


训练数据爆减至1/1200!清华&生数发布国产视频具身基座模型,高效泛化复杂物理操作达SOTA水平
- 2025-07-25 13:38:56
Vidar团队 投稿
量子位 | 公众号 QbitAI
机器人能通过普通视频来学会实际物理操作了!
来看效果,对于所有没见过的物品,它能精准识别并按照指令完成动作。
比如清理桌面垃圾,或者是从零食筐里找到人类想要的糖果。
△Vidar真实场景演示视频
这就是清华大学与生数科技最新联合研发的Vidar模型,首次让通用视频大模型长出了“手脚”,通过少样本泛化能力,实现从虚拟的Dream World到真实世界Real World物理执行的关键跨越。
它在互联网级视频数据预训练的基座模型Vidu上,使用百万异质机器人视频数据进行再训练。
仅用20分钟机器人真机数据,即可快速泛化到新的机器人本体,所需数据量约为行业领先的RDT的八十分之一,π0.5的一千两百分之一,大幅降低了在机器人上大规模泛化的数据门槛。

△具身数据金字塔;不同方法所需的真机人类操作数据量
突破跨本体泛化困境
众所周知, 当前主流视觉-语言-动作(VLA)模型需要海量的多模态数据进行预训练。这种方法高度依赖大量优质数据,并且这些数据往往只适配特定的机器人本体及其采集的特定任务集。此外,数据收集过程费时费力、成本高昂。这带来了动作数据稀缺和机器人本体不统一两大难题。
清华大学和生数科技研发团队解构了具身任务的执行范式,将其划分为上游视频预测和下游动作执行的方法。
上游预测部分,通过Vidu强大的基座能力和具身视频预训练,新的视频基座模型获得了少样本泛化到新的机器人本体的能力;下游执行部分,逆动力学模型(IDM)可以将视频翻译为对应的机械臂动作,从而实现了视觉-语言模态和动作模态的完全解耦。下面将逐一分析这两部分对应的技术细节。
Vidar整体架构如下:视频扩散模型预测完成指定任务的视频,经过逆动力学模型解码为机械臂动作。

视频扩散模型:“预训练+微调”下的精准控制
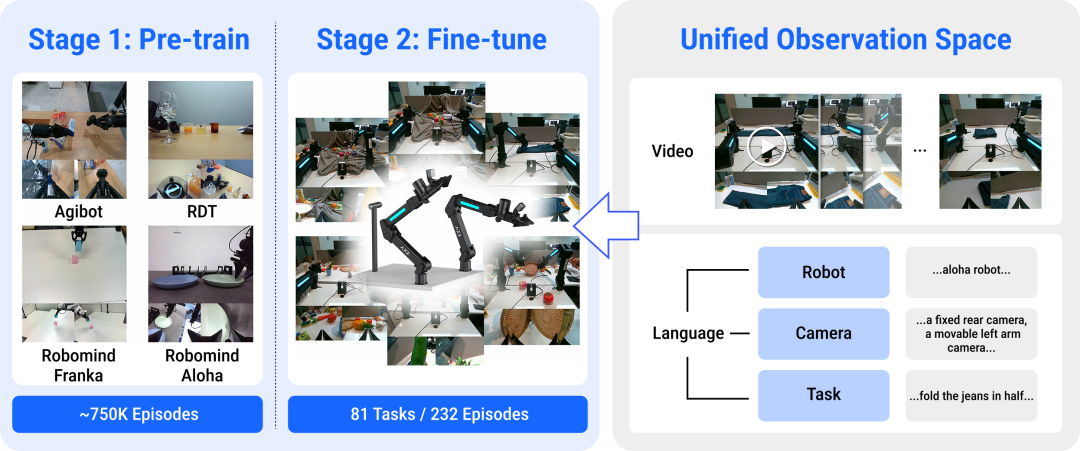
为让模型更“见多识广”,实现多类型机器人操作的深度融合,灵活适应各种物理环境,清华大学和生数团队创新性地提出了基于统一观测空间的具身预训练方法。这套方法巧妙运用统一观测空间、海量具身数据预训练和少量目标机器人微调,实现了视频意义上的精准控制,主要方法如下:
1、统一观测空间:通过多视角视频拼接,将不同机器人操作时的多视角画面,巧妙地融合成统一分辨率的“全景图”,同时将本体信息、摄像头信息与任务标注一并打包整合,为海量互联网数据提供了共同对话的基础,实现了真正的多维度融合。
2、百万具身数据预训练:以经过互联网规模预训练的Vidu2.0模型为基础,进一步引入75万条涵盖各类双臂机器人操作的数据,持续深度训练,成功炼就了具身视频基座模型。该模型不仅将动作、环境和任务多重先验融会贯通,更练就了一身强大的通用本领与泛化能力。
3、20分钟目标机器人微调:为使Vidar能够适配从未见过的机器人类型,研究团队专门收集了目标机器人20分钟的操作数据集,对模型进行专属微调。通过这一创新训练流程,Vidar就能在目标机器人平台上大显身手,精准理解任何任务指令,并生成出分毫不差的任务执行预测视频。
在视频生成基准VBench上的测试表明,经过具身数据预训练,Vidu模型在主体一致性、背景一致性和图像质量这三个维度上都有了显著的提升,为少样本泛化提供了有力支撑。此外,团队引入测试时扩展(Test-Time Scaling),使得模型能够“见机行事”,选择更贴近现实的“机器人之梦”,进一步提升了模型在实际应用中的视频预测表现和可靠性。

逆动力学模型:从梦境到现实的“桥梁”
业界目前流行的VLA范式面临机器人动作数据匮乏的严重挑战,为了突破现有具身智能数据被任务“过度捆绑”、难以做大的瓶颈,团队提出了任务无关动作(Task-Agnostic Action)的概念,这个概念不仅是从具身基座模型中解耦动作的关键一步,更一举带来三大好处:
(1)数据好采集,规模化愿景成真(2)跨任务、甚至零样本任务都能轻松泛化;(3)告别人类监督、标注和遥操作,省心省力。
基于这个“任务无关数据”的概念,团队提出了:
自动化规模化收集任务无关动作数据的方法ATARA (Automated Task-Agnostic Random Actions):对于一个从未见过的机器人,利用全自动化任务无关动作数据的方法收集训练数据,仅需10小时无干预自动化采集该机器人的动作数据,即可实现该机器人的全动作空间泛化,彻底告别跨本体问题。
如视频所见,不需要人类监督和遥操作,机器人可以无干预自动采集数据,而且所采集的任务无关数据可以用于任何任务的执行,ATARA有效解决了传统纯随机采样方法的三个大问题:可达状态覆盖效率低下、动作冗余(比如机械臂挥舞“出画”)以及频繁的自碰撞。
超高精度预测逆动力学模型AnyPos进行动作执行:AnyPos提出Arm-Decoupled Estimation和Direction-Aware Decoder,让模型在自动化采集的数据上训练出高精度的动作预测模型。

这种自动化任务无关数据收集与高精度模型训练并重的方法实现了低成本、高效率、高精度的指定机器人动作预测,准确率远超基线51%。在真实世界任务轨迹重放测试中,其成功率直逼100%,相比基线大幅提升33~44%。


此外,为了让模型更能适应不同背景,团队还提出了掩码逆动力学模型的架构。其能够自动学会“抓住重点”,自动捕捉机械臂相关的像素,实现跨背景的高效泛化。
真机操作实验:成功打通“虚拟-物理”世界
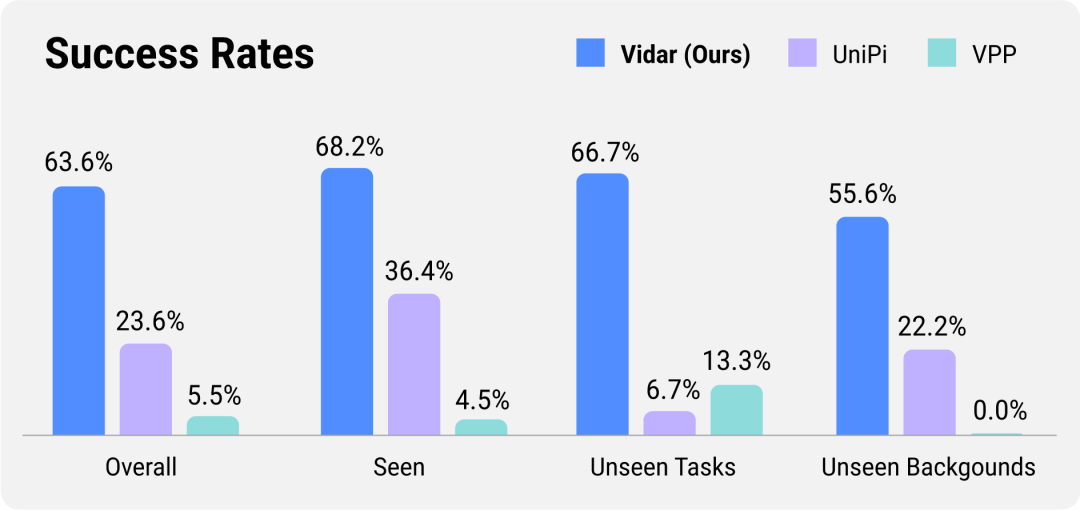
在16种常见的机器人操作任务上,Vidar取得了远超基线方法的成功率;再细分到类别,Vidar在没见过的任务和背景上的泛化能力尤为突出。
以下是一些执行任务的示例,左边是视频模型的预测,右边是实际执行的结果。从中可以看出,Vidar具有较好的指令遵循能力,预测的视频能准确契合任务意图(如从一些红色物体中找到苹果并抓取),同时也能精确完成双臂协作抓取等困难任务。

