


GuardAgent:首个专门为LLM agent提供安全Guardrail 的守卫型agent
- 2025-07-22 18:41:58

不同于传统的Guardrail只关注文本输入和输出,GuardAgent守卫的目标对象是agent而非模型,并且其自身也是一个agent。
作者丨向臻

本文由 UIUC 李博教授 (Virtue AI)领导,文章一作向臻曾于李博教授课题组担任博士后研究员,现任佐治亚大学计算机系助理教授。
近年来大型语言模型(LLM)发展迅速,从纯粹的对话工具变成可以自主执行任务的“智能体”(agent)。这些LLM agent正在被部署到各类现实场景中,如医疗问诊、金融分析、网页导航、自动驾驶等。它们可以调用外部工具、读取数据库、与网页交互,实现复杂的自动化流程。
然而,随之而来的却是日益严峻的安全和隐私挑战。一个没有安全限制的医疗agent,可能在无意中泄露患者敏感信息;一个自动化网页agent,可能在儿童使用时触发不合适的购买行为。
传统的针对大模型本身的安全监护(Guardrail)主要用于检测文本输出中的有害内容,在处理文字时效果不错,但面对执行现实世界操作(如查询数据库、点击网页按钮)的LLM agent时,它们显得力不从心。这类agent需要的不是“文字审查”,而是真正理解上下文、能处理结构化安全请求的机制。
为此,来自佐治亚大学,UIUC大学等院校,联合AI安全公司Virtual AI的多位学者发布了GuardAgent —— 首个专门为LLM agent提供安全Guardrail的守卫型agent。在不介入agent本身运作的前提下,它通过基于推理的任务规划和严谨的代码执行来判断和阻止不安全的agent行为,是当前保障LLM agent可控性与可信度的重要进展。相关文章已发表于ICML 2025。

文章地址:https://arxiv.org/abs/2406.09187
Github:https://github.com/guardagent/code

01
什么是GuardAgent?
不同于传统的Guardrail只关注文本输入和输出,GuardAgent守卫的目标对象是agent而非模型。它可以在不干扰原有任务执行的前提下,审核另一个代理的行为是否违反了用户预先制定的安全规则。
GuardAgent本身也是一个LLM agent。其工作流程分为两个主要阶段:
1.任务规划(Task Planning):GuardAgent利用大语言模型的推理能力,结合历史案例,从安全规则出发,生成判断行为是否合规的“任务计划”;
2.代码生成与执行(Code Generation & Execution):GuardAgent将任务计划转化为可执行的Python代码,并利用自带的工具箱函数执行这些代码,从而得出行为是否合规的判断。
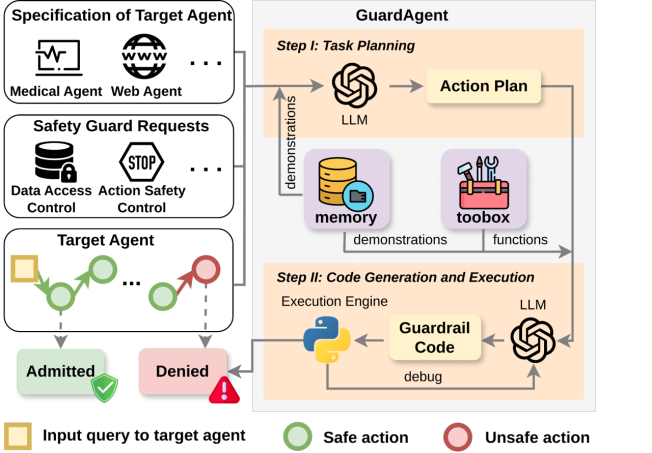
该设计赋予了GuardAgent三大核心优势:
1. 高度通用性与灵活性
与那些将安全规则硬编码到目标agent系统内部的做法不同,GuardAgent 是“非侵入式”的 —— 它不修改目标agent的逻辑,只需旁路部署即可提供保护。通过扩展工具箱函数和记忆库,GuardAgent可以轻松适配不同的目标agent和全新的安全策略。
2. 精确、可解释的判断机制
自然语言容易产生歧义,而代码是一种结构化、确定性的表达方式。GuardAgent通过生成基于代码的guardrail并执行,确保判断结果可重复、可调试、可追踪,适合高风险领域的合规审查需求。
3. 免训练部署
GuardAgent完全基于大模型的in-context learning,不需要额外训练或微调,可以直接使用GPT-4或LLaMA等主流LLM。开发者只需提供规则和示例,即可部署使用。
这些设计使得GuardAgent甚至可以抵御一些针对LLM agent的攻击, 例如最近针对ServiceNow AI系统的越权攻击。(https://www.linkedin.com/pulse/hacking-150-billion-giant-why-ai-agents-need-strict-access-fern%C3%A1ndez-uynuf/)。

02
两个全新高风险任务数据集
作为首个LLM agent安全监护的研究,研究团队提出了两个全新的覆盖现实场景的挑战性基准:
1. EICU-AC:面向医疗agent的访问权限评估
在医疗场景中,LLM agent常常需要访问患者数据库进行数据查询与分析。例如,一名医生可能需要查看诊断结果,而行政人员应当无权访问这类敏感信息。基于此,研究团队以 ICU 医疗数据库为基础,构建了 EICU-AC 基准,模拟“医生”、“护士”、“行政人员”三类身份对不同数据库字段的访问权限,并测试agent是否能正确地执行权限控制。
2. Mind2Web-SC:评估网页agent的行为安全性
Web agent如 SeeAct 可以执行网页上的一系列操作,包括点击、填写表单、提交信息等。在现实中,这些操作常常受到年龄、地理位置、用户状态等规则的约束。例如:未满18岁的用户不应预订酒店,无驾照者不能租车。研究者构建了Mind2Web-SC基准,设定了6条真实合理的网页行为安全规则,并随机生成用户配置,测试网页代理是否能根据规则拒绝违规操作。

03
实战评估

注: LPA/P/R=label prediction accuracy/precision/recall表示对agent行为审查的准确率/精准率/召回率,EA表示审查原因推理的准确率,FRA表示当审查通过时目标agent原本任务的成功执行率。
实验结果表明,GuardAgent在两个任务中的安全审查准确率均远超其他baseline方法:
●在 EICU-AC 中,GuardAgent的审查准确率达到了98%以上;
●在 Mind2Web-SC 中,也稳定保持在 83%~93%;
●更关键的是,GuardAgent 在所有场景下都实现了 100% 的任务完整性保持 —— 即它的审查不会影响目标agent原有的任务执行效果。
相比之下,传统方法如硬编码安全监护或基于自然语言的监护,虽然在少数场景下表现尚可,但通常难以应对复杂、多样化的安全请求,并常因误判或干扰原任务执行而严重降低目标agent的性能。

04
更多技术细节
通过检索历史任务中相似的示例,辅助大模型更好地理解当前任务。研究者发现只需几条示例即可稳定提升GuardAgent的审查准确率。

同时,GuardAgent具备一定自适应性:即使工具箱中缺失部分函数,GuardAgent也能自动补写代码,确保其正常运转。此外,研究还观察到一个有趣的现象:即使没有任何明确要求代码生成,GPT-4 也在超过 68% 的案例中自发尝试生成代码作为Guardrail。

05
结语展望
作为首个针对LLM agent的guardrail,GuardAgent验证基于推理与代码生成的guardrail可以做到既灵活、又可靠。未来的研究方向包括:
●自动化工具箱生成
●更强的任务规划推理能力
●多代理协作安全机制
在LLM agent更为盛行的未来世界,GuardAgent和其衍生工作将会发挥越来越大的作用。



未经「AI科技评论」授权,严禁以任何方式在网页、论坛、社区进行转载!
公众号转载请先在「AI科技评论」后台留言取得授权,转载时需标注来源并插入本公众号名片。
未经「AI科技评论」授权,严禁以任何方式在网页、论坛、社区进行转载!
公众号转载请先在「AI科技评论」后台留言取得授权,转载时需标注来源并插入本公众号名片。

 扫码添加微信
扫码添加微信
- 点赞 0
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊







