建议大模型RL训练的都来看看字节VAPO
- 2025-07-23 18:10:00

论文题目:VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
论文地址:https://arxiv.org/pdf/2504.05118

创新点
首个在长链式推理(long-CoT)任务中全面超越价值模型无关方法的“价值-模型”框架;仅用 5 000 步就将 Qwen-32B 在 AIME24 上的平均得分从 5 提到 60.4,领先 DAPO 10 分以上。
提出 Length-adaptive GAE:根据响应长度 l 动态调整 λpolicy = 1-1/(αl),一举解决长短序列在偏差-方差权衡上的需求冲突。
引入 Decoupled-GAE:把价值网络更新 λcritic 设为 1.0(无偏)而策略网络仍用较小 λpolicy,切断长轨迹上的奖励衰减链,显著减少训练崩溃。
方法
本文以“价值模型增强的近端策略优化(VAPO)”为核心,把长链式推理任务形式化为 token-level MDP,先固定策略用 Monte-Carlo 回报预训练价值网络 50 步以消除初始化偏差;随后在 PPO 框架内采用双通道 GAE——价值更新用 λ=1 的完整回报,策略更新用长度自适应 λpolicy=1−1/(αl) 的动态系数——为长短不一的响应提供一致的偏差-方差权衡;同时把样本级损失改为 token 级损失,保证长序列每 token 权重平等;在稀疏奖励场景下,组合 Clip-Higher(εhigh=0.28, εlow=0.2)防熵塌陷、正样本 NLL 损失(权重 0.1)强化对正确答案的利用,以及“512 提示×16 次重复”的 Group-Sampling 策略提升对比信号;
AIME 2024 性能曲线:VAPO 与 DAPO 步数-得分对比图

本图横坐标为梯度更新步数,纵坐标为 AIME 2024 平均得分。红色曲线代表 VAPO,蓝色曲线代表此前最佳无价值模型方法 DAPO。图中可见 VAPO 在约 3000 步时已追平 DAPO 的 50 分终点,随后继续上升至 60.4 分并保持平稳;而 DAPO 在 5000 步附近才达到 50 分,直观展示了 VAPO 在训练效率和最终性能上的双重优势。
VAPO 训练动力学三指标曲线
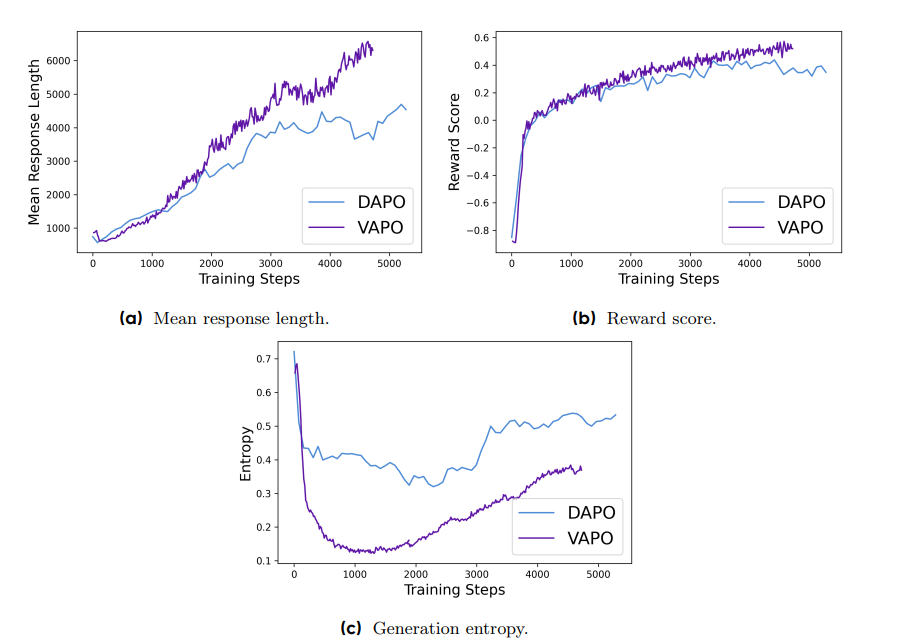
(a) 平均响应长度:VAPO(红线)随步数持续增长至 2 000 tokens 左右,DAPO(蓝线)则在中后期趋于平坦,显示 VAPO 能稳定激发更长推理链。 (b) 奖励分数:VAPO 曲线上升更快、更平滑,且最终稳定在 0.7 以上;DAPO 则抖动明显、收敛更慢。 (c) 生成熵:VAPO 的熵值先快速下降后保持在适中水平,既抑制了过度探索又未出现熵塌陷;DAPO 熵值下降更剧烈,后期几近塌缩,对应其性能 plateau。三幅子图共同刻画了 VAPO 在长度扩展、奖励增长与探索稳定性上的综合优势。
实验

本表提供了 VAPO 算法在 AIME24 基准测试上的消融研究结果,详细展示了各个关键组件对最终性能的贡献。表中列出了从基础的 Vanilla PPO 算法到完整 VAPO 算法的各个版本在 AIME24 上的平均得分。Vanilla PPO 由于价值模型学习崩溃,最终得分仅为 5 分,表现为响应长度急剧缩短,模型直接给出答案而跳过推理过程。而完整的 VAPO 算法最终达到了 60 分,相较于基础 PPO 有了显著提升。结果表明,VAPO 中的每一项改进都对最终的高性能有着不可或缺的贡献,且这些改进相互协作,共同提升了算法的整体性能。
-- END --

关注“学姐带你玩AI”公众号,回复“RL优化”
领取2025强化学习优化方案合集+开源代码

 扫码添加微信
扫码添加微信
- 点赞 (0)
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