此次研究成果显著突破了机器人在多任务操作和灵活应对环境变化两方面的能力瓶颈,为未来服务机器人在居家、医院、工厂等复杂真实环境中大展拳脚铺就了坚实可靠的技术基石。这同时也意味着从虚拟世界的算法演练,到真实环境的自主行动,Vidar正在架起这道关键的桥梁,让AI终于能够“脚踏实地”地服务于我们的物理世界。
技术溯源:从视频理解到具身执行的创新路径
Vidar (Video Diffusion for Action Reasoning)是基于在视频大模型领域的系列原创性工作在具身领域的再次创新。Vidar (Video Diffusion for Action Reasoning),在命名上保留技术同源的“生数科技旗下视频大模型Vidu”的前缀,延续雷达(Radar)灵敏的感知隐喻,突出其打通虚实结合的多重能力。
“基于我们的技术理念和统一的基座大模型架构,Vidu与Vidar均致力于解决复杂时空信息的理解与生成。此次推出的Vidar,是全球首个采用多模态生成模型架构解决物理世界问题,并达到该领域SOTA水平的机器人大模型。这不仅彰显了Vidu的强大基模能力及其架构的卓越扩展性,也将通过强化对物理世界的认知,反哺Vidu在数字世界视频创作中对物理规律的理解与生成能力。二者相互促进,共同推动实现我们的终极愿景:提升所有劳动者(人类、Agent与机器人)的生产力。”
生数科技创始人兼首席科学家朱军教授表示:“我们致力于通过多模态大模型技术推动数字世界与物理世界的深度融合与协同进化。一方面,我们正在打造新一代数字内容创作引擎,让AI成为人类创意的延伸;另一方面,我们通过训练具身视频基座模型,实现虚拟与现实的深度交互。”
关于Vidar和Anypos,更多的演示视频如下:
团队介绍
该项目有两位Co-Lead。
一位是清华大学计算机系TSAIL实验室的2023级博士生冯耀(Yao Feng),主要研究方向包括具身智能、多模态大模型和强化学习。作为Vidar的第一作者和Anypos的共同第一作者,在ICML、OOPSLA、IJCAI等顶级会议上发表过多篇论文,曾获中国国家奖学金、全国大学生数学竞赛全国决赛(数学类高年级组)一等奖、叶企孙奖、北京地区高等学校优秀毕业生等荣誉。

一位是清华大学计算机系TSAIL实验室的二年级博士生谭恒楷(Hengkai Tan),主要研究方向是具身大模型和多模态大模型的融合和强化学习,是FCNet、ManiBox、AnyPo、Vidar的一作/共一,也是RDT具身大模型的作者之一,曾拿过全国青少年信息学奥林匹克竞赛(NOI)的银牌,全国84名。AnyPos和Vidar工作再次延续了团队“将动作解耦出基座模型”的思路,从而朝着泛化的视觉交互智能体迈进一步。

团队核心成员来自清华大学计算机系TSAIL实验室:冯耀,谭恒楷,毛心怡,黄舒翮,刘国栋,项晨东,郝中楷,苏航(指导老师),朱军(指导老师,通讯作者)。
论文链接:
https://arxiv.org/abs/2507.12898
https://arxiv.org/abs/2507.12768
项目链接:https://embodiedfoundation.github.io/vidar_anypos
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
 扫码添加微信
扫码添加微信
- 点赞 (0)
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊





