


“AI大神”李沐终于开源新模型,爆肝6个月,上线迅速斩获3.6k stars!
- 2025-07-25 13:41:00

7 月 23 日,“AI 大神”李沐宣布开源了 Higgs Audio v2,这是一个音频基础模型,构建在 Llama-3.2-3B 基础之上,预训练数据包括超过 1000 万小时的音频以及丰富的文本数据。该模型目前在 Github 上已获得 3.6k stars。
“去年我们一直关注的是文本语言模型,让它智商足够高、能听从人的指示,一方面可以陪人玩游戏,另一方面也能帮忙处理一些文案工作,简单来说就是能读能写。今年我们在想,能不能让模型能听也能说。”李沐在 B 站发布的视频中说道。
随后,他表示,“语音是 AI 中一个相对比较悠久的领域,我其实并不是语音方面的专家。作为一个新手,我的想法很简单,就是我不要去训练单独的语音模型,而是在文本大语言模型训练时加入大量的语音数据,大力出奇迹,就想让文本语言模型智商不要下降,但同时掌握了用语音沟通的能力。”
李沐是全球知名 AI 深度学习科学家、深度学习框架 MXNet 作者之一,2008 年毕业于上海交通大学计算机系,曾于微软亚洲研究院实习。毕业后任香港科技大学研究助理,2011 年加入百度任高级研发;2012 年赴卡耐基梅隆大学攻读博士,期间在谷歌研究代码文档。2017 年获博士学位后加入亚马逊担任 AI 主任科学家,工作 7 年半后离职创立大模型公司 Boson AI。
据悉,在 EmergentTTS-Eval 测评中, Higgs Audio v2 在“情绪(Emotions)”和“提问(Questions)”两个类别中,相较于 “gpt-4o-mini-tts”,分别达到了 75.7% 和 55.7% 的胜率。同时,它在 Seed-TTS Eval 和情感语音数据集(Emotional Speech Dataset, ESD)等传统 TTS 基准测试中也取得了业界领先的成绩。

此外,该模型还展现出其他能力,包括多语种自然多说话人对话生成、旁白时自动语调适配、克隆声音的旋律哼唱,以及语音与背景音乐的同步生成等。
李沐在最新的视频中详细介绍了 Higgs Audio v2 背后的技术以及踩过的一些坑。
文本模型训练时
加入 1000 万小时语音数据
李沐开始介绍了 Higgs Audio v2 的架构。但在此之前,他先举例回顾了文本模型的原理。比如,问模型“中国的首都是?”,语言模型看到这个问题后,会下意识地开始回答,首先想到“北”,然后结合这个问题和“北”,再去预测下一个词是“京”。

但在实际使用中,通常不会让语言模型直接做这种文字接龙,因为这样不够可控。通常做法是把一个问题分成三个部分:在“system”部分,在这里告诉语言模型要做什么事情,比如让它回答问题,当然也可以让它做别的,比如闲聊、帮忙写一段文字等;在“user”部分,要把具体要做的事情告诉模型,比如具体要问的问题或者要写什么样的小说,而“system”就是模型的回复。还可以做成多轮交互,也就是再接一个“user”后,再接一个“system”。
让这个模型支持语音的输入和输出,就是给这个模型增加一个新任务。比如,给模型的系统命令:“把下面的文字转录成语音”,然后在用户的输入里把要转的文字告诉模型,希望模型能在“system”里输出对应的语音数据。

为什么要把语言模型改造成这个样子?李沐解释称,因为语音识别或者语音生成,都是一个单独的模型,它要做的事情就是把文字转语音或者语音转文字。像 Whisper 虽然也是基于 Transformer,但是它只干一件事情。
让一个文本的模型做额外的语音输出,坏处很明显:如果想让一个模型能够具有很好的语音处理能力,那么相对于纯语音模型来说这个模型会变大。同样地,一个文本模型加入语音数据很有可能让它的智商变低。
但是,这样做的好处也很明显。比如,下图显示了一个简化的任务版本:

在专业的语音录音时,导演会给专业的录音演员介绍录音的场景(这里是“小明和小红在吵架”),同时要说明这个人物的性格是什么样子?(这里是“小明性格比较急躁,小红比较腼腆一点”)。接下来是真正要录的一个对话,小明说什么、小红说什么,同时可能一些相应的动作音效都要加进去。那么,专业的录音演员不仅仅是要把这句话读出来,而且是要符合人设、符合场景,这样才能做到很好的一个表演。
上一代的文字转语音模型很可能比较难以理解这么复杂的设定。那么有了语言模型的加持之后,它很有可能可以理解,因为在文本领域大家一直是给模型特别复杂的设定:“你要帮我干 a、b、c、d、e、f、g,然后请你帮我干出来”,所以在模型训练时候会尽量让它能够遵从人的指示。如果保留了文本语言模型的能力,那么做语音输出的时候就也能够支持对复杂指令的理解。
此外,简单的文本转语音任务已经不能满足大家的需求了。我们可能不仅想要生成一段语音,还想写一首歌并把它唱出来,配乐也要跟上。这是生成方面的应用,在理解方面也可以发挥作用。
比如给到一段声音,让模型把里面人说的话提取出来,这是最简单的;接下来,还可以让模型分析里面在发生什么事情,比如说话的人是男性还是女性、年纪如何,他们是在吵架、对话还是在进行教学,根据环境音还能猜出是在室内、室外还是其他场景。语音中包含大量信号,人能够理解其整个上下文,而有了文本语言模型的加持后,模型也能够进行这种复杂的理解和推理。
更复杂一点的,我们和模型语音聊天,不希望模型只是机械地一轮一轮回应,而是能理解人们当前的心情,也能表现自身的情绪,而且希望它的延迟足够低,不会说一句话后要等一两秒才回答,而是可以像面对面交流一样。
李沐表示,所有这些任务都能够拆解成“system、user、assistant”这样的格式,使得语言模型能够统一处理,也就是“一个祖传的配方能够处理所有的问题”。团队希望用一个相对来说固定的简单的模型,然后通过加更多的数据,加入更多的算力,通过 Scaling Law 大力出奇迹。
接下来,回答两个“怎么做”的事情:
怎么让模型理解和输出整个语音信号或者声音信号?
在训练模型的时候,要构造怎么样的数据,让模型真的能够把语音的信号和文本的信号很好地融合起来,然后它能理解这个语音到底在表达什么?
对于第一个问题,李沐先回顾了文字是怎样在语言模型里面表示的。
文字在语言模型中通过 token 或资源这种来表示,简单理解就是中文单字或英文词根可视为一个 token,输入文字被转化为 token 序列,语言模型的任务是预测序列中的下一个 token。token 是离散概念,它有一个包含了数万个 token 的词典,语言模型的输出是一个 Softmax,本质是一个多分类问题,每次从词典中选择一个词作为输出。
语音信号会麻烦一些,它是连续的信号。怎么把连续的信号表示成离散的 token?
一种简单方法是按固定时长(如 100 毫秒)切分语音片段,并基于声音在细粒度上重复出现的特性,为每个片段匹配一个预定义的、代表性的声音模板(即 token)来近似表示。比如,以 45 个语音片段作为模板,当输入 1 秒的语音引号后,将其切分为 10 个小片段,每个片段用 45 个模板中最匹配的模板编号表示,最终该秒语音转化为长度为 10 的编号序列。这种表示使语言模型能像处理文本 token 一样处理语音信号,无论是输入还是输出。
当然,实践中不会那么的简单,因为语音信号不是那么容易被表示的。比如,1 小时的信号用 128 BPS 的 MP3 存储,大概约 60MB(中等音质),若采用 64,000 个 token 表示,然后一秒钟的音频用 24 个 token 表示。那么用这种方式编码一段语音时,每个 token 仅需 log₂(64,000)≈16 比特,1 秒语音仅需 384 比特(24×16),1 小时压缩至 0.16MB,相较于 128kbps MP3 实现了 375 倍的压缩。
这样高的压缩必然严重损失信息,此时关键的问题在于:tokenizer 应优先保留声学信号(如说话的音调)还是语义信号(具体说的什么内容)? 李沐团队的结论是:语义信息优先。
声学信号只需少量特征即可保留核心风格,后续可通过其他方法还原。但语义信号千变万化,同一声音在不同场景下表达的内容可能截然不同,因此需尽量保持语义信息的完整性,确保语义 token 包含足够丰富的语义信息,使模型能早期建立语音与文本 token 的强语义关联,从而流畅实现语音与文本的相互转换。
将声音表示成 token 进入模型之后,接下来要关注的是模型怎样能很好地理解和生成这些声音。
声音转文字或者文字转声音,本质上是在做模态间的转换,所以语言模型能够将一个内容的语音表示和文字表示做映射。如今文本的大模型已经很强了,现在需要考虑的是将语音的语义尽量映射回文本,以继承模型在文本领域的强大能力。
可能有人问,如果做实时语音助手,听上去好像是我说一句、模型回一句,是不是直接在语音的空间做呢?实际上,现在的技术还是会回到文本的语音空间。因为做一个语音助手,那么人设是什么、什么东西该做、什么不该做,其实是用文字来控制。另外,实时互动的时候很有可能也是在文本空间。比如问“今天天气怎么样?”模型可能是在文本空间搜索,然后把结果返回来后,再映射回语音信号。因此,核心在于模型需要打通文本与语音的表示关联,使模型理解同一概念在不同模态的对应关系。
有了这个目标后,就可以考虑需要什么样的数据以及数据怎么表达。
“我觉得数据反正是越多越好。”李沐表示,团队未使用 B 站或 YouTube 的数据,不是因为质量不好,而是为了规避版权风险。其做法是要么采购合规数据,当然价格不能太贵,要么抓取允许公开获取的音频,但后者可能需要删掉 90% 的数据才能留下一些可用的。例如,为获取 1,000 万小时有效数据需抓取近 1 亿小时原始素材。
有了数据之后,团队是怎样进行模型训练呢?
举例来说,拿到一段语音进行模型训练时,通常会如下表达:系统层面说明这个声音的声学特征是什么、在聊什么、有哪些人以及这些人的特点等;接下来,用户输入的聊天文字作为输入,模型则输出对应的音频。

在这个任务中,团队希望模型能根据提供的整个场景描述和需要生成的文字,能够输出真实且符合场景的语音。
对于这些标签是怎么打出来的问题,李沐的建议是:如果是一名学生做研究,推荐把语音交给 OpenAI 的 GPT 或 Google 的 Jamila 让他们打标。但李沐坦言其团队做不了这个事情,背后有两个原因:第一个原因是对方明令禁止调用他们模型的输出去训练其他模型;第二个原因是成本太贵了,团队要处理的数据量远不止一千万条,可能上亿,这样的 API 代价承受不来。
李沐团队的做法是:采用同样的模型架构,额外训练一个语音理解模型。大家应该能想象这个语音理解模型的输入输出:在做语音生成时,是输入场景描述和用户要说的话,然后输出语音;现在是反过来,输入一段用户语音,要求模型分析场景(如有哪些人、这些人什么样、在说什么内容)以及说话时的情绪状态等,并输出所有这些信息。
这相当于把生成模型的输入输出对调了:生成模型的输入(场景描述和说话内容)变成了理解模型的输出,而生成模型的输出(语音)变成了理解模型的输入。
打个比方,要教会徒弟全套拳脚功夫,但一次教不全;于是我先教一个徒弟打拳,再教另一个徒弟踢腿,然后让他们天天对打,打着打着共同进步,最终两人都学会完整的拳脚功夫。
最后,回归到 Higgs Audio v2,其采用了下面架构图中所示的“生成式变体(generation variant)”。
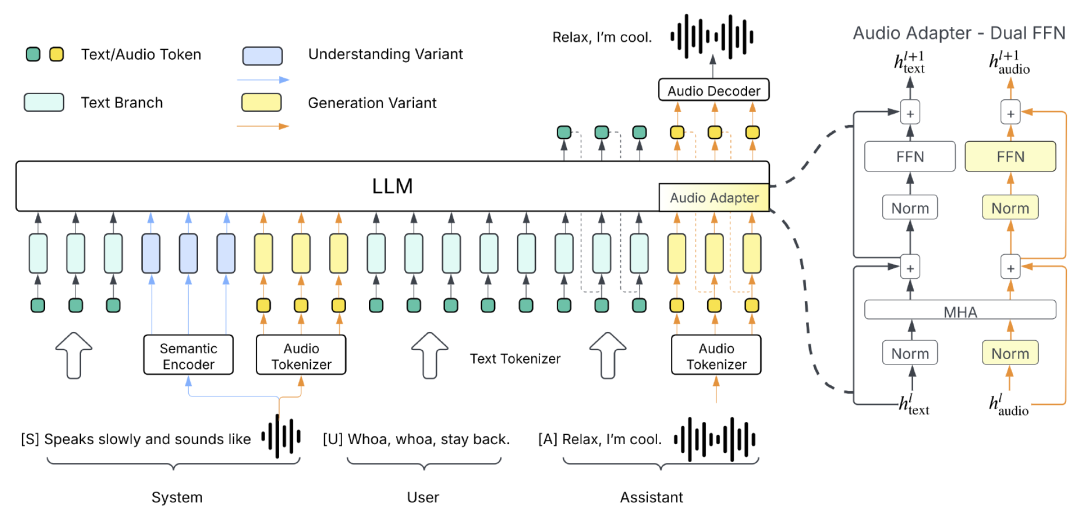
该模型的性能表现主要得益于三项关键技术创新:
团队开发了一套自动化标注流程,结合了多个语音识别(ASR)模型、声音事件分类模型,以及其自研的音频理解模型。通过这条流程,团队清洗并标注了 1000 万小时的音频数据,并将其称为 AudioVerse。自研的理解模型是在 Higgs Audio v1 Understanding 基础上微调而来,后者采用的是架构图中所示的“理解式变体(understanding variant)”。
从零开始训练了一个统一的音频分词器(tokenizer),能够同时捕捉语义和声学特征。
提出了 DualFFN 架构,在几乎不增加计算开销的前提下,显著增强了大语言模型(LLM)对声学 token 的建模能力。加入 DualFFN 后,其实现依然保留了原始大模型训练速度的 91%。
参考链接:
https://b23.tv/UdINLVV
https://github.com/boson-ai/higgs-audio
声明:本文为 AI 前线翻译整理,不代表平台观点,未经许可禁止转载。
后续我将通过微信视频号,以视频的形式持续更新技术话题、未来发展趋势、创业经验、商业踩坑教训等精彩内容,和大家一同成长,开启知识交流之旅
欢迎扫码关注我的微信视频号~

今日荐文
“连我也要被GPT-5踹了!”Altman再发暴论:写款软件就花7毛钱,大批高级程序员岗也说没就没
阿里Qwen3-Coder携1M上下文杀来!5分钟生成网站,开发者狂欢:Claude Code可以卸载了
Altman 秀新模型“翻车”,谷歌补刀躺赢!OpenAI 前员工爆肝3天,编程再赢老东家模型!
一个任务50次调用,成本狂砍90%?Manus首次公开上下文工程秘诀,一堆反复重写换来的教训
万人见证,“出轨”CEO被停职;陶哲轩评“OpenAI内部实验模型获IMO金牌”;传字节Seed视觉负责人“暂休”|AI周报

你也「在看」吗?👇
 扫码添加微信
扫码添加微信








