


提速79%!上交大新方法优化企业级AI流程调度 | IEEE ICDCS’ 25
- 2025-07-24 15:28:26
LLMSched团队 投稿
量子位 | 公众号 QbitAI
复合LLM应用 (compound LLM applications) 是一种结合大语言模型(LLM)与外部工具、API、或其他LLM的高效多阶段工作流应用。
⽬前,服务这些应⽤任务需要⾯对运⾏时⻓不确定、⼯作流结构不确定等问题,这对现有集群任务调度算法提出了极大挑战,并严重影响任务运⾏效率。
为了解决上述问题,上海交通大学朱怡飞教授团队联合江行智能提出调度框架LLMSched,通过引入三类新节点来扩展传统任务表征方法实现复合LLM应用任务的有效表征,借助贝叶斯网络识别可降低不确定性的关键节点,并以信息熵衡量节点的熵减程度。
目前论文已被IEEE ICDCS’ 25接收。
实验结果显示,LLMSched结合探索-利用策略来平衡调度不确定性与当前调度收益,最终实现高效调度复合LLM应用,相较现有调度器平均任务完成时间降低14~79%。

LLMSched:DAG模型重构+熵减调度
团队通过对现有复合LLM应用的设计分析与实验,总结出复合LLM应用以下两点不确定性:
时长不确定性:单任务耗时波动高达300秒(图1a)。该不确定性主要来源于LLM的自回归生成特性。
结构不确定性:任务步骤数与运行结构随机波动(图1b/c)。该不确定性主要来源于LLM在复合LLM应用中发挥的决策与规划功能。

复合LLM应用这两种不确定性极大限制了传统调度的性能表现。如下图实例所示,传统最短任务优先(Shortest Job First)调度因误判耗时导致效率低下(任务平均完成时间6.5s),而不确定性感知的调度器通过提前执行高熵减阶段(TA-1)降低不确定性,从而达到更有效调度(任务平均完成时间5s)。

DAG模型重构:调度的基石
为了应对复合LLM应用中存在的结构不确定性,研究团队提出全新有向无环图(DAG)建模框架,如下图所示。该框架引入了三种节点,常规节点(Regular Stage),LLM 节点(LLM Stage)与动态虚拟节点(Dynamic Stage)。其中,常规节点对应外部工具、api等的调用,LLM节点对应LLM推理任务,动态虚拟节点对应由LLM规划生成的子DAG。

重构后的DAG模型能将现有的复合LLM应用表征为拥有固定拓扑结构的调度单元,为之后的调度设计建立了基础。
贝叶斯分析器+熵减衡量机制:让系统越算越“清醒”
团队在研究过程中意识到复合LLM应用的部分节点存在显著的关联性。这种关联性使得在执行完成某些前置节点后,后续节点的不确定性能够有效降低,具体表现如下:
1、规划式任务中LLM规划节点后的工作流完全由该节点决定。完成该LLM规划节点后,所规划的子工作流的未知拓扑结构可被完全揭示。
2、相当一部分的节点在运行时长上存在较高的关联性(下图所示)。在完成前置节点后,后续节点的时长不确定性进一步降低。具体表现在后续节点的运行时长的条件分布更为紧凑、可预测。
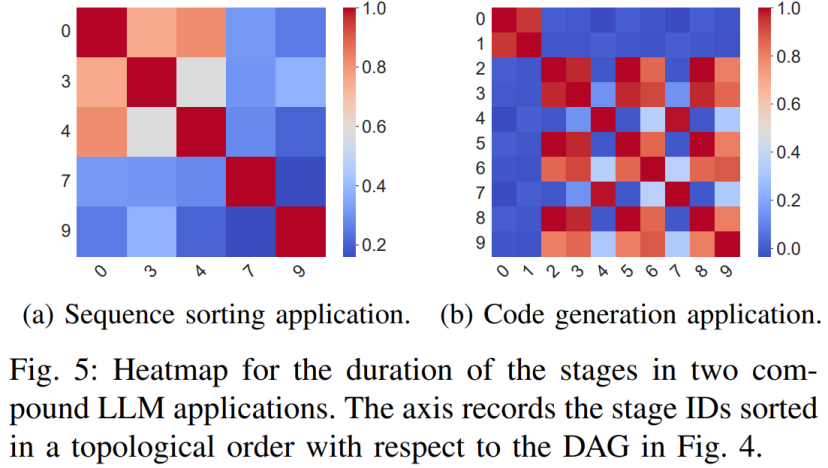
为此,团队为每个应用在对应数据集上收集了大量的运行时长数据,并在数据上基于重构的DAG模型训练贝叶斯网络(BN)来获取节点的运行时长分布与节点之间的关联性。当BN中的一个节点存在一条或多条出边时,该节点便与其他的节点存在关联,调度该节点便可以降低其他节点的不确定性。
考虑到实际情况中,不同的节点能够降低的不确定性程度大不相同,团队引入信息论中信息熵的概念,使用互信息衡量,如下图所示。由于信息熵与互信息均通过变量的分布进行计算,因此之前通过BN获得分布便可以直接用于计算调度每个节点的熵减,无需额外的测量。

