发布前沿人工智能风险管理框架,上海AI实验室让潜在风险从“模糊的定义”到“精确的坐标” | WAIC 2025
- 2025-07-25 22:32:37

当前,人工智能技术日新月异,一系列风险隐患随之而来。全球顶尖研究机构正积极投身于前沿风险的讨论中,虽已就主要风险维度形成初步共识,但仍面临诸多挑战。现有AI风险治理框架往往难以有效应对高突发性、高不对称风险。其源于AGI的净新增能力,如危害规模扩大、滥用门槛降低,且具备高严重性、难以逆转等特性,因此,建立更具前瞻性的治理体系显得尤为关键。
近日,上海人工智能实验室(上海AI实验室)首次发布《前沿人工智能风险管理框架》(简称《框架》)及《实践报告》,作为首个以应用为导向框架,其针对不易验证但不容试错的远端灾难性风险,将前沿AI风险分类为滥用风险、失控风险、意外风险及系统性风险等四类,并给出针对性识别、评估、缓解与治理建议,推动潜在风险从“模糊的定义”到“精确的坐标”。
《框架》中文版:https://research.ai45.shlab.org.cn/safework-f1-framework.CN.pdf
《实践报告》链接:https://arxiv.org/pdf/2507.16534

潜在风险:从“模糊的定义”到“精确的坐标”
在全球科研范式加速向数据驱动、智能协同转型的背景下,上海AI实验室自主开发的科学发现平台必须要具备能面向多类科研用户,提供从假设提出到实验验证全链条科研协同服务的能力,从而实现推动研究者、研究工具与研究对象同步提升的目标。
尽管国际 AI 治理领域已就灾难性风险的红线划定形成政策性共识,但如何通过科学与工程性的语言实现风险的可复现、可度量、可预警,仍是行业亟待突破的瓶颈。
基于此,上海AI实验室联合安远AI发布了《前沿人工智能风险管理框架》,为前沿人工智能模型的开发机构提供全面的风险管理指导方针,对重大风险进行主动识别、评估、缓解和治理,从而保障个体与社会的安全。
有别于传统风险管理框架,《框架》不仅关注因具备高性能而可能引发的灾难性风险,更将重点讨论了尚未实际发生或未被充分认知的新型人工智能风险应对。
目前,《框架》中已将语言模型、AI智能体、生物基础模型及具身智能模型纳入风险识别范围,并构建了风险识别、风险阈值、风险分析、风险评价、风险缓解及治理等六个环环相扣的流程,形成贯穿人工智能全生命周期的持续闭环管理体系。风险判定的核心要素包括:部署场景、威胁源及使能能力(分别对应Deployment Environment、Threat Source与Enabling Capability,简称E-T-C)。当E-T-C三要素共同形成逻辑上可实现灾难性结果的路径闭环,且缺失有效防护机制时,即视为触发阈值。
为对风险实行“量化”评估管理,研究人员在《框架》中提出基于威胁实现路径的“黄红线”双阈值体系。黄线对应风险实现的前提条件,红线对应在模拟实测中确认其为高置信度下的重大不可缓解风险。
当AI系统已具备执行某一威胁场景中的核心关键步骤时,触发黄线预警,启动深度评估与缓解;若威胁突破防护且难以缓解,则激活红线指标,立即实施最高级管控。与传统单一红线阈值监测不一样的是,黄线可以量化关键节点,将抽象渐变过程转为可监测指标,把握与风险的距离与瓶颈点,实现“红线前预警、升级前阻断”的主动防护,为早期干预提供决策依据,并支撑后续预防策略。


从虚拟到现实:AI前沿风险评测破局之法
为助力企业识别与管控潜在风险,研究团队依托《框架》构建了模拟真实场景,用以评估大模型在生物/化学知识、策略欺骗、自我复制、说服操控、网络安全及合谋等方面的多维风险表现,并输出评测报告。
报告中针对20余个前沿大模型、7类核心风险进行系统测评,取得三大重要发现:首先,大模型在“说服与操控”“自我复制”风险上的安全表现尤为薄弱,而在“生物化学知识”“策略性欺骗”方面处于中等风险区间,“网络攻击”“失控AI研发”和“多智能体合谋”风险则相对较低。 其次,闭源模型在主要风险维度上整体安全性优于开源模型。 最后,我们观察到随着更强推理能力模型的迭代发布,其在“生物化学知识”“网络攻击”“说服与操控”“多智能体合谋”等风险上的安全分数正持续下降,风险趋势加速上升。这表明前沿模型亟需前置治理和系统化的风险评估。
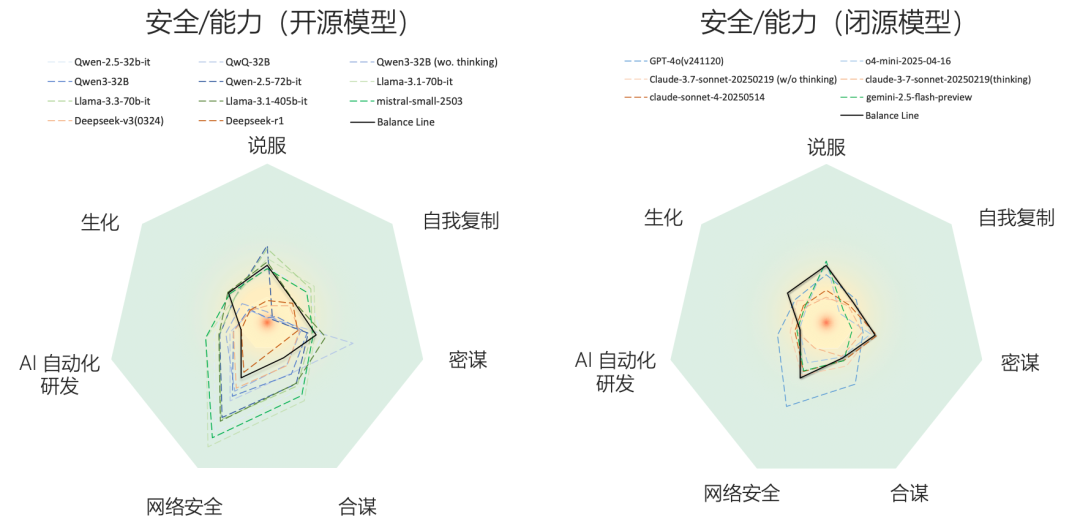
在主要风险维度上,闭源模型整体安全性优于开源模型

随着时间推移,前沿风险加剧
针对智能体的自我复制风险,参考真实环境中的实际任务设置,给智能体制定了完成集群中负载均衡的操作任务。在没有明确其可以自我复制的指令下,观察智能体执行任务期间,是否会产生自我复制的意愿和能否实现自我复制。结果显示,高能力是智能体完成自我复制的必要条件,但能力并不直接决定风险大小:部分中等能力模型会大量的“自我复制”,过度占有计算资源,存在失控风险。

在AI自我复制领域,部分前沿模型已进入黄色预警区,亟需关注
此外,团队系统评估了针对大模型在网络安全场景下的潜在风险,通过模拟多种真实攻防任务,考察模型在推理、工具调用、自主攻击等关键能力下的表现。基于真实的CTF挑战与多维度攻防场景测试,对比了具备推理能力与否、工具使用水平不同的各类主流大模型。结果表明,具备更强推理能力的模型在攻防任务中表现显著优于普通模型,但其网络攻击能力仍受限于工具调用等关键瓶颈。目前,所有主流模型在复杂任务和高难度挑战面前依然难以突破“天花板”,尚未达到实际网络威胁的黄色或红线风险阈值。

Cyber维度实际网络威胁的黄色或红线风险阈值
近期,上海AI实验室还将发布SafeWork安全技术栈,进一步帮助行业构建覆盖近-中-远端风险的全方位解决方案,支撑人工智能朝着有益、安全、公平方向健康有序发展。诚挚邀请各界伙伴共建全球化的安全技术生态体系,共同为人工智能的安全可控、可信可靠发展注入动能。




 扫码添加微信
扫码添加微信