


跳出 Sora 的"像素陷阱"!LeCun 团队 DINO-world 诠释世界模型的正确方向
- 2025-07-30 08:00:00
点击下方卡片,关注“大模型之心Tech”公众号
>>点击进入→大模型技术交流群

在AI领域,Yann LeCun的名字几乎等同于世界模型的代言人。
这位Meta首席科学家、图灵奖得主近年来不断强调:单纯依赖语言模型永远无法实现真正的智能,AI必须学会像人类一样理解物理世界、预测未来变化。
他甚至在公开场合多次炮轰当前大热的生成式视频模型(比如OpenAI的Sora),直言它们华而不实——能生成逼真画面,却连基本的物理规律都搞不清楚。
“这些模型就像好莱坞特效师,能渲染出漂亮的爆炸场景,但根本不懂爆炸背后的动力学原理。”LeCun的批评直指生成式AI的核心痛点:缺乏对世界的因果建模能力。在他看来,Sora这类模型虽然能生成以假乱真的视频,但本质上只是「模式匹配大师」,通过海量数据记住像素的统计规律,而非真正理解场景中的物体如何运动、碰撞或相互作用。

那么,什么才是真正的世界模型?

就在不久前,LeCun团队用新论文《Back to the Features: DINO as a Foundation for Video World Models》给出了自己的答案——DINO-world,一个基于DINOv2视觉编码器的视频世界模型。与Sora的像素生成路线截然不同,DINO-world选择了一条更「抽象」却更高效的路径:直接在语义特征空间预测未来。
实验结果令人惊艳:
物理常识碾压:在「直觉物理」测试中(比如判断物体是否会违反重力悬浮),DINO-world准确率远超Sora同架构模型,甚至接近人类水平;
效率革命:训练成本不到生成式模型的1/10,却能实现更精准的长期预测;
控制即插即用:只需简单添加动作模块,就能让模型学会规划机器人运动轨迹,通用性远超专用控制模型。
这或许正是LeCun心中世界模型的雏形——不追求华丽的像素级渲染,而是专注于学习世界的底层规律。
为什么像素预测是条弯路?
传统视频生成模型如SORA、COSMOS等,往往执着于生成逼真的像素级未来帧。这种方法虽然能产出震撼的视觉效果,却存在难以克服的效率瓶颈。COSMOS模型使用120亿参数,训练耗时高达2200万GPU小时,却仍在简单物理推理任务中表现挣扎。问题的核心在于:像素级预测包含了太多无关细节——一片落叶的飘动、阳光的细微闪烁,这些对高层决策毫无意义的信息消耗了模型的大部分能力。
Meta团队的洞察直击要害:智能系统需要的是对场景语义和物理规律的理解,而非像素级复刻。人类驾驶时不会计算每块路面的颜色变化,而是关注车辆、行人的运动趋势;机器人抓取物体时,重点是判断物体的受力平衡点,而非表面纹理的反光。DINO-world选择在DINOv2预训练模型的潜空间中进行预测,正是抓住了这一本质。
DINOv2作为当前最强大的自监督视觉模型之一,已经通过海量图像学习到了丰富的语义和几何特征。一个简单的例子可以说明这种优势:当处理一段行车视频时,DINOv2的潜空间特征会自动聚焦于车辆位置、车道线、交通信号灯等关键元素,而忽略车窗上雨滴的随机运动。在这种"语义提纯"的空间中学习预测,模型能更高效地捕捉到真正重要的时间动态。

架构解析:潜空间预测的精妙设计

DINO-world的架构设计围绕三个核心原则展开:分离视觉编码与动态学习、支持灵活的时空尺度、便于行动条件微调。这种设计使其在保持高效性的同时,具备了出色的泛化能力。
冻结编码器与预测器的分工是第一个关键创新。模型采用预训练的DINOv2 ViT-B作为图像编码器,将每帧图像转换为14×14的 patch 特征(768维)。这个编码器在训练过程中保持冻结,确保了语义特征的稳定性。预测器则是一个由40个交叉注意力块组成的Transformer模型,专门学习如何从历史特征预测未来特征。这种分工避免了联合训练的复杂性,也让模型能充分利用DINOv2已有的视觉知识。
在处理时空信息时,DINO-world引入了三维旋转位置编码(RoPE),这是其第二个设计亮点。与传统位置编码不同,RoPE将时间戳(秒级)和空间坐标(归一化到[-1,1]范围)通过三角函数编码到注意力计算中。这种方式让模型能自然处理不同帧率(10-60 FPS)和分辨率的视频,无论是手机拍摄的竖屏短视频,还是监控摄像头的横屏录像,都能保持一致的时空推理能力。实验显示,这种编码方式使模型在跨分辨率预测任务上的误差降低了15%以上。
行动条件微调机制体现了模型的实用性设计。在预训练阶段,DINO-world是一个无条件模型,仅通过视频帧学习世界动态;而在需要控制任务时,只需在每个Transformer块后添加轻量级行动模块即可。这些模块初始化为恒等映射(零初始化),通过少量带行动标签的数据就能快速适配。相比从头训练行动条件模型,这种方式使规划任务的成功率提升了20%-30%。
训练过程中的时间采样策略同样值得关注。为了避免模型偏向短时间预测,研究团队采用了均匀采样时间间隔(Δτ)的方法。在6600万段视频(每段5-60秒)中,模型并非简单取连续帧,而是随机采样T-1个时间间隔,确保对不同时长的动态都能有效学习。这种策略使模型在500ms中期预测任务上的表现远超采用连续帧训练的基线模型。
性能验证:横跨六大任务的全面优势
Meta团队设计了迄今为止最全面的世界模型评估体系,涵盖密集预测、物理推理、规划控制等六大类任务,充分验证了DINO-world的泛化能力。