为了将上述的熵减思想用于优化任务的平均完成时间,团队使用ε-greedy算法结合最短剩余时间优先与最大熵减优先两种策略,提出了一个高效的调度算法。该算法借鉴了探索-利用的思想,巧妙地在降低任务不确定性与降低任务完成时间两个潜在的冲突目标中达到了平衡。在调度过程中,调度算法会收集任务完成的时长信息,利用贝叶斯网络动态更新每个任务的运行时长,从而获取更精确的任务时长估计。该算法的复杂度仅为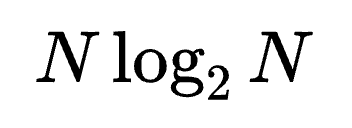 ,能够对动态的负载做出快速的调度决策。
,能够对动态的负载做出快速的调度决策。
实验结果:平均任务完成时间最低降至79%
团队选取了六种代表性的复合LLM应用,并基于此构建了4种不同应用组成的负载,如下图所示。团队在一台搭载H800 GPU的ubuntu机器上使用vLLM框架与LLaMA-7B 模型进行了实验。
实验结果表明,LLMSched相较于现有的调度器最多可降低79%的平均任务完成时间。

为了进一步衡量LLMSched的可拓展性与适应性,团队构建了一个简易的LLM推理模拟器,并在上面进行了多组不同任务数量的实验。如下图所示,团队展示了不同任务数量的仿真结果。
实验结果表明,LLMSched在任意一组实验设置上均取得领先的成绩,同时随着任务数量增加,LLMSched的优势变得更为突出,比如,与 Decima 相比,在包含 100、200、300和400个任务的混合工作负载中,LLMSched 分别降低了 38%、65%、73%和 75%的平均 JCT,这展示了 LLMSched 的可扩展性。

此外,团队在测试平台实验中,在下图中展示了每种方法的平均调度开销(总开销除以每种方法的调用次数,包括BN推理和熵计算)。团队方法的平均调度开销略高于FCFS、SJF和Fair等简单启发式算法,但远低于Decima和Carbyne这两种复杂方法。此外,LLMSched的平均开销对于所有类型的工作负载都低于3毫秒,这表明LLMSched可以在不影响平均JCT的情况下执行高效的实时调度。

消融研究
为了分析这两个组件的有效性,团队进行了消融研究,创建了两种额外的方法——LLMSched w/o BN 和 LLMSched w/o uncertainty。第一种方法遵循算法1中提出的相同调度方案,但使用历史任务平均持续时间进行估计。第二种方法使用贝叶斯网络更新任务持续时间的后验分布,但仅执行SRTF策略。

上图展示了在四种类型工作负载上进行的消融研究结果。团队将两种方法的平均JCT归一化到LLMSched的水平。
对于LLMSched w/o BN,在四种类型工作负载上,平均JCT分别比LLMSched高18%、17%、20%和 5%。这表明BN发挥了重要作用,因为它显著提高了任务持续时间估计的准确性。借助BN,可以通过利用阶段间相关性,更动态地更新和更准确地预测非计划阶段的任务持续时间。
对于LLMSched w/o uncertainty,在四种类型工作负载上,平均JCT分别比LLMSched高 21%、12%、15% 和 13%。这表明不确定性感知策略在有效引导探索过程中至关重要。当处理混合工作负载时,其重要性尤为突出,因为各阶段的不确定性减少差异显著。对于这种工作负载,LLMSched w/o BN的性能优于LLMSched w/o uncertainty。
LLMSched为LLM服务优化开辟了新方向,尤其对多模块协作的Agent系统、LLM推理集群资源调度具有重要参考价值。其不确定性量化框架可扩展至其他动态任务场景,推动智能调度理论与实际系统的深度融合。
论文链接:https://arxiv.org/abs/2504.03444
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
 扫码添加微信
扫码添加微信








