 个,而这些应用的流量入口,几乎都被微信和支付宝牢牢卡住。在美国,这个数字是 30 个。
在这种环境下,谁能最快地将自己的模型塞进那几个关键的流量瓶颈,谁就能赢得市场。这甚至导致了一些在外人看来非常“反常”的决策。
以腾讯为例。微信团队急需一个好用的大模型,而腾讯自家的 AI 部门「元宝」则力推自己的闭源引擎。
最终,微信团队直接绕过了内部,接入了外部的开源对手「DeepSeek」模型。原因无他,只因它比内部的更好用。这是腾讯内部典型的产品经理文化,为了用户体验,产品负责人的话语权有时大过公司管理层。
当然,阿里和字节的风格不同。公司最高层会亲自挂帅,调集最顶尖的工程师集中攻坚。
除了人尽皆知的 996,为了打磨一个聊天机器人,团队在办公室连续奋战七天不回家,说实话,早已是常态。
在这样的高压竞争下,开源就成了一种增长黑客手段:没有授权费,可以即插即用,还能引发病毒式的二次创作和传播。巨头们想要的是市场份额,而开源,是通往这个目标最短的捷径。
说到底,这也不完全是商业策略。驱动中国企业家拥抱开源的,还有一股不服输、渴望证明自己的劲头。
几十年来,中国制造被贴上山寨的标签。许多 AI 创始人和顶尖学者,选择开源自己的研究,就是想向世界证明中国的创新能力。
这种心理因素绝不能被低估。开源与闭源的路线之争,在科技史上源远流长。
支持开源者,相信更严苛的审视和更广泛的采用,能加速技术的进步。而支持闭源者,则更看重保护自己的专有知识。
中国政府本身,其实并不太在意企业是否选择开源。
政府的目标,是通过五年计划等宏观政策,确保 AI 技术能渗透到经济的每一个角落,服务于国家发展。
真正将开源推到中国 AI 生态系统中心的,是企业家的理念,与现实的结构性力量相结合的必然结果。
“[注:关于政府层面推动人工智能和机器人发展的努力,可以通过“中国制造 2025”、“东数西算”等计划了解更多。这些顶层设计的目标主要包括:1) 加速创新与自力更生;2) 提升全球竞争力;3) 推动关键行业(如制造、交通、医疗、农业)的转型升级;4) 这些举措在提振经济的同时,也可能带来地区发展不均等社会经济影响。]
这不是同一场比赛
最后,我想再次强调,中国和美国,跑的根本不是同一场比赛。
「部署」是中国正在收获的红利,而「命运」是美国仍在追逐的梦想。 双方都在追逐自己最看重的东西。
中国公司将开源模型快速融入大众生活,因为在应用层,速度就是一切,回报来得最快。
硅谷则将巨额资本倾注于更庞大、更封闭的模型,希望能率先抵达通用人工智能的彼岸,尽管没人说得清那究竟是什么。
中国的模型开发者,只是在理性地适应他们所处的环境。
芯片的限制,奖赏了效率;资本的结构和市场的逻辑,则将他们推向了开放。
请不要误解,中国当下的开源战略,是市场自发形成的,而非国家主导的。
它无比务实。正如一句中国老话所说:
兴趣,是不能当饭吃的。
在中国,即使是人工智能,也必须先证明自己能挣钱。
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
 扫码添加微信
扫码添加微信