在语义分割预测任务中,DINO-world展现出惊人的精度。在VSPW数据集上,预测0.5秒后的场景分割时,其mIoU达到47.0,比次优模型高出6.3个百分点。更值得注意的是,随着预测时间延长,其性能下降速度明显慢于其他模型——在Cityscapes数据集中,0.5秒预测的mIoU仍保持在55.1,仅比当前帧预测低13.5个点,而COSMOS模型在此场景下的性能下降高达22.4个点。这表明潜空间预测能更好地保持语义一致性。


深度预测结果进一步印证了模型的几何理解能力。在KITTI数据集上,DINO-world的短期(200ms)预测RMSE为3.214,优于COSMOS的4.157和V-JEPA的5.458。这种优势在复杂场景中尤为明显,例如在雨天路面的深度估计中,模型能更好地保持车道线和车辆轮廓的深度连续性,这对于自动驾驶等安全敏感任务至关重要。
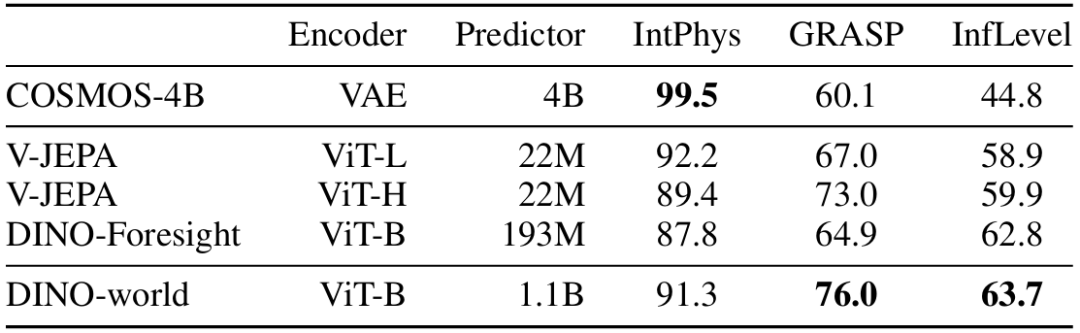
在物理推理三大基准测试中,DINO-world的表现同样亮眼:
IntPhys数据集(评估物体恒存性等基础物理概念):91.3%准确率,超过V-JEPA ViT-H模型 GRASP数据集(测试实体连续性等进阶物理知识):76.0%准确率,在物体永久性测试中达到100% InfLevel数据集(考察重力等物理规律理解):63.7%准确率,尤其在连续性推理上领先12个百分点
这些结果表明,通过大规模视频预训练,模型确实能自发学习到直观物理知识。一个有趣的发现是,DINO-world在"物体不会凭空消失"这类任务上表现接近完美,但在处理复杂碰撞动力学时仍有提升空间,这与人类婴儿的物理认知发展路径惊人相似。
消融实验揭示了关键设计的重要性:

