


Meta重磅论文:Transformer或将彻底告别归一化层,一个tanh函数就够了?
- 2025-07-21 14:31:43
SHCHEGRIKOVICH
2025年7月21日
最近的AI模型领域,一个有趣的设计变动正悄然发生。
以Gemma和OLMo为代表的新模型,在层归一化的使用上另辟蹊径,选择将其应用在模块的输出端。 Peri-LN:重新审视 Transformer 架构中的归一化层
Peri-LN:重新审视 Transformer 架构中的归一化层
Peri-LN:重新审视 Transformer 架构中的归一化层
在Transformer架构中引入层归一化,其核心目标是稳定训练过程、加速模型收敛。
最初的经典Transformer架构,采用的是后置归一化,即 Post-LN 方案。
具体来说,我们可以将归一化层放在注意力或前馈模块之前,也可以放在残差连接之后。
Post-LN 的结构是 注意力/前馈 -> 残差 -> 归一化,而 Pre-LN 则是 归一化 -> 注意力/前馈 -> 残差。
经典的 Transformer 架构依赖一个训练预热阶段来确保稳定,这对模型的最终性能至关重要。
然而,这个额外的步骤不仅拖慢了训练节奏,还引入了更多需要精细调整的超参数。
可以说,预热阶段在很大程度上就是为了缓解 Post-LN 带来的梯度不问题。若没有预热,网络中间层的输出值会急剧增大,导致训练崩溃。
将 Post-LN 替换为 Pre-LN,则能有效规避这种风险,从而让训练预热变得不再必要。
然而,Gemma 和 OLMo 并未选择 Pre-LN,而是采用了一种名为 Peri-LN 的全新设计。
Peri-LN 的实现方式为 归一化 -> 注意力/前馈 -> 归一化 -> 残差。
这种设计巧妙地融合了 Post-LN 与 Pre-LN 的思想:在模块的入口和出口都进行归一化,但不在残差连接之后。
实践证明,这种方法带来了更出色的训练稳定性、更低的超参数敏感度,并显著减少了数值溢出等问题。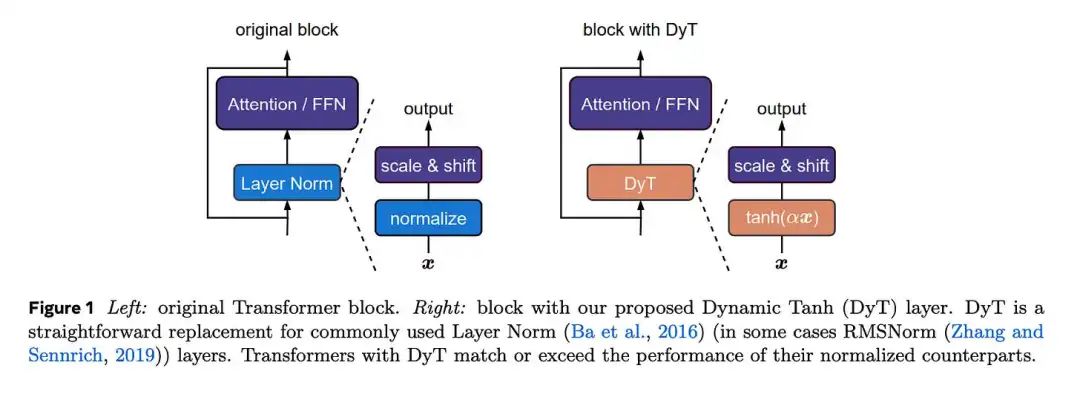
彻底告别归一化:Transformer 的新篇章
更激动人心的探索是,我们或许能彻底告别层归一化。
Meta 在其最新研究《无需归一化的 Transformer》中,公布了一项颠覆性的观察。
他们发现,在 Transformer 内部,层归一化的作用竟与一个 S 形的 tanh 激活函数高度相似,且网络越深,这种相似性越明显。
这一洞见开启了新的大门:我们可以用一个极为简单、无需统计计算的操作来替代复杂的层归一化。
层归一化需要计算整个层输出的均值和方差,而替代方案仅仅是一个 tanh 函数。
tanh 完美复刻了层归一化的核心功能——既能有效压缩极端异常值,又能在零点附近维持线性。
这意味着,我们未来或许能够摆脱繁琐的特定权重初始化和超参数调优,让模型训练变得前所未有的简洁高效。
参考文献
Paper: On Layer Normalization in the Transformer Architecture - https://arxiv.org/abs/2002.04745 Paper: Peri-LN: Revisiting Normalization Layer in the Transformer Architecture - https://arxiv.org/abs/2502.02732 Paper: Transformers without Normalization - https://arxiv.org/abs/2503.10622
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
 扫码添加微信
扫码添加微信
- 点赞 0
-
分享
微信扫一扫
-
加入群聊
扫码加入群聊