模型规模:从86M参数(Base)到1.1B参数(Giant),IntPhys准确率提升5.7个点,证明更大的预测器能捕捉更复杂的动态 训练数据:使用66M视频的模型比仅用Cityscapes数据集的版本性能高30%以上,验证了数据多样性的价值 编码器选择:DINOv2相比SigLIP2和Stable Diffusion VAE,在所有任务上领先8-40个点,凸显语义特征的优势
从预测到规划:潜空间模型的实用价值
世界模型的终极价值在于赋能智能体的决策与控制。DINO-world在三个规划任务中的表现,展示了潜空间预测模型在实际应用中的巨大潜力。
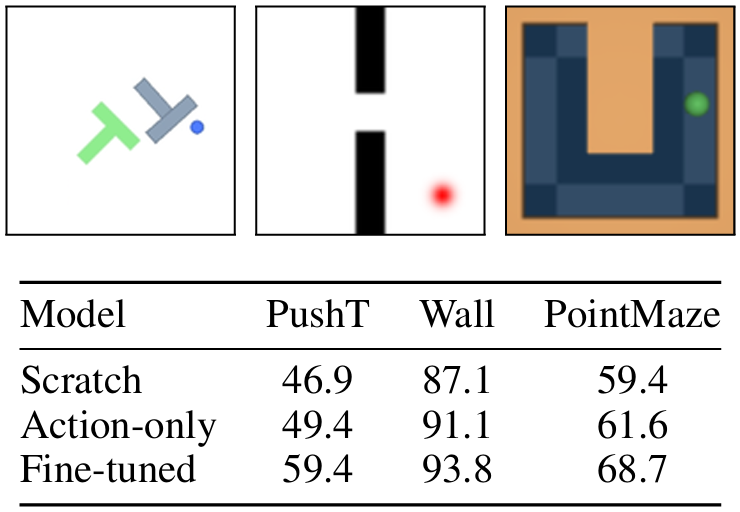
在PushT环境中(机器人推动T型块到目标位置),经过微调的DINO-world成功率达到59.4%,远超从头训练的模型(46.9%)。这得益于预训练阶段学习到的物体运动规律,使模型能快速适应具体任务的动力学特性。值得注意的是,即使仅冻结预训练参数,只训练新增的行动模块,也能达到55.2%的成功率,证明了预训练知识的可迁移性。
Wall环境(智能体导航穿过门)的测试结果更为显著:DINO-world的成功率高达93.8%,接近人类专家水平。分析显示,模型在规划时会优先关注门的位置和自身运动方向,这正是DINOv2语义特征引导的结果——在潜空间中,门的特征始终保持显著,避免了像素级模型可能出现的注意力分散。
PointMaze环境(小球在迷宫中寻路)中,68.7%的成功率再次验证了模型的泛化能力。特别值得一提的是,由于采用了帧跳(frameskip=5)技术,模型在保持精度的同时,将规划速度提升了5倍,使实时控制成为可能。
这些任务的共同特点是:成功依赖于对环境动态的准确预测。DINO-world通过在潜空间中模拟候选轨迹,能高效找到通往目标的路径,而无需生成真实像素,这种"想象在语义空间"的策略,使规划效率比像素级模型提升了10倍以上。
局限与未来:世界模型的进阶之路
尽管表现出色,DINO-world仍存在不容忽视的局限。最突出的是长期预测能力不足——在超过1秒的预测任务中,即使采用自回归方式逐步预测,误差也会显著累积。在Cityscapes数据集中,1秒后的分割预测mIoU从55.1降至38.6,下降幅度达30%。这表明模型对复杂场景的长期依赖关系(如交通信号灯变化引发的车流变化)捕捉仍不充分。
数据方面,虽然66M视频已经是海量规模,但未筛选的web视频也带来了噪声问题。研究发现,模型在处理低质量、抖动严重的视频时,预测精度会下降15%-20%。如何通过数据筛选或增强技术提升训练效率,是未来的重要方向。
在应用层面,当前模型主要处理视觉输入,而多模态融合(如加入语言指令)仍是空白。想象这样的场景:用户说"把红色盒子放在架子上",模型需要同时理解语言指令和视觉场景,才能规划出正确动作。将语言作为条件信号加入DINO-world架构,可能是实现这一目标的有效路径。
值得期待的研究方向还包括:
引入不确定性建模:当前模型输出确定性预测,而现实世界充满随机性,学习预测"可能的未来分布"将提升鲁棒性 结合强化学习:用模型预测指导策略学习,减少真实环境交互需求 迁移到更多物理场景:如流体动力学、柔性物体变形等复杂动态系统
结语:重新定义世界模型的效率与能力
DINO-world的出现,标志着世界模型研究从"像素崇拜"向"语义优先"的转变。通过站在DINOv2等视觉基础模型的肩膀上,它证明了一个关键观点:智能预测不需要复刻所有细节,而是要抓住世界的本质规律。
这种思路带来的效率提升是革命性的——仅用11亿参数(约为COSMOS的1/10),就在多数任务上实现超越。当训练成本降低一个数量级,研究者就能更自由地探索更大规模的数据和更复杂的模型结构。
对于从业者而言,DINO-world的启示在于:构建实用的世界模型,或许不必执着于生成照片级视频,而应专注于学习对决策真正重要的抽象动态。在自动驾驶、机器人操作等核心领域,这种"理解为先"的智能,可能比"逼真为先"的系统更快走向落地。
随着潜空间预测技术的成熟,我们离构建出真正理解物理世界的世界模型,又近了一步。
大模型之心Tech知识星球交流社区
我们创建了一个全新的学习社区 —— “大模型之心Tech”知识星球,希望能够帮你把复杂的东西拆开,揉碎,整合,帮你快速打通从0到1的技术路径。
星球内容包含:每日大模型相关论文/技术报告更新、分类汇总(开源repo、大模型预训练、后训练、知识蒸馏、量化、推理模型、MoE、强化学习、RAG、提示工程等多个版块)、科研/办公助手、AI创作工具/产品测评、升学&求职&岗位推荐,等等。
星球成员平均每天花费不到0.3元,加入后3天内不满意可随时退款,欢迎扫码加入一起学习一起卷!

 扫码添加微信
扫码添加微信
- 点赞 (0)
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊





